飞桨综合大作业心得
1. 中文字体下载不成功

需要从别处下载,然后上传:
https://www.uslogger.com/details/3
http://www.font5.com.cn/font_download.php?id=151&part=1237887120
2. 柱状图不显示中文
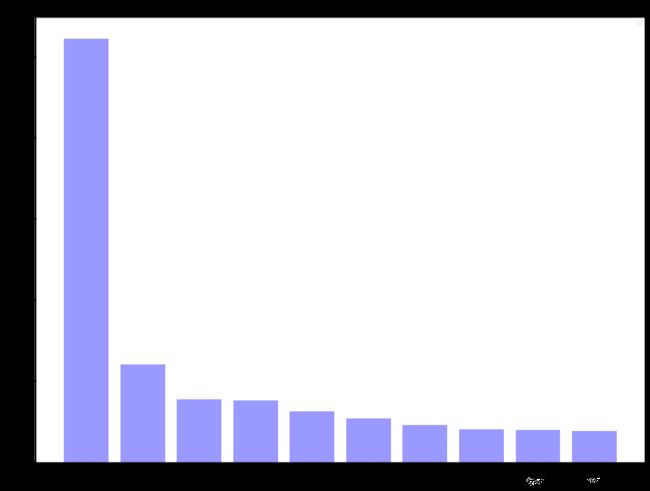
原因:
1) 没有安装中文字体,详细内容见上面1
2) 安装了中文字体,但是没有复制到matplotlib下面
#1 将字体文件复制到matplotlib字体路径
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
#2 一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用
# !cp simhei.ttf /usr/share/fonts/
#3 创建系统字体文件路径
!mkdir .fonts
# 复制文件到该路径
!cp simhei.ttf .fonts/
#4
!rm -rf .cache/matplotlib3) 设置matplotlib.rcParams
plt.rcParams['font.sans-serif'] = ['SimHei']4) for mac:安装好以后需要使用rm -r ~/.matplotlib 删除~/.matplotlib文件
5) 查看系统可用的ttf格式中文字体
!fc-list :lang=zh | grep ".ttf"
/home/aistudio/.fonts/simhei.ttf: SimHei,黑体:style=Regular,Normal,obyčejné,Standard,Κανονικά,Normaali,Normál,Normale,Standaard,Normalny,Обычный,Normálne,Navadno,Arrunta可知如果设置了:
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/simhei.ttf或
.fonts/simhei.ttf最终使用.fonts/simhei.ttf
6)设置好后,如果不起作用,需要重新进入AIStudio
3. 爬去爱奇艺comments,找不到comments路径
F12,network,找到get_comments.atcion
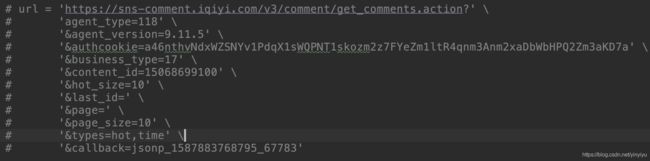
jsonp_xxx后面是随机生成的,通过callback参数传给后端然后你会看到后端会返回jsonp_xxx()这相当于调用了一个方法,这个方法会处理返回的data,而zh’ge方法前端这边已经生成了,也叫做回调,具体的可以百度jsonp解决跨域问题了解下。所以在爬数据时就不需要带上callback参数了,这个参数是跟后端说等下返回后回调的方法名。
最后需要的url:
url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?" \
"agent_type=118" \
"&agent_version=9.11.5" \
"&authcookie=null" \
"&business_type=17" \
"&content_id=15068748500" \
"&hot_size=0" \
"&last_id="如果需要一次显示更多项comments,可以把page_size加上,但单页加载量不能超过40个,否则会有如下错误
4. 本地跑时,matplotlib出现如下错误
Traceback (most recent call last):
File "/home/xxx/python_workspace/spider/day5.py", line 234, in
text_detection(text_path, file_path)
File "/home/xxx/python_workspace/spider/day5.py", line 200, in text_detection
if item.get('porn_detection_key') == 'porn':
AttributeError: 'str' object has no attribute 'get'
Exception ignored in: >
Traceback (most recent call last):
File "/usr/lib64/python3.6/tkinter/__init__.py", line 3507, in __del__
self.tk.call('image', 'delete', self.name)
RuntimeError: main thread is not in main loop
Tcl_AsyncDelete: async handler deleted by the wrong thread 将
import matplotlib.pyplot as plt改为:
import matplotlib
matplotlib.use('Agg')
from matplotlib import pyplot as plt 即可
5. paddlehub和paddlepaddle版本问题
aistudio@jupyter-283626-433635:~$ pip list|grep paddlehub
paddlehub 1.6.1
aistudio@jupyter-283626-433635:~$ pip list|grep paddlepaddle
paddlepaddle 1.7.1 # !pip install --upgrade paddlehub
# !pip install --upgrade paddlepaddle
# !pip list |grep paddlehub
# !pip list |grep paddlepaddle
6. 完整代码:
# coding: utf-8 -*-
from __future__ import print_function
import requests
import json
import re # 正则匹配
