AutoML全面解析@Qing
对Google的AutoML全面解析
- 1.AutoML简介
- 1.1 AutoML自动编程框架简介
- 1.2 AutoML产品定位
- 1.3 AutoML关键技术
- 2.AutoML应用现状
- 2.1 AutoML应用举例
- 2.2 AutoML评价
- 3.AutoML技术实现
- 3.1 AutoML原理说明
- 3.2 AutoML技术细节
- 3.3 AutoML最新技术
1.AutoML简介
1.1 AutoML自动编程框架简介
- 2017 年 5 月,谷歌大脑研究人员宣布创建了AutoML,该 AI 系统能够创造自己的 AI 系统。最近,他们决定让 AutoML
攻克迄今为止对它来说最大的挑战,令人惊讶的是,AutoML 创造了一个非常厉害的「后代」,它的表现甚至超过了所有人类设计的 AI 系统。 - 为了实现机器学习模型的设计自动化,谷歌研究者采用了增强学习的方法。AutoML 作为神经网络控制器,为一个特定任务开发子代 AI 网络。这个被研究人员称为 NASNet(Neural Architecture Search technology) 的子代 AI的任务是在视频中实时地识别物体,包括人、汽车、交通灯、手袋、背包等。
引自百度百科
目前AutoML包括三个工具分别是:AutoML Vision(视觉领域),自然语言处理领域和翻译领域。
1.2 AutoML产品定位
(1)AuotoML要实现的目标:
- 目前,设计神经网络非常费时,并且需要专家只在科学和工程领域中的一小部分进行研究。为了解决这一问题,我们创造了一种名为AutoML的工具,有了它,神经网络可以设计神经网络。我们希望AutoML能做到目前博士们可以达到的水平,三至五年之后,我们希望它能为众多开发者设计不同功能的新的神经网络。
引自 谷歌CEO Sundar Pichai
(2)AuotoML产品特点及优势
- 我很荣幸地宣布AutoML Vision面世。这是一款能让每个人都有能力构建机器学习模型,却无需机器学习经验的产品。这是“人工智能民主化”的重要进展!也是令人振奋的团队合作结果。”
谷歌云负责人、首席科学家 李飞飞
- 三点优势:一是即使用户的机器学习专业知识有限,也可以获得更准确的模型。二是能更快速的建立模型,用户可以在几分钟内或者在一天内构建完整的能用的模型。三是易于使用,用户操作的界面简洁清晰。
(3)Google的经济动机
- 谷歌之所以一直强调高效使用深度学习的关键是更多的计算力,是因为这与它的利益相关,因为在计算力这个方面,谷歌足以吊打其他人。如果这是真的,那我们可能都需要购买谷歌的产品了。就其本身而言,这并不意味着谷歌的说法是错误的,但是我们最好意识到他们言论之下的经济动机。
引自 论智 Rachel Thomas
1.3 AutoML关键技术
- “我们的方法(AutoML)中,一个控制器神经网络可以生成一个子模型架构……”
引自 谷歌AI的研究者 Barret Zoph和Quoc Le
(1)AutoML Vision简介
-
AutoML Vision是一款提供自定义图像识别系统自动开发的服务。用户只需要将自己的数据上传,就可以直接在谷歌云上训练和管理模型。也就是说,即使是没有机器学习专业知识的的人,只需了解模型基本概念,就能借这项服务轻松搭建定制化的图像识别模型。
-
对AutoML Vision简单介绍如下:(https://cloud.google.com/vision/)


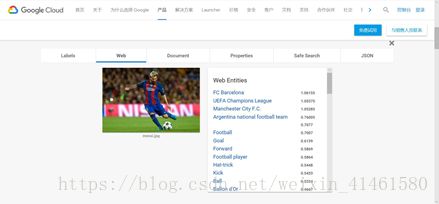
(1)AutoML Vision关键技术
-
AutoML Vision依靠两种核心技术:迁移学习和神经架构搜索。
-
关键技术1:迁移学习
-
迁移学习利用预训练模型,可以让人们用少量数据集或者较少的计算力得到顶尖的结果,是一种非常强大的技术。预训练模型此前会在相似的、更大的数据集上进行训练。由于模型无需从零开始学习,它可以比那些用更少数据和计算时间的模型得到更精确的结果。
- 关键技术2:NAS(Neural Architecture Search)
- NAS也就是Neural Architecture
Search,目标是从一堆神经网络组件中,搜索到一个好的神经网络模型。我们知道神经网络模型是一种可任意堆砌的模型结构,基础的组件包括FC(全连接层)、Convolution(卷积层)、Polling(池化层)、Activation(激活函数)等,后一个组件可以以前一个组件作为输入,不同的组件连接方式和超参配置方式在不同应用场景有不同的效果。
-
神经架构搜索和迁移学习比较:
-
迁移学习之下的基础理念是,神经网络结构会对相同种类的问题进行泛化:例如,很多图片都有基础特征(比如角度、圆圈、狗狗的脸、车轮等等),这些特征构成了图片的多样性。相反,提升神经架构搜索的效率是因为,每个数据集都是独一无二的,它的结构非常个性化。

-
