先列一下大纲?
- 第一天:各种基础容器
- 第二天:实现厉害一点的结构(半咕咕)
- 第三天:非变异算法和变异算法
**那么我们就开始吧!**
## Day1
【各种基础容器】
还是先列一下小目录
- vector
- deque
- list
- queue & stack
- priority_queue
- biset
- 集合 set
- 映射 map
#### 分类
种类 | 名称
-------- | -----
序列性容器 (可以用链表模拟的那种) | vector, deque, list
关联性容器 (可以用平衡树模拟的那种) | set, map, multiset, multimap
容器适配器(可以用数组模拟的那种) | stack, queue
基本每个容器都会有的又
#### 比较常用的函数
函数名 | 函数类型 | 意义
------|----- | -----
.empty() | bool | 没有元素返回true
.size() | int | 元素个数
.max_size() | int | 最大元素个数
= | operator | 将一个容器赋给另一个容器
swap | void | 交换两个容器的元素
.begin() | iterator | 返回第一个元素
.end() | iterator | 返回最后一个元素后面的元素
.erase(xxx) | void | 清除一个元素**或几个元素**
.clear() | void | 清空所有元素
#### 头文件要求
基本上都是 ``#include <容器名>``
好啦现在分别突破!
## vector & deque & list
#### 共有的函数
小声:我一直不知道insert函数返回的那个迭代器是什么。。
知道的大佬麻烦在评论指导一下qvq感恩不尽
另外我没写构造函数因为蒟蒻一般不用。。
函数名 | 函数类型 | 意义
------|----- | -----
.insert(iterator it, const T& x) | iterator | 在it所指那个元素前加一个x元素
.insert(iterator it, int n, const T& x) | void | 在it所指那个元素前加n个x元素
.insert(iterator it, const_iterator first, const_iterator end) | void | 在it所指那个元素前加入另一个同类型容器[first, last)之间的数据
.push_back(const T& x) | void | 尾部增加元素x
.push_front(const T& x) (只有deque,list可以用) | void | 首部增加元素x
.erase(iterator it) | iterator | 删除it所指元素
.erase(iterator first, iterator last) | iterator | 删除[first, last)之间的元素
.pop_back() | void | 容器不为空时,删除最后一个元素
.pop_front() (只有deque,list可以用)| void | 容器不为空时,删除第一个元素
.front() | reference(引用)| 首元素引用
.back() | reference | 尾元素引用
.assign(int n, const T& x) | void | 设置容器大小为n每个元素为x
.assign(const_iterator first, const_iterator last) | void | 设置容器有且只有[first, last)中的元素
deque,vector貌似没有什么别的常用操作了。。
但**list**还有好多、
函数名 | 函数类型 | 意义
------|----- | -----
.remove(const T& x) | void | 删除元素值等于x的元素
.sort() | void | 排序(默认升序)
.unique() | void | 去重
.reverse() | void | 反转顺序
.splice(iterator it, list& x) | void | 将x中所有元素**移入**当前list的it元素前
.splice(iterator it, list& x, iterator first) | void | 将x中[first, end)元素**移入**当前list的it元素前
.splice(iterator it, list& x, iterator first, iterator last) | void | 将x中[first, last)元素**移入**当前list的it元素前
.merge(list& x) | void | 将x与当前list合并(不同于splice的是, 两序列若各自升序,合并完还是升序)
需要注意的是
- 对任何位置的插入和删除 list永远是常数时间
- vector容量翻倍开,容易炸哦
- vector随机位置插入删除元素比较慢
- deque随机位置操作是**线性时间**
- list随机位置插入较快 但不支持随机访问
## stack & queue & priority_queue
这个大家都跟熟悉啦~
#### 共有的函数
函数名 | 函数类型 | 意义
------|----- | -----
.push(const T& x) | void | 插入元素(队尾or栈顶)
.pop() | void | 删除元素(队尾or栈顶)
各自的
- 队首`` .front()``
- 队尾`` .back()``
- 栈顶或优先队列堆顶 ``.top()``
返回值都是reference哦
## bitset
哦天, 卡常大神器, 我爱了
它是一个二进制容器,可以看作一个巨大的二进制数
可以拿来做状压
它还有空间优化,每个元素一般只占1 bit,这是什么概念?
