使用 webMagic 注解爬取网页数据
不久前使用 webMagic开发了一款爬虫
爬取对象为四川政务网,使用JFinal持久化数据
如果你正在学习爬虫,或者业务与我类似,那么你可以下载源码学习
也可向我提出改进意见
参考源码:在这里
列表页:
http://www.sczwfw.gov.cn/app/index?flag=2&areaCode=510000000000
抓取页:
http://www.sczwfw.gov.cn/app/scworkguide/detail?id=3952148991995600896&shardKey=5100
简单讲下系统设计,具体的请参考代码
目录结构

entity 网页字段对应的实体类
main 爬虫入口
utils 工具类
Admin : 对所有提取到的数据进行集中管理
UrlCache: 网页缓存的抽象
生命周期
如图所示,保存数据只是附属的流程

链接发现
这是爬虫的开始,对链接进行发现和更新
例如:已经抓取了500个成都的事项,但是现在需要更新500个事项为其他地区的
按照生命周期,你需要在这里重新更新链接
在这一步,我们需要确认要抓取的网页是哪些,并观察网页是否有对外暴露的查询接口,经过调试,找到了这个接口:
http://mss.sczwfw.gov.cn/app/powerDutyList/getThImplement他支持的参数:
eventNam: 事项名称
areaCode : 区域码
eventType : 行政类型
打开PostMan测试接口,并查看返回参数:

它返回了事项的基本信息,其中还有父级事项的名称
循环调用这个接口,然后将其返回的数据进行保存,具体请参考utils包下的InsertItems类,看我如何抽离数据
将其保存至数据库

OOSpider
当数据准备就绪,需要使用OOSpider类进行网页数据抓取
OOSpider是注解式爬虫的入口,有这些方法

方法
getCollectorPipeline() : 看了下源码,这个和AfterExtractor接口的功能一样,都是在运行时返回数据抽取结果。建议使用AfterExtractor接口,面向接口编程嘛
两个create方法: 对构造方法的简单封装,因为构造方法是protected!
addPageModel(): 文档
setIsExtractLinks(): 是否提取网页链接
这个需要搭配TargetUrl与HelpUrl注解使用,本质就是链接发现.我们已经发现过了,所以设置为false
具体的你可以看ModelPageProcessor源码
TargetUrl和HelpUrl注解文档入参
ModelPageProcessor : 注解网页对象 在网页抓取章节里详解介绍
PageProcessor: 普通网页对象 这个是给传统方式使用的,看 这里
Site : http请求对象 , http嘛肯定是配置cookies、header、超时时间、重试次数等等...乱七八糟参数的地方
PageModelPipeline : 看 文档
网页抓取
下面我分成两个部分讲述
1. 创建OOSpider时 发生了什么
2.如何设计映射关系(实体类)
先看一段代码:
public class GithubRepo {
@ExtractBy("//div[@id='readme']/tidyText()")
private String readme;
public static void main(String[] args) {
OOSpider.create(Site.me().setSleepTime(1000)
, GithubRepo.class)
.addUrl("https://github.com/code4craft").thread(5).run();
}
}
这段代码描述了:
1 . GithubRepo 拥有的字段readme 被@ExtractBy 注释,它的抽取规则为//div[@id='readme']/tidyText()
2.创建一个爬虫 OOSpider.create()
3. 爬虫传入了两个类 : Site类 和 拥有抽取规则的类
4.使用addUrl(),规定了抓取的页面
5.创建线程并运行
代码内部过程:
1.将Url pull 到 Scheduler 接口
2.初始化组件:
创建HttpClient、创建线程池、通过Scheduler获取Request集合
3.请求页面
4.抽取数据 ,被@ExtractBy注释的字段都会被PageModelExtractor类,注入对应数据
5.存放数据
存放的数据有二种方式获取
一。Pipeline 接口 可在线程运行和结束时可获取数据
二。AfterExtractor接口 单个线程结束时 可获取数据,我使用这种方式保存数据
回到我们代码本身,肯定不能将需要抓取的字段和接口实现放置到一起,但是数据要统一管理
Admin类正是为此而设计

它继承了拥有@ExtractBy注解的实体类,同时要求实现类需要实现AfterExtractor类的方法
Laws类图:
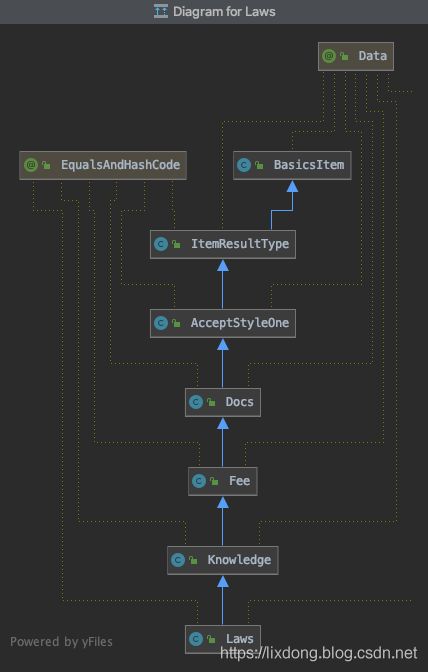
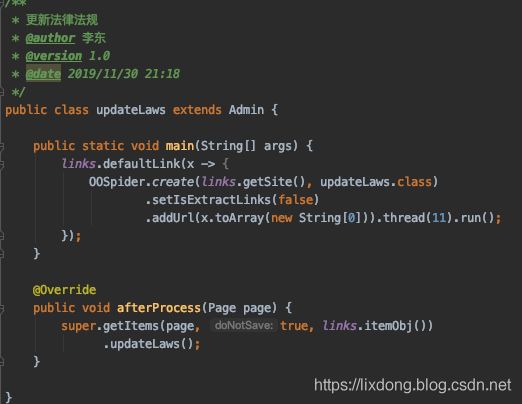
在程序入口,需要继承Admin类,实现afterProcess方法
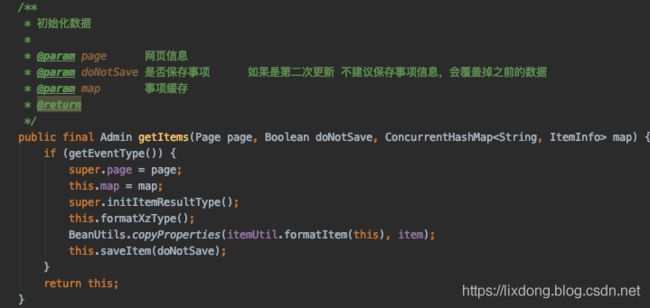
数据拼装
实现afterProcess方法后,为我们传过来一个Page对象,这里面的数据为:实体类@ExtractBy规则抓取的数据
当拿到数据后,就可以按照你自己的业务,进行处理了,比如像这样
感想
随着业务的增加,势必需要监控爬虫,实现前后端交互
现在有两种监控方式
一.通过JConsole

二 继承 SpiderStatusMXBean
这个还是比较不错的,可以取到错误网页 还支持启动和停止