当神经架构搜索发现了一种新结构,你必须从零开始学习该结构的权重。但是有了迁移学习,你可以从预训练模型上已有的权重开始训练。这也意味着你无法在同一个问题上同时使用迁移学习和神经架构搜索:如果你要学习一种新的结构,你可能需要为此训练一个新权重;但如果你用迁移学习,可能无需对结构进行实质性改变。
-
AutoML由控制器(Controller)和子网络(Child)2个神经网络组成,控制器生成子模型架构,子模型架构执行特定的任务训练并评估模型的优劣反馈给控制器,控制器将会将此结果作为下一个循环修改的参考。重复执行数千次“设计新架构、评估、回馈、学习”的循环后,控制器能设计出最准确的模型架构。
2.AutoML应用现状
2.1 AutoML应用举例
- 迪士尼已通过AutoML建立图片分类模型,依据角色、种类和颜色等分类标示产品,并导入搜寻的功能中,让消费者搜寻商品更加方便且准确。
- 美国流行服装零售商Urban Outfitters也通过AutoML来分类商品。
2.2 AutoML评价
(1)正面评价
-
Google’s AI can create better machine-learning code than the
researchers who made it.AutoML is better at coding machine-learning systems than the
researchers who made it. In an image recognition task it reached
record a high 82 percent accuracy. Even in some of the most complex
AI tasks, its self-created code is superior to humans; it can mark
multiple points within an image with 42 percent accuracy compared to
human-made software’s 39.Tristan Greene
-
Google’s machine learning software has learned to replicate itself.
Artificial intelligence (AI) designed to help them create other AIs.
Futurism
(2)负面评价:
- 谷歌的AutoML真实反映了一些学术研究机构掺杂了盈利机构之后的危机。很多科学家都想创建有关热门学术研究领域的产品,但并不评估它能否满足实际需求。这也是很多AI创企的现状,我的建议是不要试图将博士论文变成产品,并且尽量不要雇佣纯学术研究人员。
- 谷歌很擅长营销。人工智能对很多门外汉来说门槛较高,以至于他们没办法评估某种主张,尤其是谷歌这样的巨头。很多记者也随波逐流,争相报道谷歌的新技术、新成果。我经常跟哪些不在机器学习界工作的人谈论谷歌的成果,他们即使没有用过谷歌机器学习产品,但表现得也很兴奋,可是如果仔细深究又讲不出个所以然来。
- 谷歌造成的新闻误导其中一个案例是谷歌AI研究人员宣布“他们创建了一种深度学习技术,能够重建人类基因组”,并且他们还将这项技术与诺贝尔获胜者做了对比,Wired对此进行了报道。在这之后,约翰霍普金斯大学生物统计学家、生物工程教授Steven
Salzberg就批判了谷歌的这篇文章。Salzberg指出,这项研究实际上并没有重建人类基因组,而且“在现有软件上仅有微小提升,甚至还不如现有软件”。其他很多基因研究者对Salzberg的说法表示了赞同。
论智 Rachel Thomas
(3)相对客观评价
- 绝大部分机器学习都不是人工智能,计算机不会无缘无故获得既定目标以外的能力。因此,计算机并不是自己学会编程或者建模,我们还没有设计出自动建模的数据集和算法,所谓的“AI设计神经网络模型”,其实只是在给定的搜索空间中查找效果最优的模型结构。
引自 https://zhuanlan.zhihu.com/p/35339663
3.AutoML技术实现
3.1 AutoML原理说明
(1)算法核心:让神经网络训练神经网络。
(2)实现原理:一种控制器神经网络(RNN)提议一个“子”模型框架,然后对特定任务进行训练和质量评估;根据反馈给控制器的信息改进下一轮的提议。重复这个过程上千次从而生成新的架构。最终测试和反馈让控制器学习的好架构被控制器分配高的概率,以便在验证数据集上得到更高的准确性且架构空间的差异更小。
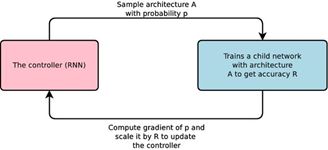
(3)实现原理:(与上述类似)
- The system runs thousands of simulations to determine which areas of
the code can be improved, makes the changes, and continues the
process ad infinitum, or until its goal is reached.