相当于一个char元素所占空间的八分之一
这篇博客我看了七八遍 orz胡小兔 [安利](https://www.cnblogs.com/RabbitHu/p/bitset.html)
所有的位运算可以对bitset直接操作
领养一只bitset:
bitset<位数> 名字;
#### bitset的常用函数
- 大小
``foo.size() ``返回大小(位数)
- 数1
``foo.count() ``返回1的个数
``foo.any() ``返回是否有1
``foo.none() ``返回是否没有1
- 赋值
``foo.set()`` 全都变成1
``foo.set(p)`` 将第p + 1位变成1
``foo.reset() ``全都变成0
``foo.reset(p)`` 将第p + 1位变成0
``foo.set(p, x) ``将第p + 1位变成x
- 取反
``foo.flip()`` 全都取反
``foo.flip(p)`` 将第p + 1位取反
- 转换
``foo.to_ulong()`` 返回它转换为unsigned long的结果,如果超出范围则报错
``foo.to_ullong()`` 返回它转换为unsigned long long的结果,如果超出范围则报错
``foo.to_string()`` 返回它转换为string的结果
## set & map & 它们的multi
set是集合(元素类型为Key), map是映射(元素类型为pair
#### 共有的函数
Key指key的类型, Value指value的类型
函数名 | 函数类型 | 意义
------|----- | -----
.insert(const T& x) | iterator或者pair
.insert(iterator it, const T& x) | iterator | 在it所指处插入x元素
.insert(const_iterator first, const_iterator end) | void | 插入另一个同类型容器[first, last)之间的数据
.erase(const Key& key) | size_type(这是啥?) | 删除元素值(键值)等于key的元素(multiset和multimap删除的可能不止一个!)
.erase(iterator it) | iterator | 删除it所指元素
.erase(iterator first, iterator last) | iterator | 删除[first, last)之间的元素
.lower_bound(const Key& key) | const_iterator | 返回**大于等于**key的最小元素的指针,没有则返回end()
.upper_bound(const Key& key) | const_iterator | 返回**大于**key的最小元素的指针,没有则返回end()
.count(const Key& key) | int | 返回元素值(键值)等于key的元素个数
.equal_range(const Key& key) | pair
.find(const Key& key) | const_iterator | 返回元素中等于key的迭代器指针
okk 今天就到这里吧 每天update哦~
最后安利一个比STL还STL noip还可以用!的[东西](https://baijiahao.baidu.com/s?id=1610302746201562113&wfr=spider&for=pc)
## Day2
- vector代替平衡树
luogu3369普通平衡树的代码
亲测
加上头文件一共26行
```cpp
#include
#include
#include
#include
#include
#include
using namespace std;
int n;
vector
int main() {
int x, opt;
scanf("%d", &n);
for(int i = 1; i <= n; ++i){
scanf("%d%d", &opt, &x);
int pos = lower_bound(tree.begin(), tree.end(), x) - tree.begin();
switch(opt){
case 1: tree.insert(tree.begin() + pos, x); break;
case 2: tree.erase(tree.begin() + pos, tree.begin() + pos + 1); break;
case 3: printf("%d\n", pos + 1); break;
case 4: printf("%d\n", tree[x - 1]); break;//注意这里是x-1哦
case 5: printf("%d\n", tree[pos - 1]); break;
case 6: printf("%d\n", *upper_bound(tree.begin(), tree.end(), x)); break;
}
}
return 0;
}
```
但是有这么个小问题
这些容器 好像都维护不了区间和欸。。
