PaddlePaddle深度学习之车牌识别
PaddlePaddle深度学习之车牌识别
- 前提
- 数据处理
- 网络结构的建立(LeNet)
- 训练配置
- 测试模型准确率
前提
本代码使用的是百度的 PaddlePaddle 深度框架。整体包含数据处理,网络搭建,开始训练,结果预测。
数据处理
数据存储结构为
├── 0
├── 1
├── 2
├── 3
├── 4
├── 5
├── 6
├── 7
├── 8
├── 9
├── A
├── B
├── C
├── cuan
├── D
├── E
├── e1
├── F
├── G
├── gan
.
.
.
└── zhe
每个文件夹下为文字图象类似手写体。由于图像较小(20*20),
![]()
图象中的信息含量少,本次训练易采用 深度较浅的网络结构 LeNet,AlexNet都是不错的选择。本次采用了LeNet的网络结构。
首先我们建立图像目录与标签的列表代码如下
import os
data_path = './'
character_folders = os.listdir(data_path)
label = 0
LABEL_temp = {} # 用于查看label数目和名称,以及name与number的对应关系
if(os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if(os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
LABEL_temp[str(label)] = character_folder #存储一下标签的对应关系
character_imgs = os.listdir(os.path.join(data_path, character_folder))
for i in range(len(character_imgs)):
if i%10 == 0:
f_test.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
else:
f_train.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
label = label + 1
print('图像列表已生成')
建立迭代器
def data_mapper(sample):
img, label = sample
img = paddle.dataset.image.load_image(file=img, is_color=False)
img = img.flatten().astype('float32') / 255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=512), batch_size=128)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=128)
网络结构的建立(LeNet)
class LeNet(fluid.dygraph.Layer):
def __init__(self, num_classes=65, is_train = True):
super(LeNet, self).__init__()
name_scope = self.full_name()
# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
self.conv1 = Conv2D(num_channels = 1, num_filters=6, filter_size=2, act='sigmoid')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels = 6, num_filters=16, filter_size=2, act='sigmoid')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 创建第3个卷积层
self.conv3 = Conv2D(num_channels = 16, num_filters=120, filter_size=4, act='sigmoid')
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分裂标签的类别数
self.fc1 = Linear(input_dim = 120, output_dim=64, act='sigmoid')
self.fc2 = Linear(input_dim = 64, output_dim=num_classes)
if is_train:
self.drop_ratio = 0.5
else:
self.drop_ratio = 0.0
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)# [5, 6, 19, 19]
# print('# ',x.shape)
x = self.pool1(x)# [5, 6, 9, 9]
# print('# ',x.shape)
x = self.conv2(x)# [5, 16, 8, 8]
# print('# ',x.shape)
x = self.pool2(x)# [5, 16, 4, 4]
# print('# ',x.shape)
x = self.conv3(x)# [5, 120, 1, 1]
# print('# ',x.shape)
x = fluid.layers.reshape(x,[x.shape[0], -1])
x = self.fc1(x)
x = fluid.layers.dropout(x, self.drop_ratio)
# print('# ',x.shape)
x = self.fc2(x)
return x
可以通过加print函数判断每次迭代产生的维度,并验证网络结构数据维度是否合理
训练配置
with fluid.dygraph.guard():
model=LeNet() #模型实例化
model.train() #训练模式
boundaries = [40000, 80000]
values = [0.001, 0.0001, 0.00001]
# 采用分步数学习率递减策略
opt=fluid.optimizer.AdamOptimizer(learning_rate=fluid.layers.piecewise_decay(boundaries=boundaries, values=values), parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num= 200 #迭代次数为2
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(1,20,20) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
loss=fluid.layers.softmax_with_cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
if pass_num%50 == 0:
fluid.save_dygraph(model.state_dict(),'MyLeNet'+str(pass_num))
fluid.save_dygraph(model.state_dict(),'MyLeNet')#保存模型
训练结果如下
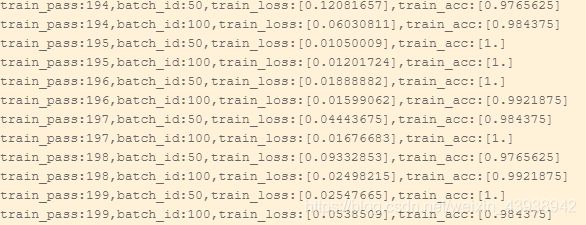
可以看出最后收敛性相当的不错
测试模型准确率
#模型校验
with fluid.dygraph.guard():
accs = []
model=LeNet()#模型实例化
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
for batch_id,data in enumerate(test_reader()):#测试集
images=np.array([x[0].reshape(1,20,20) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
经测试,测试集准确率也可以达到90%以上