Tristan Greene
(4)原理解释:
- This is a fabulous representation of the infinite monkey
theorum(无限猴理论), but instead of a monkey with a keyboard creating
Shakespeare, Google made machines capable of replicating their own
programming. And those machines can do in hours what takes the best
human programmers weeks or months.
Tristan Greene
3.2 AutoML技术细节
(1)常见机器学习模型实现的步骤:
对模型进行经验调参的步骤:数据与处理-特征选择-模型算法选择-调参-上线后优化-效果评估。
(2)AutoML主要功能及设计方法:
主要功能:一是模型/算法选择,二是模型超参数优化。
- 涉及到的方法:贝叶斯优化;结构化数据和超大数据的逻辑回归;元学习;迁移学习;组合优化。
引自 知乎 Frankie Gu (https://zhuanlan.zhihu.com/p/27792859)
- 元学习的热启动:在机器学习框架中寻找效果好的算法;计算不同数据集之间的相似度,相似的数据可以采取类似的超参数。
- 超参数优化,算法包括:Hyperopt(TPE 算法);SMAC(基于随机森林);Spearmint。输入不同的超参数为,以损失函数为准确率,调优器会在随机选择一些值的基础上,利用贪心算法去寻优。
3.3 AutoML最新技术
-
ENAS: 更有效地设计神经网络模型(AutoML):ENAS全称Efficient Neural Architecture Search,出自Google在2018年发布的论文《Efficient Neural Architecture Search via Parameter Sharing》,通过共享模型参数的形式高效实现神经网络模型结构的探索。
-
使用的关键技术:强化学习、动态构建计算图等技术,从宏观角度看是一种搜索算法,产出是一个精心挑选的NN模型,因此这是一种很符合期望的AutoML,同时实现完整的“自动(Auto)机器学习(ML)”还需要有自动特征抽取、自动超参调优等技术支持。
(1)NAS举例说明
-
假设模型必须是一个三层的全连接神经网络(一个输入层、一个隐层、一个输出层),隐层可以有不同的激活函数和节点个数,假设激活函数必须是relu或sigmoid中的一种,而隐节点数必须是10、20、30中的一个,那么我们称这个网络结构的搜索空间就是{relu, sigmoid} * {10, 20 ,30}。在搜索空间中可以组合出6种可能的模型结构,在可枚举的搜索空间内我们可以分别实现这6种可能的模型结构,最终目标是产出效果最优的模型,那么我们可以分别训练这6个模型并以AUC、正确率等指标来评价模型,然后返回或者叫生成一个最优的神经网络模型结构。
-
NAS算法是一种给定模型结构搜索空间的搜索算法,当然这个搜索空间不可能只有几个参数组合,在ENAS的示例搜索空间大概就有 1.6*10^29种可选结构,而搜索算法也不可能通过枚举模型结构分别训练来解决,而需要一种更有效的启发式的搜索算法,这种算法就是贝叶斯优化、增强学习、进化算法等.
