zookeeper:
zookeeper是apache下的一个子项目,主要可以用来实现分布式服务之间的资源统一,命名服务统一,状态同步,集群管理等等。
三种节点,leader,follower,observer,observer为观察者,不参与到实际的选举,用来配合follower进行读数据操作。
zookeeper下是通过ZAB协议来保证分布式事务的一致性的。ZAB协议是在Paxos协议上的升级。下面先介绍下ZAB协议与Paxos协议:
ZAB协议:
特点:通过从节点(follow),与主节点(leader)的框架实现。在写数据的时候,通过唯一的主节点负责执行外部的写事务请求,然后在将数据同步到每一个从节点(follow)中去。读数据的时候,随便从一个从节点中读取数据返回。
广播模式:
leader通过广播的模式,将写请求转换为事务(Proposal )的方式发放到每一个follow节点中(内部会维护一张存放每个follow的表)(通过的是队列(解耦合,且每一个follow都会有一个相对应的队列)的方式,按FIFO的顺序依次执行),待超过半数的节点通过ACK机制确认返回的时候,leader再次发送commit请求给每一个follow,然后完成事务的提交。
奔溃恢复模式:
包含Leader选举 和 数据恢复
当leader宕机的时候,我们需要重新选举出新的leader,主要存在两种情况:
1:当leader的事务发送给每个节点完后,follow处理完,然后leader提出了commit请求,需要提交的时候,leader挂了
2:当leader发送完事务后,leader挂了。
我们需要处理上述的两种情况:
1)当在第一种情况挂掉的时候,我们需要将所有的follow进行正确的提交(每一个从节点都已经执行完了,要提交了,数据需要更新,事务+1)。
2)在第二种情况下,leader发送了请求,但是follow还没提交,我们可以进行事务的回滚,所以我们需要丢弃正在执行但未提交的事务。
因此我们选举出来的leader需要满足以下的条件:
新选举出来的 Leader 不能包含未提交的 Proposal (新的leader需要进行事务回滚,所以不能包含未提交的事务。)。
新选举的 Leader 节点中含有最大的 zxid (让leader不用再去确认我们当前的事务是不是正确的)。
zxid:
zxid是一个64位的数字。前32位用来记录事务的id,后32位用来记录epoch的值,epoch用来标识当前的集群年代,即代表主节点是否被更换过。
zxid中的前32位,当lead每次进行事务的发放的时候,从节点直接完后都会进行zxid+1的操作,所以如果zxid越大,说明它指向的事务版本比较高,数据是比较新的。而zxid中的后32位,epoch值是这样更新的-》每次选举的时候,取出zxid中后32值,然后进行+1操作,然后置前32位为0,即事务id重新开始计算,这样也保证了epoch值如果为最新的话,那么版本就是最新的。
选举的策略:
1)选 epoch 最大的
2)若 epoch 相等,选 zxid 最大的 (一般epoch(后32位)最大,zxid也最大)
3)若 epoch 和 zxid 相等,选择 server_id 最大的(zoo.cfg中的myid)
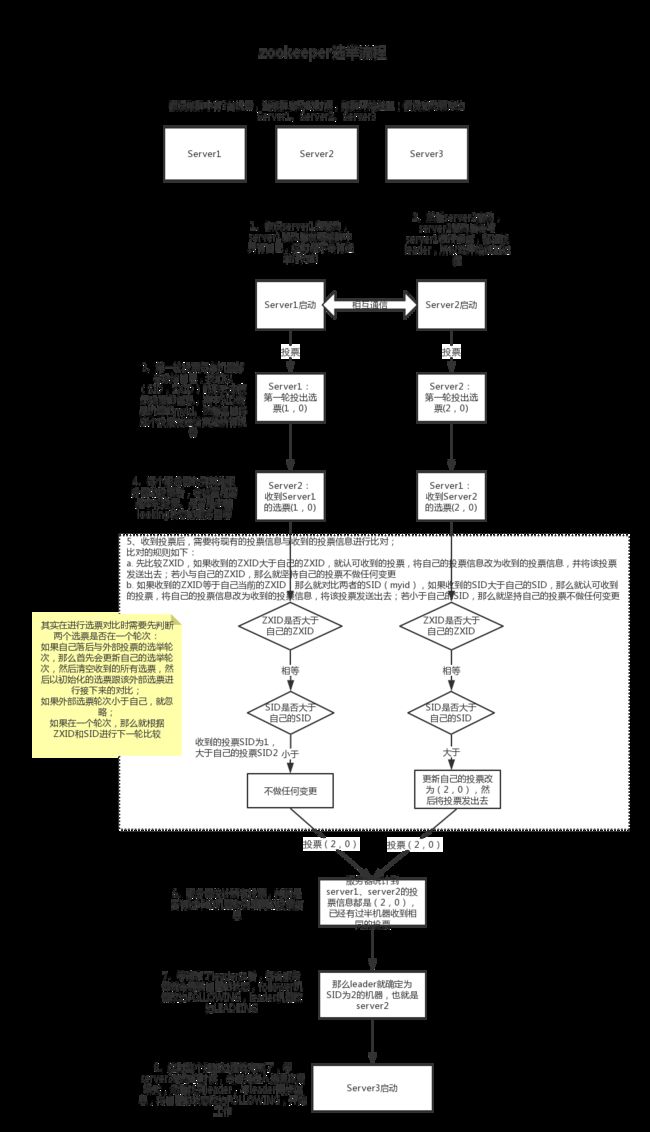
具体的选举流程:
节点的持久状态:
- history:当前节点接收到事务 Proposal 的Log
- acceptedEpoch:Follower 已经接受的 Leader 更改 epoch 的 newEpoch 提议。
- currentEpoch:当前所处的 Leader 年代
- lastZxid:history 中最近接收到的Proposal 的 zxid(最大zxid)
选举完之后,我们需要进行数据的恢复,数据的恢复会根据lastZxid来找到最大的zxid,即找到了最新的数据信息,进行数据的同步与恢复,然后恢复正常,进入广播模式。
Paxos协议: