车牌识别系统设计总结
车牌识别系统
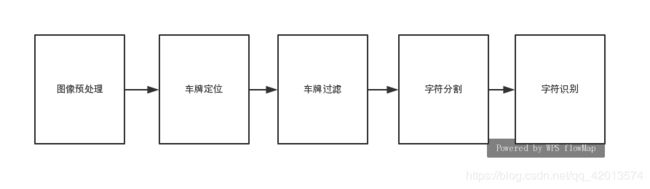
本次项目的主要流程分为如下几步:
1.图像预处理
2.车牌定位
3.车牌定位
4.字符分割
5.字符识别
车牌识别系统实现流程图如下图所示:
车牌识别系统步骤:
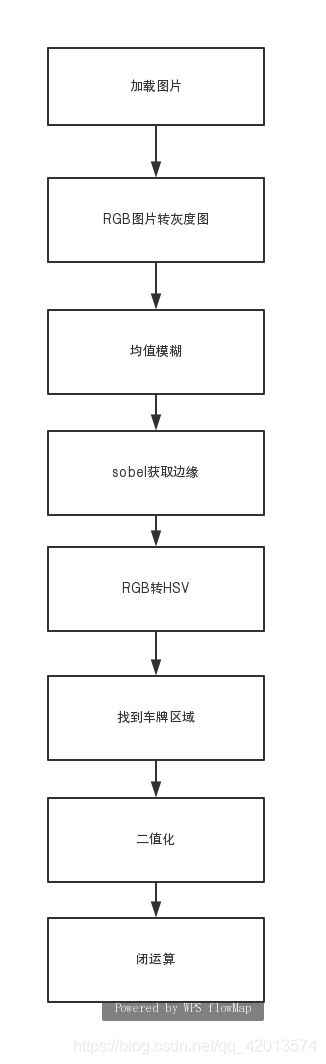
1.图像预处理
输入原始图像:

图像预处理流程图:
图像预处理代码如下:
def pre_process(orig_img):
# 1.将Rgb图像转换成gray图像,减少数据量
gray_img = cv2.cvtColor(orig_img, cv2.COLOR_BGR2GRAY)
# 2.对图像进行均值滤波,(3, 3)表示进行均值滤波方框的大小,柔滑小噪声
blur_img = cv2.blur(gray_img, (3, 3))
# 3.sobel获取垂直边缘
sobel_img = cv2.Sobel(blur_img, cv2.CV_16S, 1, 0, ksize=3)
sobel_img = cv2.convertScaleAbs(sobel_img)
# 4.原始图片从RGB转HSV, 车牌背景一般为蓝色或黄色
hsv_img = cv2.cvtColor(orig_img, cv2.COLOR_BGR2HSV)
h, s, v = hsv_img[:, :, 0], hsv_img[:, :, 1], hsv_img[:, :, 2]
# 5.黄色色调区间[26,34],蓝色色调区间:[100,124]
blue_img = (((h > 26) & (h < 34)) | ((h > 100) & (h < 124))) & (s > 70) & (v > 70)
blue_img = blue_img.astype('float32')
# 蓝色,黄色区域和sobel处理后的图片相乘
mix_img = np.multiply(sobel_img, blue_img)
mix_img = mix_img.astype(np.uint8)
# 6.二值化
ret, binary_img = cv2.threshold(mix_img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 7.闭运算:将车牌垂直的边缘连成一个整体
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 5))
close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
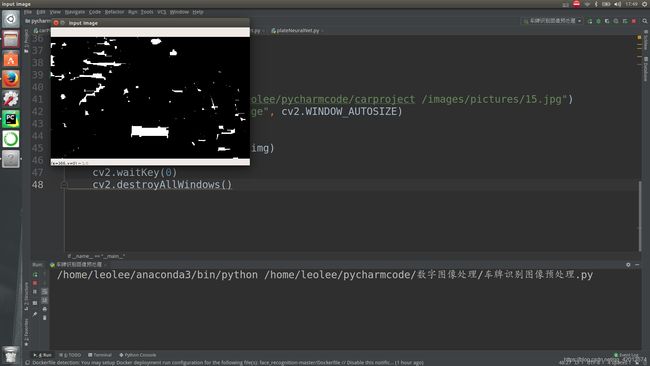
return close_img经过图像预处理后得到的图像:
2.车牌定位
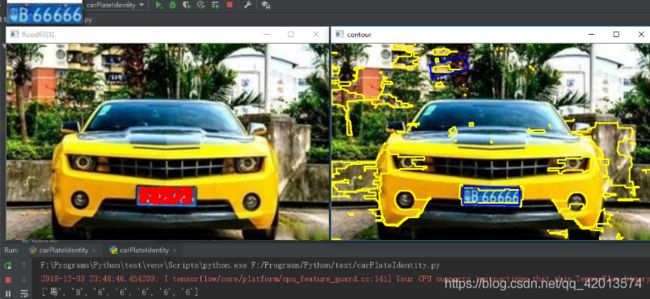
从上图可以看出虽然车牌被相对完整的找出来了,但是整个图片还干扰太多,接下来工作就是减少干扰,尽可能地只保留车牌区域。
车牌定位流程图如下:

车牌定位整体代码如下:
def locate_carPlate(orig_img,pred_image):
carPlate_list = []
temp1_orig_img = orig_img.copy()
temp2_orig_img = orig_img.copy()
cloneImg, contours, heriachy = cv2.findContours(pred_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
cv2.drawContours(temp1_orig_img, contours, i, (0, 255, 255), 2)
# 获取轮廓最小外接矩形,返回值rotate_rect
rotate_rect = cv2.minAreaRect(contour)
# 根据矩形面积大小和长宽比判断是否是车牌
if verify_scale(rotate_rect):
ret, rotate_rect2 = verify_color(rotate_rect, temp2_orig_img)
if ret is False:
continue
# 车牌位置矫正
car_plate = img_Transform(rotate_rect2, temp2_orig_img)
car_plate = cv2.resize(car_plate, (car_plate_w, car_plate_h)) #调整尺寸为后面CNN车牌识别做准备
box = cv2.boxPoints(rotate_rect2)
for k in range(4):
n1, n2 = k % 4, (k+1) % 4
cv2.line(temp1_orig_img, (box[n1][0],box[n1][1]), (box[n2][0], box[n2][1]), (255, 0, 0), 2)
cv2.imshow('opencv_' + str(i), car_plate)
carPlate_list.append(car_plate)
cv2.imshow('contour', temp1_orig_img)
return carPlate_list
矩形面积大小判断是否为车牌功能代码如下:
# 根据矩形面积大小和长宽比判断是否是车牌
def verify_scale(rotate_rect):
error = 0.4
aspect = 4
min_area = 10*(10*aspect)
max_area = 150*(150*aspect)
min_aspect = aspect*(1-error)
