XML——简介、语法、约束、解析
目录
- XML简介
- XML的应用
- XML语法
- XML约束
- DTD约束
- Schema约束
- XML解析
- DOM和SAX解析区别
- 解析器
XML简介
跳转到目录
- e
XtensibleMarkup Language: 可扩展标记型语言.- 标记型语言: html是标记型语言, 也就是使用标签来操作
- 可扩展: html中标签固定, 每个标签都有特定的含义. xml中的标签可以自定定义, 也可以写中文标签.
- 用途
html用于显示数据,xml也可以用于显示数据(不是主要功能)xml主要用于 存储数据.
XML的应用
跳转到目录
- 不同系统之间传输数据
- 用来表示生活中有关系的数据
常用于配置文件- 比如连接数据库, 要将数据库用户名密码存储到xml中, 以后要修改数据库信息, 不需要修改源码, 只需要修改配置文件即可.
XML的语法
跳转到目录
- xml的文档声明
- 创建一个文件,后缀名为
.xml - 文档声明:写 xml 文件时必须要有文档申明,表示为 xml 文件:
文档申明必须写在第一行第一列 - 属性:
version:xml 的版本
encoding:xml 编码,有 gbk、utf-8、iso8859-1(不包含中文)
standalone:是否需要依赖其他文件 yes/no - 乱码问题:保存时的编码要和设置打开时的编码一致,不然会出现乱码
<person> <name>张三name> <age>20age> person>
- 定义元素(标签)
- 标签定义有开始也要有结束:
- 标签没有内容,可以在标签内结束:
- 标签必须合理嵌套:
- 一个xml中,只能有一个
根标签,其他标签都是这个标签的子标签. - xml中把
空格和换行会当成内容来解析,下面代码在html中相同,在xml中不同.<age>20age> <age> 20 age>
- 定义属性
- 一个标签上可以有多个属性
person> - 属性名不能相同
- 属性名称和属性值之间用 =,属性值用引号(单引号/双引号)
- 注释
注意: 注释不能嵌套且不能放在第一行. - 特殊字符(替代符号后加
;)
| 特殊字符 | 代替符号 |
|---|---|
| < | < |
| < | > |
- CDATA区
- 解决多个字符都需要转义的操作
- 把内容放到 CDATA 里面,可以直接按 文本输出
- PI指令
- 在 xml 中设置样式
- 写法:
- 设置样式,只能对英文标签起作用,对中文不起作用
XML约束
跳转到目录
- 为什么要有约束?
在xml技术中,编写一个文档/文件来约束一个xml文档的书写规范、称为xml约束。因为没有约束 编写的xml文件格式就不统一.
DTD约束
跳转到目录
一、 编写步骤
- 创建一个文件 .dtd
- 看xml中有多少个元素, 有几个元素,就在dtd文件中写几个
- 判断元素是简单元素还是复杂元素
-复杂元素: 有子元素的元素
- 简单元素: 没有子元素
- 在xml中引入dtd文件
二、 dtd的引入方式
跳转到目录
- 引入外部dtd约束
- 内部的dtd约束
<!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> - 使用外部的dtd文件(网络上的)
- Demo
<!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> <!ATTLIST person number ID #REQUIRED> ]> <person number="p1"> <name>zhangsanname> <age>20age> person>
三、 使用dtd定义元素
-
语法:
-
简单元素:
(#PCDATA):约束 name 是字符串类型
EMPTY:约束元素为空
ANY:约束任意元素 -
复杂元素:
- 表示元素出现的次数:
+:表示一次或者多次
?:表示零次或者一次
*:表示零次或者多次 -
子元素直接使用逗号隔开
表示元素出现的顺序 -
子元素直接使用 | 隔开
表示元素只能出现其中的任意一个
- Demo
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex EMPTY>
<!ELEMENT hobby ANY>
<!ATTLIST person number ID #REQUIRED>
]>
<person number="p1">
<name>zhangsanname>
<name>zhangsanname>
<age>20age>
<sex>sex>
<hobby>basketballhobby>
person>
四、使用dtd定义属性
跳转到目录
- 语法:
- 属性类型
CDATA: 字符串
<!ATTLIST name ID1 CDATA #REQUIRED>枚举: (aa|bb|cc)
<!ATTLIST age ID2 (19|20|21) #IMPLIED>ID: 值只能是字母或者下划线开头
<!ATTLIST name ID3 ID #FIXED "n1"> - 属性的约束
#REQUIRED: 属性必须存在#IMPLIED: 属性可有可无#FIXED: 表示一个固定值.- 属性的值必须是设置的这个固定值.
直接值:- 不写属性,使用直接值
- 写了属性, 使用设置的那个值
五、定义实体
- 语法: eg:
- 使用实体:&NAME;
- 注意: 定义实体要写在内部的dtd中.