import time # 时间处理模块
import jieba # 中文分词
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
from PIL import Image
from wordcloud import WordCloud # 绘制词云模块
import paddlehub as hub
# 请求爱奇艺评论接口,返回response信息
def get_movie_info(url):
"""
请求爱奇艺评论接口,返回response信息
:param url: 评论的url
:return: response信息
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' # noqa
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
# 解析json数据,获取评论
def save_movie_info_to_file(last_id, contents):
"""
解析json数据,获取评论
:param last_id: 最后一条评论ID
:param contents: 存放文本的list
:return: last_id
"""
url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?" \
"agent_type=118" \
"&agent_version=9.11.5" \
"&authcookie=null" \
"&business_type=17" \
"&content_id=15068748500" \
"&hot_size=0" \
"&last_id="
url += str(last_id)
response_text = get_movie_info(url)
response_json = json.loads(response_text)
comments = response_json.get('data').get('comments')
for comment in comments:
content = comment.get('content')
if content:
contents.append(content)
last_id = str(comment.get('id'))
return last_id
# 去除文本中特殊字符
def clear_special_char(content):
"""
正则处理特殊字符
:param content: 原文本
:return: 清除后的文本
"""
s = re.sub(r'| |\t|\r', '', content) #去掉<>, , tab, 换行
s = re.sub(r'\n', " ", s) # 去掉回车换行
s = re.sub(r'\*', '\\*', s) #正确显示转义字符
s = re.sub('[^\u4e00-\u9fa5a-zA-Z0-9]','',s) # \u4e00-\u9fa5 汉字的unicode范围
s = re.sub('[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+', '', s) # 去除不可见字符 noqa
s = re.sub('[a-zA-Z]', '', s) # 去掉字母
s = re.sub('^\d+(\.\d+)?$', '', s) # 去掉纯数字
return s
def fenci(text):
"""
利用jieba进行分词
:param text: 需要分词的句子或文本
:return: 分词结果
"""
jieba.load_userdict('add_words.txt') # 添加自定义字典
seg = jieba.lcut(text, cut_all=False)
return seg
def stop_words_list(file_path):
"""
创建停用词表
:param file_path: 停用词文本路径
:return: 停用词list
"""
stop_words = [line.strip()
for line in open(file_path, 'r').readline()]
new_stop_words = ['哦', '因此', '不然', '也好', '但是', '欣虞书']
stop_words.extend(new_stop_words)
return stop_words
def move_stop_words(sentence, stop_words, counts):
"""
去除停用词,统计词频
:param sentence: 停用词文本路径
:param stop_words: 停用词list
:param counts: 词频统计结果
:return: None
"""
for word in sentence:
if word not in stop_words:
if len(word) != 1:
counts[word] = counts.get(word, 0) + 1
return None
def draw_counts(counts, num):
"""
绘制词频统计表
:param counts: 词频统计结果
:param num: 绘制topN
:return: None
"""
x_aixs = []
y_aixs = []
c_order = sorted(counts.items(), key=lambda x: x[1], reverse=True)
for item in c_order[:num]:
x_aixs.append(item[0])
y_aixs.append(item[1])
# 设置显示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示字符
plt.figure(figsize=(20, 15))
plt.bar(
range(len(y_aixs)),
y_aixs,color='r',
tick_label=x_aixs,
facecolor='#9999ff',
edgecolor='white'
)
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45, fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《青春有你2》高频评论词统计''', fontsize=24)
plt.savefig('high_words.jpg')
plt.show()
def draw_cloud(word_f):
"""
根据词频绘制词云图
:param word_f: 统计出的词频结果
:return: None
"""
# 加载背景图片
cloud_mask = np.array(Image.open('/home/xxx/python_workspace/spider/humanseg_output/5.jpg'))
# 忽略显示的词
st = {'不是', '还是', '什么', '那么', '怎么', '就是', '没有'}
font = r'/home/xxx/python_workspace/spider/.fonts/SimHei.ttf'
# 生成wordcloud对象
wc = WordCloud(
font_path=font,
background_color='white',
margin=5,
mask=cloud_mask,
max_words=200,
min_font_size=10,
max_font_size=100,
width=800,
height=600,
relative_scaling=0.3,
random_state=20,
stopwords=st
)
# wc.fit_words(word_f) # 这种方式也可以
wc.generate_from_frequencies(word_f)
# 显示生成的词云
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('pic.png')
def text_detection(text_path, file_path):
"""
使用hub对评论进行内容分析
:param text_path: 分析结果文件路径
:param file_path: 分析原始文件路径
:return: 分析结果
"""
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
comment_text = [line.strip() for line in open(file_path).readlines()]
input_dict = {'text': comment_text}
result = porn_detection_lstm.detection(data=input_dict, use_gpu=False, batch_size=1)
print(result)
with open(text_path, 'w') as fn:
for index, item in enumerate(result):
if item.get('porn_detection_key') == 'porn':
fn.write(item.get('text') + ": " + str(item.get('porn_probs')) + "\n")
print(item.get('text'), ": ", item.get('porn_probs'))
if __name__ == '__main__':
num = 40
last_id = '0'
contents = []
with open('sqy.txt', 'a') as fn:
for i in range(num):
last_id = save_movie_info_to_file(last_id, contents)
time.sleep(0.5)
for content in contents:
item = clear_special_char(content)
if item.strip():
try:
fn.write(item + '\n')
except Exception as e:
print('含有特殊字符')
print('共爬取评论: {}'.format(len(contents)))
with open('sqy.txt', 'r') as fn:
counts = {}
for line in fn:
words = fenci(line)
stop_words = stop_words_list('add_stopwords.txt')
move_stop_words(words, stop_words, counts)
draw_counts(counts, 10) # 绘制top10 高频词
draw_cloud(counts) # 绘制词云图
# 使用hub对评论过行内部分析
file_path = 'sqy.txt'
text_path = 'result.txt'
text_detection(text_path, file_path)
Image.open('pic.png') #显示生成的词云图像
7. 结果


色 : 0.9509
刘雨昕位好吗她配色色 : 0.9681
孔雪儿女团标准色色色 : 0.9513
蔡学长啊啊啊啊啊啊啊啊啊啊色色 : 0.9976
虞书欣加油色色色 : 0.8856
都是些什么鬼想法虞书欣有人气会演戏有退路就不该给她投票赤裸裸的道德绑架 : 0.9857
我根本没看到前9名公布的时候我操是我眼瞎了吗 : 0.9967
虞书欣和乃万色色色 : 0.9929
宋昭艺妹子冲啊真的很棒啊站看到了你的翻跳视频真的很棒啊啊啊啊色色色 : 0.9997
色 : 0.9509
最爱我们喻言哈哈哈戴萌也好可爱啊色色色 : 0.9846
为了虞书欣来看的青春有你色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色色 : 0.9996
坤坤啊我想看你跳色色 : 0.9775
虞书欣冲冲色色 : 0.9682
微笑微笑色色害羞害羞愉快愉快亲亲亲亲 : 0.9926
喜欢刘雨昕虞书欣还有张总色色 : 0.9906