max_aspect = aspect*(1+error)
theta = 30
# 宽或高为0,不满足矩形直接返回False
if rotate_rect[1][0] == 0 or rotate_rect[1][1] == 0:
return False
r = rotate_rect[1][0]/rotate_rect[1][1]
r = max(r,1/r)
area = rotate_rect[1][0]*rotate_rect[1][1]
if area>min_area and areamin_aspect and r= -90 and rotate_rect[2] < -(90 - theta)) or
(rotate_rect[1][1] < rotate_rect[1][0] and rotate_rect[2] > -theta and rotate_rect[2] <= 0)):
return True
return False
漫水填充法功能代码如下:
def verify_color(rotate_rect, src_image):
img_h,img_w = src_image.shape[:2]
mask = np.zeros(shape=[img_h+2, img_w+2], dtype=np.uint8)
connectivity = 4 #种子点上下左右4邻域与种子颜色值在[loDiff,upDiff]的被涂成new_value,也可设置8邻域
loDiff,upDiff = 30, 30
new_value = 255
flags = connectivity
flags |= cv2.FLOODFILL_FIXED_RANGE #考虑当前像素与种子象素之间的差,不设置的话则和邻域像素比较
flags |= new_value << 8
flags |= cv2.FLOODFILL_MASK_ONLY #设置这个标识符则不会去填充改变原始图像,而是去填充掩模图像(mask)
rand_seed_num = 5000 #生成多个随机种子
valid_seed_num = 200 #从rand_seed_num中随机挑选valid_seed_num个有效种子
adjust_param = 0.1
box_points = cv2.boxPoints(rotate_rect)
box_points_x = [n[0] for n in box_points]
box_points_x.sort(reverse=False)
adjust_x = int((box_points_x[2]-box_points_x[1])*adjust_param)
col_range = [box_points_x[1]+adjust_x,box_points_x[2]-adjust_x]
box_points_y = [n[1] for n in box_points]
box_points_y.sort(reverse=False)
adjust_y = int((box_points_y[2]-box_points_y[1])*adjust_param)
row_range = [box_points_y[1]+adjust_y, box_points_y[2]-adjust_y]
# 如果以上方法种子点在水平或垂直方向可移动的范围很小,则采用旋转矩阵对角线来设置随机种子点
if (col_range[1]-col_range[0])/(box_points_x[3]-box_points_x[0])<0.4\
or (row_range[1]-row_range[0])/(box_points_y[3]-box_points_y[0])<0.4:
points_row = []
points_col = []
for i in range(2):
pt1,pt2 = box_points[i],box_points[i+2]
x_adjust,y_adjust = int(adjust_param*(abs(pt1[0]-pt2[0]))),int(adjust_param*(abs(pt1[1]-pt2[1])))
if (pt1[0] <= pt2[0]):
pt1[0], pt2[0] = pt1[0] + x_adjust, pt2[0] - x_adjust
else:
pt1[0], pt2[0] = pt1[0] - x_adjust, pt2[0] + x_adjust
if (pt1[1] <= pt2[1]):
pt1[1], pt2[1] = pt1[1] + adjust_y, pt2[1] - adjust_y
else:
pt1[1], pt2[1] = pt1[1] - y_adjust, pt2[1] + y_adjust
temp_list_x = [int(x) for x in np.linspace(pt1[0],pt2[0],int(rand_seed_num /2))]
temp_list_y = [int(y) for y in np.linspace(pt1[1],pt2[1],int(rand_seed_num /2))]
points_col.extend(temp_list_x)
points_row.extend(temp_list_y)
else:
points_row = np.random.randint(row_range[0],row_range[1],size=rand_seed_num)
points_col = np.linspace(col_range[0],col_range[1],num=rand_seed_num).astype(np.int)
points_row = np.array(points_row)
points_col = np.array(points_col)