- Demo
<!ELEMENT name (#PCDATA)>
<!ATTLIST name text CDATA #REQUIRED>
<!ELEMENT age (#PCDATA)>
<!ATTLIST age a (19|20|21) #REQUIRED>
<!ELEMENT sex EMPTY>
<!ATTLIST sex s (男|女) #IMPLIED>
<!ELEMENT hobby ANY>
<!ATTLIST person number ID #REQUIRED>
<!ELEMENT learn (#PCDATA)>
<!ATTLIST learn l CDATA "s123">
<!ENTITY NAME "zy">
]>
<person number="p1">
<name text="zy">zhangsanname>
<name text="gzy">zhangsanname>
<name text="gcy">&NAME;name>
<age a="20">20age>
<sex s="男">sex>
<hobby>basketballhobby>
<learn l="s2">learn>
person>
schema约束
跳转到目录
一、概述
- schema符合xml的语法
- 一个xml中可以有多个schema, 多个schema使用名称空间区分(类似java包名)
- dtd里有有PCDATA类型, 但是在schema可以支持更多的数据类型.
- schema更加麻烦, 限制更加严格.
- 以.xsd为后缀名
二、 schema 文件里面开头有几个属性
- xmlns=“http://www.w3.org/2001/XMLSchema”
表示当前xml是一个约束文件 - targetNamespace=“http://www.sunny.com/20191229”
使用schema约束文件,直接通过这个地址引入约束文件,可以是个随意的地址 - elementFormDefault=“qualified”>
表示质量良好
三、编写步骤
-
看 xml 中有多少个元素,有多少个元素就写多少个
-
看是简单元素还是复杂元素
复杂元素:<complexType> <sequence> 子元素 sequence> complexType>简单元素:写在复杂元素
<sequence> <element name="name" type="string">element> sequence> -
在 xml 中引入 xsd 约束文件
表示该文件时被约束文件 - xmlns="http://www.sunny.com/20191229 "
是约束文件里面的 targetNamespace - xsi:schemaLocation=“http://www.sunny.com/20191229 zy.xsd”>
targetNamespace + 空格 + 约束文档的地址路径

zy.xsd约束文件
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.sunny.com/20191229"
elementFormDefault="qualified">
<element name="zy">
<complexType>
<sequence>
<element name="name" type="string">element>
<element name="age" type="int">element>
sequence>
complexType>
element>
schema>
zy.xml被约束文件
<zy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.sunny.com/20191229"
xsi:schemaLocation="http://www.sunny.com/20191229 zy.xsd">
<name>gzyname>
<age>21age>
zy>
四、复杂元素指示器
跳转到目录
:表示元素的出现顺序 :表示元素只能出现一次 :表示元素只能出现其中一个 :表示任意元素
五、约束属性
- 位置:写在复杂元素里面的 之前
- name:属性名称
- type:属性类型 int string
- use:属性是否必须出现 required
xml解析简介
跳转到目录
一、
- xml是标记型文档.
- js使用dom解析标记型文档
- 根据html的层级结构, 在内存中分配一个树形结构,把html的
标签,文本,属性都封装成对象. - document对象、element对象、属性对象、文本对象、Node节点对象.
- xml的解析技术:
DOM和SAX
- 根据html的层级结构, 在内存中分配一个树形结构,把html的
DOM和SAX解析对比
跳转到目录
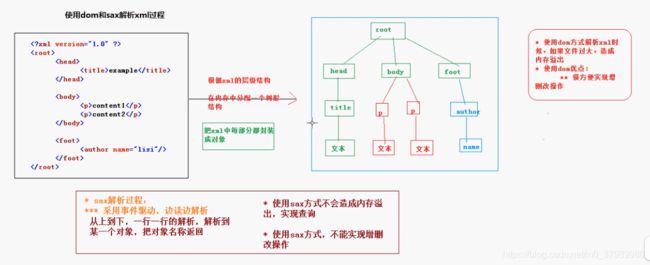
- DOM 解析:
- 根据 xml 的层级结构在内存中分配一个树形结构,
把 xml 的标签,属性和文本都封装成对象. - 优点:很方便实现增、删、改操作
- 缺点:消耗内存,会造成内存溢出
- SAX 解析
- 采用事件驱动,边读边解析
从上到下,一行一行的解析,解析到某个对象就返回对象名称 - 优点:不占内存,方便实现查询操作
- 缺点:只能读取,不能实现增、删、改操作
解析器
跳转到目录
不同的公司和组织提供了针对 DOM和 SAX 方式的解析器,都是通过 api 方式提供的,主要有:
- sun 公司提供的针对 dom 和 sax 解析器:Jaxp
- dom4j 组织提供的针对 dom 和 sax 解析器:
dom4j(开发中用的最多) - jdom 组织提供的针对 dom 和sax 解析器:Jdom
- Java的HTML解析器,可以直接解析URL地址、HTML 文本内容:
Jsoup
面试相关
问题1 XML 是什么?