(2)超参自动调优算法:贝叶斯优化
- NAS是一种搜索算法,是从超大规模的搜索空间找到一个模型效果很好的模型结构,这类问题我们也可以看作一个优化问题,也就是从搜索空间中找到另一个模型效果更优的模型结构。这类问题看作一类黑盒优化(Black-box optimization)问题,对于黑盒优化问题的解法可以参考贝叶斯优化(https://zhuanlan.zhihu.com/p/29779000)。
(3)搜索空间的获取:
- 定义一个搜索空间来让算法选择更优的网络结构,而这个搜索空间无外乎就是网络层个数、网络层的类型、网络层的激活函数类型、网络层是否加Dropout、网络层是否加Batch normalization,还有就是诸如卷积层的filter size、strip、padding和池化层的polling type、kernel size等等,这些我们都可以认为是神经网络的超参数。使用tensorflow_tempalate_application我们可以通过传入的参数–model={dnn,
lr, wide_and_deep, cnn}来选择更好的模型结构,也可以通过参数–optimizer={sgd,
adadelta, adagrad, adam, ftrl, rmsprop}来选择更好的优化算法。
(4)网络空间的搜索方法
-
暴力枚举法(排除);贝叶斯优化(Bayesian optimization)、粒子群优化(Particle swarm optimization)、Policy
gradient、DQN等等,这些算法都可以用于NAS内部的模型的优化。是的,NAS内部也有一个模型,一般在论文或者代码中称为controller模型,又它来控制想要生成的神经网络模型的结构,而生成的神经网络模型会根据客户的使用场景(例如图像分类)来返回模型效果对应的指标,这个一般称为child模型。 -
NAS没有学会建模也不能替代算法科学家设计出Inception这样复杂的神经网络结构,但它可以用启发式的算法来进行大量计算,只要人类给出网络结构的搜索空间,它就可以比人更快更准地找到效果好的模型结构。
-
ENAS需要人类给出生成的网络模型的节点数,我们也可以理解为层数,也就是说人类让ENAS设计一个复杂的神经网络结构,但如果人类说只有10层那ENAS是不可能产出一个超过10层网络结构,更加不可能凭空产生一个ResNet或者Inception。
-
如下图:ENAS要学习和挑选的就是Node之间的连线关系,通过不同的连线就会产生大量的神经网络模型结构,从中选择最优的连线相当于“设计”了新的神经网络模型。
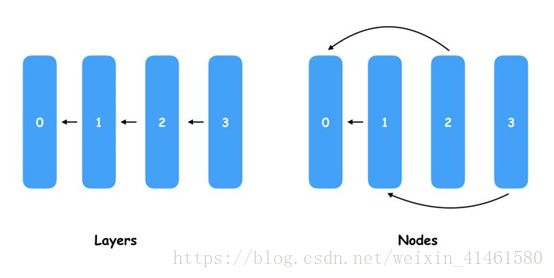
- TensorFlow表示了Tensor数据的流向,而流向的蓝图就是用户用Python代码定义的计算图(Graph),如果我们要实现上图中所有Layer连成一条直线的模型,我们就需要在代码中指定多个Layer,然后以此把输入和输出连接起来,这样就可以训练一个模型的权重了。当我们把上图中所有Layer连成一条直线的模型改成右边交叉连线的模型,显然两者是不同的Graph,而前一个导出模型权重的checkpint是无法导入到后一个模型中的,但直观上看这几个节点位置本没有变,如果输入和输出的Tensor的shape不变,这些节点的权重个数是一样的,也就是说左边Node0、Node1、Node2、Node3的权重是可以完全复制到右边对应的节点的。这也就是ENAS实现权重共享的原理,首先会定义数量固定的Node,然后通过一组参数去控制每个节点连接的前置节点索引,这组参数就是我们最终要挑选出来的,因为有了它就可以表示一个固定神经网络结构,只要用前面提到的优化算法如贝叶斯优化、DQN来调优选择最好的这组参数就可以了。这里评估模型是指各组模型用相同的一组权重,各自在未被训练的验证集中做一次Inference,最终选择AUC或者正确率最好的模型结构,其实也就是选择节点的连线方式或者是表示连线方式的一组参数。稍微总结一下,因为ENAS生成的所有模型节点数是一样的,而且节点的输入和输出都是一样的,因此所有模型的所有节点的所有权重都是可以加载来使用的,因此我们只需要训练一次模型得到权重后,让各个模型都去在验证集做一个预估,只要效果好的说明发现了更好的模型了。实际上这个过程会进行很多次,而这组共享的权重也会在一段时间后更新,例如我找个一个更好的模型结构了,就可以用这个接口来训练更新权重,然后看有没有其他模型结构在使用这组权重后能在验证机有更好的表现。
引自 论文 Efficient Neural Architecture Search via Parameter Sharing
总结:NAS其实原理很简单,首先在一定空间内搜索,问题优化上使用了贝叶斯优化、增强学习等黑盒优化算法、在样本生成上使用了权值共享、多模型Inference的方式、在编码实现用了编写一个Graph来动态生成Graph的高级技巧。