又切了几道题 就算Day2吧
### pbds的平衡树
这里仅陈列pbds平衡树常用用法
参考[博客]()
包含:ext/pb_ds/assoc_container.hpp和ext/pb_ds/tree_policy.hpp
声明:__gnu_pbds::tree
typename Key , typename Mapped ,
typename Cmp_Fn = std :: less
typename Tag = rb_tree_tag ,
template <
typename Const_Node_Iterator ,
typename Node_Iterator ,
typename Cmp_Fn_ , typename Allocator_ >
class Node_Update = null_tree_node_update ,
typename Allocator = std :: allocator
class tree ;
注:如果有第二优先排序的话,用pair(先拍first)
过于常见:
- .begin()
- .end()
- .size()
- .empty()
- .clear()
常见:
- .begin() 最小值
- .end() 最大值后一位
- .find_by_order(val)返回迭代器 第val个数
- .order_of_key(val) 返回值 比他小的数有多少个
- .find(const Key)
- .lower_bound(const Key) 返回迭代器
- .upper_bound(const Key)返回迭代器
- .erase(iterator)
- .erase(const Key)
- .insert(const pair<> )
- .operator[]
- void join(tree &other) 把other中所有元素移动到*this上(值域不能相交,否则抛出异常。
- void split(const_key_reference r_key, tree &other) 清空other,然后把*this中所有大于r_key的元素移动到other。
- get_l_child和get_r_child 左右儿子
自定义update:
```cpp
template < class Node_CItr , class Node_Itr ,
class Cmp_Fn , class _Alloc >
struct my_node_update {
virtual Node_CItr node_begin () const = 0;
virtual Node_CItr node_end () const = 0;
typedef int metadata_type ;
inline void operator ()( Node_Itr it , Node_CItr end_it ){
Node_Itr l = it. get_l_child (), r = it. get_r_child ();
int left = 0, right = 0;
if(l != end_it ) left = l. get_metadata ();
if(r != end_it ) right = r. get_metadata ();
const_cast < metadata_type &>( it. get_metadata ())
= left + right + (* it)-> second ;
}
inline int prefix_sum (int x) {
int ans = 0;
Node_CItr it = node_begin ();
while (it != node_end ()) {
Node_CItr l = it. get_l_child (), r = it. get_r_child ();
if( Cmp_Fn ()(x, (* it)-> first )) it = l;
else {
ans += (* it)-> second ;
if(l != node_end ()) ans += l. get_metadata ();
it = r;
}
}
return ans;
}
inline int interval_sum (int l, int r){
return prefix_sum (r) - prefix_sum (l - 1);
}
}
int main() {
tree
T [2] = 100; T [3] = 1000; T [4] = 10000;
printf ("%d\n", T. interval_sum (3, 4));
printf ("%d\n", T. prefix_sum (3));
}
```
## Day3
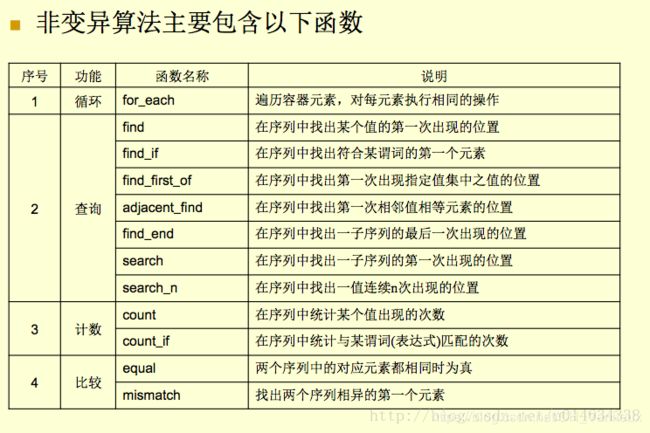
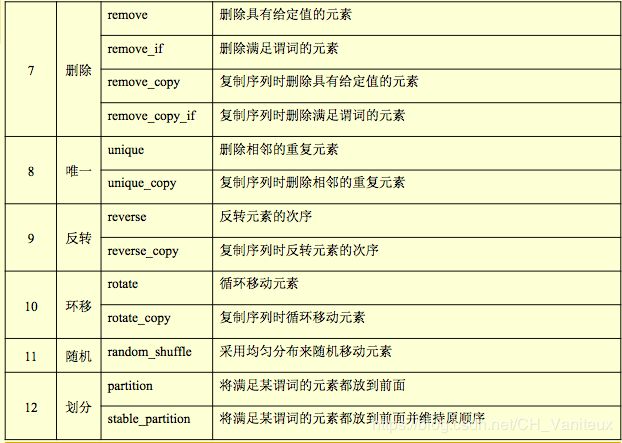
#### 非变异算法与变异算法
分为循环,查询,计数,比较四类
复杂度是线性的,感觉用不太上,简单看看就好啦。。
[转自](https://blog.csdn.net/u014634338/article/details/38095803)