hsv_img = cv2.cvtColor(src_image, cv2.COLOR_BGR2HSV)
h,s,v = hsv_img[:,:,0],hsv_img[:,:,1],hsv_img[:,:,2]
# 将随机生成的多个种子依次做漫水填充,理想情况是整个车牌被填充
flood_img = src_image.copy()
seed_cnt = 0
for i in range(rand_seed_num):
rand_index = np.random.choice(rand_seed_num,1,replace=False)
row,col = points_row[rand_index],points_col[rand_index]
# 限制随机种子必须是车牌背景色
if (((h[row,col]>26)&(h[row,col]<34))|((h[row,col]>100)&(h[row,col]<124)))&(s[row,col]>70)&(v[row,col]>70):
cv2.floodFill(src_image, mask, (col,row), (255, 255, 255), (loDiff,) * 3, (upDiff,) * 3, flags)
cv2.circle(flood_img,center=(col,row),radius=2,color=(0,0,255),thickness=2)
seed_cnt += 1
if seed_cnt >= valid_seed_num:
break
#======================调试用======================#
show_seed = np.random.uniform(1, 100, 1).astype(np.uint16)
cv2.imshow('floodfill'+str(show_seed), flood_img)
cv2.imshow('flood_mask'+str(show_seed), mask)
#======================调试用======================#
# 获取掩模上被填充点的像素点,并求点集的最小外接矩形
mask_points = []
for row in range(1, img_h+1):
for col in range(1, img_w+1):
if mask[row, col] != 0:
mask_points.append((col-1, row-1))
mask_rotateRect = cv2.minAreaRect(np.array(mask_points))
if verify_scale(mask_rotateRect):
return True, mask_rotateRect
else:
return False, mask_rotateRect车牌矫正功能代码如下:
# 车牌矫正
def img_Transform(car_rect,image):
img_h, img_w = image.shape[:2]
rect_w, rect_h = car_rect[1][0],car_rect[1][1]
angle = car_rect[2]
return_flag = False
if car_rect[2] == 0:
return_flag = True
if car_rect[2] == -90 and rect_w point[0]:
left_point = point
if low_point[1] > point[1]:
low_point = point
if heigth_point[1] < point[1]:
heigth_point = point
if right_point[0] < point[0]:
right_point = point
if left_point[1] <= right_point[1]: # 正角度
new_right_point = [right_point[0], heigth_point[1]]
pts1 = np.float32([left_point, heigth_point, right_point])
pts2 = np.float32([left_point, heigth_point, new_right_point]) # 字符只是高度需要改变
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(image, M, (round(img_w*2), round(img_h*2)))
car_img = dst[int(left_point[1]):int(heigth_point[1]), int(left_point[0]):int(new_right_point[0])]
elif left_point[1] > right_point[1]: # 负角度
new_left_point = [left_point[0], heigth_point[1]]
pts1 = np.float32([left_point, heigth_point, right_point])
pts2 = np.float32([new_left_point, heigth_point, right_point]) # 字符只是高度需要改变
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(image, M, (round(img_w*2), round(img_h*2)))
car_img = dst[int(right_point[1]):int(heigth_point[1]), int(new_left_point[0]):int(right_point[0])]