答:XML 即可扩展标记语言(Extensible Markup language),你可以根据自己的需要扩展 XML。XML 中可以轻松定义, 等自定义标签,而在 HTML 等其他标记语言中必须使用预定义的标签,比如
,而不能使用用户定义的标签。使用 DTD 和 XML Schema 标准化XML 结构。XML 主要用于从一个系统到另一系统的数据传输,比如企级应用的客户端与服务端。
问题 2 :DTD 与 与 XML Schema 有什么区别?
答:DTD 与 XML Schema 有以下区别:DTD 不使用 XML 编写而 XML Schema 本身就是 xml 文件,这意味着XML解析器等已有的XML工具可以用来处理XML Schema。而且XML Schema 是设计于 DTD 之后的,它提供了更多的类型来映射 xml 文件不同的数据类型。DTD 即文档类型描述(Document Type definition)是定义 XML 文件结构的传统方式。
问题 3 :XPath 是什么?
答:XPath 是用于从 XML 文档检索元素的 XML 技术。XML 文档是结构化的,因此 XPath 可以从 XML 文件定位和检索元素、属性或值。从数据检索方面来说,XPath与 SQL 很相似,但是它有自己的语法和规则。了解更多查看怎样使用 XPath 从 XML 文档中检索数据
问题 4 :XSLT 是什么?
答:XSLT 也是常用的 XML 技术,用于将一个 XML 文件转换为另一种 XML,HTML 或者其他
的格式。XSLT 为转换 XML 文件详细定义了自己的语法,函数和操作符。通常由 XSLT 引擎完成转换,XSLT 引擎读取 XSLT 语法编写的 XML 样式表或者 XSL 文件的指令。XSLT 大量使用递归来执行转换。一个常见 XSLT 使用就是将 XML 文件中的数据作为 HTML 页面显示。XSLT 也可以很方便地把一种 XML 文件转换为另一种 XML 文档
问题 5 :什么是 XML 元素和属性
答:最好举个例子来解释。下面是简单的 XML 片断。
6758.T
2300
例子中 id 是元素的一个属性,其他元素都没有属性。
问题 6 :什么是格式良好的 XML
答:这个问题经常在电话面试中出现。一个格式良好的 XML 意味着该 XML 文档语法上是正确的,比如它有一个根元素,所有的开放标签合适地闭合,属性值必须加引号等等。如果一个 XML 不是格式良好的,那么它可能不能被各种 XML 解析器正确地处理和解析。
问题 7 :XML 命名空间是什么?它为什么很重要?
答:XML 命名空间与 Java 的 package 类似,用来避免不同来源名称相同的标签发生冲突。XML 命名空间在 XML 文档顶部使用 xmlns 属性定义,语法为 xmlns:prefix=’URI’。prefix 与XML 文档中实际标签一起使用。下面例子为 XML 命名空间的使用。
inst:number837363223
问题 8 :DOM 和 和 SAX 解析器有什么区别
答:这又是一道常见面试题,不仅出现在 XML 面试题中,在 Java 面试中也会问到。DOM 和SAX 解析器的主要区别在于它们解析 XML 文档的方式。使用 DOM 解析时,XML 文档以树形结构的形式加载到内存中,而 SAX 是事件驱动的解析器。这个问题更详细的回答查看 DOM和 SAX 解析器之间的区别。
问题 9 :XML CDATA 是什么
答:这道题很简单也很重要,但很多编程人员对它的了解并不深。CDATA 是指字符数据,它有特殊的指令被 XML 解析器解析。XML 解析器解析 XML 文档中所有的文本,比如Thisis name of person,标签的值也会被解析,因为标签值也可能包含 XML 标签,比如First Name。CDATA 部分不会被 XML 解析器解析。CDATA 部分以结束。
问题 10 :Java 的 的 XML 数据绑定是什么
答:Java 的 XML 绑定指从 XML 文件中创建类和对象,使用 Java 编程语言修改 XML 文档。XML绑定的 Java API,JAXB 提供了绑定 XML 文档和 Java 对象的便利方式。另一个可选的 XML 绑定方法是使用开源库,比如 XML Beans。Java 中 XML 绑定的一个最大的优势就是利用 Java编程能力创建和修改 XML 文档。以上的 XML 面试问答题收集自很多编程人员,但它们对于使用 XML 技术的每个人都是有用的。由于 XML 具有平台独立的特性,XPath,XSLT,XQuery 等 XML 技术越来越重要,XML广泛用于跨平台数据传输。尽管 XML 有冗余和文档体积大等缺点,但它在 web 服务以及带宽、速率作为次要考虑因素的系统间数据传输起很大作用。