return car_img 结果如下:

3.车牌过滤
利用神经网络进一步对图像是否为车牌进行分类。
搭建的卷积神经网络框架结构如下图所示:
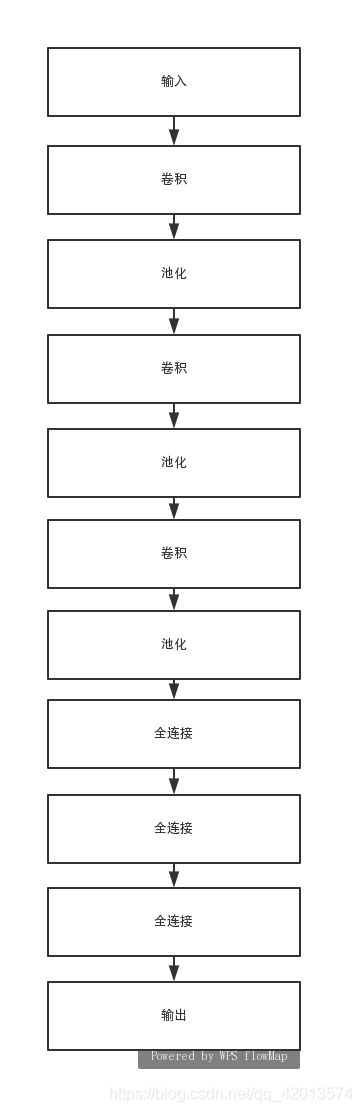
搭建的神经网络代码如下:
def cnn_construct(self):
x_input = tf.reshape(self.x_place, shape=[-1, self.img_h, self.img_w, 3])
cw1 = tf.Variable(tf.random_normal(shape=[3, 3, 3, 32], stddev=0.01), dtype=tf.float32)
cb1 = tf.Variable(tf.random_normal(shape=[32]), dtype=tf.float32)
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x_input, filter=cw1, strides=[1, 1, 1, 1], padding='SAME'), cb1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, self.keep_place)
cw2 = tf.Variable(tf.random_normal(shape=[3, 3, 32, 64], stddev=0.01), dtype=tf.float32)
cb2 = tf.Variable(tf.random_normal(shape=[64]), dtype=tf.float32)
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, filter=cw2, strides=[1, 1, 1, 1], padding='SAME'), cb2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, self.keep_place)
cw3 = tf.Variable(tf.random_normal(shape=[3, 3, 64, 128], stddev=0.01), dtype=tf.float32)
cb3 = tf.Variable(tf.random_normal(shape=[128]), dtype=tf.float32)
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, filter=cw3, strides=[1, 1, 1, 1], padding='SAME'), cb3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, self.keep_place)
conv_out = tf.reshape(conv3, shape=[-1, 17 * 5 * 128])
fw1 = tf.Variable(tf.random_normal(shape=[17 * 5 * 128, 1024], stddev=0.01), dtype=tf.float32)
fb1 = tf.Variable(tf.random_normal(shape=[1024]), dtype=tf.float32)
fully1 = tf.nn.relu(tf.add(tf.matmul(conv_out, fw1), fb1))
fully1 = tf.nn.dropout(fully1, self.keep_place)
fw2 = tf.Variable(tf.random_normal(shape=[1024, 1024], stddev=0.01), dtype=tf.float32)
fb2 = tf.Variable(tf.random_normal(shape=[1024]), dtype=tf.float32)
fully2 = tf.nn.relu(tf.add(tf.matmul(fully1, fw2), fb2))
fully2 = tf.nn.dropout(fully2, self.keep_place)
fw3 = tf.Variable(tf.random_normal(shape=[1024, self.y_size], stddev=0.01), dtype=tf.float32)
fb3 = tf.Variable(tf.random_normal(shape=[self.y_size]), dtype=tf.float32)
fully3 = tf.add(tf.matmul(fully2, fw3), fb3, name='out_put')
return fully3
4.字符分割
字符分割主要有两个部分组成:水平投影和垂直投影。
水平投影:将二值化的车牌图片水平投影到Y轴,得到连续投影最长的一段作为字符区域,因为车牌四周有白色的边缘,这里可以把水平方向上的连续白线过滤掉。
垂直投影:因为字符与字符之间总会分隔一段距离,因此可以作为水平分割的依据,分割后的字符宽度必须达到平均宽度才能算作一个字符,这里可以排除车牌第2、3字符中间的“.”。
字符分割函数代码如下:
def extract_char(car_plate):
gray_plate = cv2.cvtColor(car_plate, cv2.COLOR_BGR2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
char_img_list = get_chars(binary_plate)
return char_img_list投影处理功能代码:
def get_chars(car_plate):
img_h,img_w = car_plate.shape[:2]
h_proj_list = [] # 水平投影长度列表
h_temp_len,v_temp_len = 0,0
h_startIndex,h_end_index = 0,0 # 水平投影记索引
h_proj_limit = [0.2,0.8] # 车牌在水平方向得轮廓长度少于20%或多余80%过滤掉
char_imgs = []
# 将二值化的车牌水平投影到Y轴,计算投影后的连续长度,连续投影长度可能不止一段
h_count = [0 for i in range(img_h)]
for row in range(img_h):
temp_cnt = 0
for col in range(img_w):
if car_plate[row,col] == 255:
temp_cnt += 1
h_count[row] = temp_cnt
if temp_cnt/img_wh_proj_limit[1]:
if h_temp_len != 0:
h_end_index = row-1
h_proj_list.append((h_startIndex,h_end_index))
h_temp_len = 0
continue
if temp_cnt > 0:
if h_temp_len == 0:
h_startIndex = row
h_temp_len = 1
else:
h_temp_len += 1
else:
if h_temp_len > 0:
h_end_index = row-1
h_proj_list.append((h_startIndex,h_end_index))
h_temp_len = 0
# 手动结束最后得水平投影长度累加
if h_temp_len != 0:
h_end_index = img_h-1
h_proj_list.append((h_startIndex, h_end_index))
# 选出最长的投影,该投影长度占整个截取车牌高度的比值必须大于0.5
h_maxIndex,h_maxHeight = 0,0
for i,(start,end) in enumerate(h_proj_list):
if h_maxHeight < (end-start):
h_maxHeight = (end-start)
h_maxIndex = i
if h_maxHeight/img_h < 0.5:
return char_imgs
chars_top,chars_bottom = h_proj_list[h_maxIndex][0],h_proj_list[h_maxIndex][1]
plates = car_plate[chars_top:chars_bottom+1,:]
cv2.imwrite('./carIdentityData/opencv_output/car.jpg', car_plate)
cv2.imwrite('./carIdentityData/opencv_output/plate.jpg', plates)
char_addr_list = horizontal_cut_chars(plates)
for i,addr in enumerate(char_addr_list):
char_img = car_plate[chars_top:chars_bottom+1,addr[0]:addr[1]]
char_img = cv2.resize(char_img,(char_w,char_h))
char_imgs.append(char_img)
return char_imgs
左右切割代码:
# 左右切割
def horizontal_cut_chars(plate):
char_addr_list = []
area_left, area_right, char_left, char_right = 0, 0, 0, 0
img_w = plate.shape[1]
# 获取车牌每列边缘像素点个数
def getColSum(img,col):
sum = 0
for i in range(img.shape[0]):
sum += round(img[i, col]/255)
return sum
sum = 0
for col in range(img_w):
sum += getColSum(plate,col)
# 每列边缘像素点必须超过均值的60%才能判断属于字符区域
col_limit = 0#round(0.5*sum/img_w)
# 每个字符宽度也进行限制
charWid_limit = [round(img_w/12), round(img_w/5)]
is_char_flag = False
for i in range(img_w):
colValue = getColSum(plate,i)
if colValue > col_limit:
if is_char_flag == False:
area_right = round((i+char_right)/2)
area_width = area_right-area_left
char_width = char_right-char_left
if (area_width>charWid_limit[0]) and (area_width charWid_limit[0]) and (area_width < charWid_limit[1]):
char_addr_list.append((area_left, area_right, char_width))
return char_addr_list
结果如下:
![]()
5.字符识别
利用卷积神经网络进行车牌字符的识别。网络结构和车牌分类的网络结构一样。
最终结果如下所示: