Caffeine Cache-高性能Java本地缓存之王(基于LRU算法的优化策略)
1 Caffeine、ConcurrentMap、GuavaCache、ehcache等做了详细的压测对比
https://mp.weixin.qq.com/s/zhYeNeyiPpFDbOukKM7uIQ
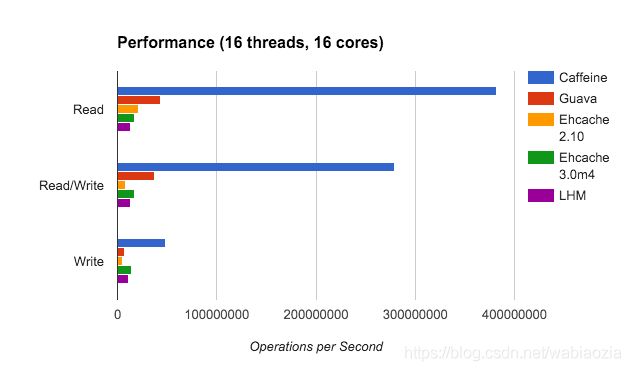
2 Caffeine Cache-高性能Java本地缓存
www.cnblogs.com/rickiyang/p/11074158.html
前面刚说到Guava Cache,他的优点是封装了get,put操作;提供线程安全的缓存操作;提供过期策略;提供回收策略;缓存监控。当缓存的数据超过最大值时,使用LRU算法替换。这一篇我们将要谈到一个新的本地缓存框架:Caffeine Cache。它也是站在巨人的肩膀上-Guava Cache,借着他的思想优化了算法发展而来。
本篇博文主要介绍Caffine Cache 的使用方式,以及Caffine Cache在SpringBoot中的使用。
1. Caffine Cache 在算法上的优点-W-TinyLFU#
说到优化,Caffine Cache到底优化了什么呢?我们刚提到过LRU,常见的缓存淘汰算法还有FIFO,LFU:
- FIFO:先进先出,在这种淘汰算法中,先进入缓存的会先被淘汰,会导致命中率很低。
- LRU:最近最少使用算法,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。仍然有个问题,如果有个数据在 1 分钟访问了 1000次,再后 1 分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
- LFU:最近最少频率使用,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了 LRU 不能处理时间段的问题。
上面三种策略各有利弊,实现的成本也是一个比一个高,同时命中率也是一个比一个好。Guava Cache虽然有这么多的功能,但是本质上还是对LRU的封装,如果有更优良的算法,并且也能提供这么多功能,相比之下就相形见绌了。
LFU的局限性:在 LFU 中只要数据访问模式的概率分布随时间保持不变时,其命中率就能变得非常高。比如有部新剧出来了,我们使用 LFU 给他缓存下来,这部新剧在这几天大概访问了几亿次,这个访问频率也在我们的 LFU 中记录了几亿次。但是新剧总会过气的,比如一个月之后这个新剧的前几集其实已经过气了,但是他的访问量的确是太高了,其他的电视剧根本无法淘汰这个新剧,所以在这种模式下是有局限性。
LRU的优点和局限性:LRU可以很好的应对突发流量的情况,因为他不需要累计数据频率。但LRU通过历史数据来预测未来是局限的,它会认为最后到来的数据是最可能被再次访问的,从而给与它最高的优先级。
在现有算法的局限性下,会导致缓存数据的命中率或多或少的受损,而命中略又是缓存的重要指标。HighScalability网站刊登了一篇文章,由前Google工程师发明的W-TinyLFU——一种现代的缓存 。Caffine Cache就是基于此算法而研发。Caffeine 因使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率。
当数据的访问模式不随时间变化的时候,LFU的策略能够带来最佳的缓存命中率。然而LFU有两个缺点:
首先,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;
其次,如果数据访问模式随时间有变,LFU的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存,而后期访问较多的记录则无法被命中。
因此,大多数的缓存设计都是基于LRU或者其变种来进行的。相比之下,LRU并不需要维护昂贵的缓存记录元信息,同时也能够反应随时间变化的数据访问模式。然而,在许多负载之下,LRU依然需要更多的空间才能做到跟LFU一致的缓存命中率。因此,一个“现代”的缓存,应当能够综合两者的长处。
TinyLFU维护了近期访问记录的频率信息,作为一个过滤器,当新记录来时,只有满足TinyLFU要求的记录才可以被插入缓存。如前所述,作为现代的缓存,它需要解决两个挑战:
一个是如何避免维护频率信息的高开销;
另一个是如何反应随时间变化的访问模式。
首先来看前者,TinyLFU借助了数据流Sketching技术,Count-Min Sketch显然是解决这个问题的有效手段,它可以用小得多的空间存放频率信息,而保证很低的False Positive Rate。但考虑到第二个问题,就要复杂许多了,因为我们知道,任何Sketching数据结构如果要反应时间变化都是一件困难的事情,在Bloom Filter方面,我们可以有Timing Bloom Filter,但对于CMSketch来说,如何做到Timing CMSketch就不那么容易了。TinyLFU采用了一种基于滑动窗口的时间衰减设计机制,借助于一种简易的reset操作:每次添加一条记录到Sketch的时候,都会给一个计数器上加1,当计数器达到一个尺寸W的时候,把所有记录的Sketch数值都除以2,该reset操作可以起到衰减的作用 。
W-TinyLFU主要用来解决一些稀疏的突发访问元素。在一些数目很少但突发访问量很大的场景下,TinyLFU将无法保存这类元素,因为它们无法在给定时间内积累到足够高的频率。因此W-TinyLFU就是结合LFU和LRU,前者用来应对大多数场景,而LRU用来处理突发流量。
在处理频率记录的方案中,你可能会想到用hashMap去存储,每一个key对应一个频率值。那如果数据量特别大的时候,是不是这个hashMap也会特别大呢。由此可以联想到 Bloom Filter,对于每个key,用n个byte每个存储一个标志用来判断key是否在集合中。原理就是使用k个hash函数来将key散列成一个整数。
在W-TinyLFU中使用Count-Min Sketch记录我们的访问频率,而这个也是布隆过滤器的一种变种。如下图所示:
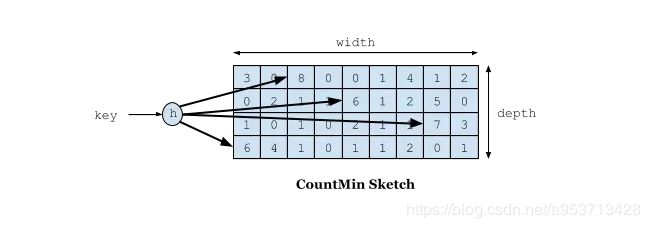
如果需要记录一个值,那我们需要通过多种Hash算法对其进行处理hash,然后在对应的hash算法的记录中+1,为什么需要多种hash算法呢?由于这是一个压缩算法必定会出现冲突,比如我们建立一个byte的数组,通过计算出每个数据的hash的位置。比如张三和李四,他们两有可能hash值都是相同,比如都是1那byte[1]这个位置就会增加相应的频率,张三访问1万次,李四访问1次那byte[1]这个位置就是1万零1,如果取李四的访问评率的时候就会取出是1万零1,但是李四命名只访问了1次啊,为了解决这个问题,所以用了多个hash算法可以理解为long[][]二维数组的一个概念,比如在第一个算法张三和李四冲突了,但是在第二个,第三个中很大的概率不冲突,比如一个算法大概有1%的概率冲突,那四个算法一起冲突的概率是1%的四次方。通过这个模式我们取李四的访问率的时候取所有算法中,李四访问最低频率的次数。所以他的名字叫Count-Min Sketch。
2. 使用#
Caffeine Cache 的github地址:点我。
目前的最新版本是:
com.github.ben-manes.caffeine
caffeine
2.6.2
2.1 缓存填充策略#
Caffeine Cache提供了三种缓存填充策略:手动、同步加载和异步加载。
1.手动加载
在每次get key的时候指定一个同步的函数,如果key不存在就调用这个函数生成一个值。
/**
* 手动加载
* @param key
* @return
*/
public Object manulOperator(String key) {
Cache cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
.build();
//如果一个key不存在,那么会进入指定的函数生成value
Object value = cache.get(key, t -> setValue(key).apply(key));
cache.put("hello",value);
//判断是否存在如果不存返回null
Object ifPresent = cache.getIfPresent(key);
//移除一个key
cache.invalidate(key);
return value;
}
public Function setValue(String key){
return t -> key + "value";
}
2. 同步加载
构造Cache时候,build方法传入一个CacheLoader实现类。实现load方法,通过key加载value。
/**
* 同步加载
* @param key
* @return
*/
public Object syncOperator(String key){
LoadingCache cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(k -> setValue(key).apply(key));
return cache.get(key);
}
public Function setValue(String key){
return t -> key + "value";
}
3. 异步加载
AsyncLoadingCache是继承自LoadingCache类的,异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
/**
* 异步加载
*
* @param key
* @return
*/
public Object asyncOperator(String key){
AsyncLoadingCache cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.buildAsync(k -> setAsyncValue(key).get());
return cache.get(key);
}
public CompletableFuture 2.2 回收策略#
Caffeine提供了3种回收策略:基于大小回收,基于时间回收,基于引用回收。
1. 基于大小的过期方式
基于大小的回收策略有两种方式:一种是基于缓存大小,一种是基于权重。
// 根据缓存的计数进行驱逐
LoadingCache cache = Caffeine.newBuilder()
.maximumSize(10000)
.build(key -> function(key));
// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)
LoadingCache cache1 = Caffeine.newBuilder()
.maximumWeight(10000)
.weigher(key -> function1(key))
.build(key -> function(key));
maximumWeight与maximumSize不可以同时使用。
2.基于时间的过期方式
// 基于固定的到期策略进行退出
LoadingCache cache = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(key -> function(key));
LoadingCache cache1 = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> function(key));
// 基于不同的到期策略进行退出
LoadingCache cache2 = Caffeine.newBuilder()
.expireAfter(new Expiry() {
@Override
public long expireAfterCreate(String key, Object value, long currentTime) {
return TimeUnit.SECONDS.toNanos(seconds);
}
@Override
public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
@Override
public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
}).build(key -> function(key));
Caffeine提供了三种定时驱逐策略:
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry): 自定义策略,过期时间由Expiry实现独自计算。
缓存的删除策略使用的是惰性删除和定时删除。这两个删除策略的时间复杂度都是O(1)。
3. 基于引用的过期方式
Java中四种引用类型
| 引用类型 | 被垃圾回收时间 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 Strong Reference | 从来不会 | 对象的一般状态 | JVM停止运行时终止 |
| 软引用 Soft Reference | 在内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 Weak Reference | 在垃圾回收时 | 对象缓存 | gc运行后终止 |
| 虚引用 Phantom Reference | 从来不会 | 可以用虚引用来跟踪对象被垃圾回收器回收的活动,当一个虚引用关联的对象被垃圾收集器回收之前会收到一条系统通知 | JVM停止运行时终止 |
// 当key和value都没有引用时驱逐缓存
LoadingCache cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> function(key));
// 当垃圾收集器需要释放内存时驱逐
LoadingCache cache1 = Caffeine.newBuilder()
.softValues()
.build(key -> function(key));
注意:AsyncLoadingCache不支持弱引用和软引用。
Caffeine.weakKeys(): 使用弱引用存储key。如果没有其他地方对该key有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.weakValues() :使用弱引用存储value。如果没有其他地方对该value有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.softValues() :使用软引用存储value。当内存满了过后,软引用的对象以将使用最近最少使用(least-recently-used ) 的方式进行垃圾回收。由于使用软引用是需要等到内存满了才进行回收,所以我们通常建议给缓存配置一个使用内存的最大值。 softValues() 将使用身份相等(identity) (==) 而不是equals() 来比较值。
Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。
3. 移除事件监听#
Cache cache = Caffeine.newBuilder()
.removalListener((String key, Object value, RemovalCause cause) ->
System.out.printf("Key %s was removed (%s)%n", key, cause))
.build();
4. 写入外部存储#
CacheWriter 方法可以将缓存中所有的数据写入到第三方。
LoadingCache cache2 = Caffeine.newBuilder()
.writer(new CacheWriter() {
@Override public void write(String key, Object value) {
// 写入到外部存储
}
@Override public void delete(String key, Object value, RemovalCause cause) {
// 删除外部存储
}
})
.build(key -> function(key));
如果你有多级缓存的情况下,这个方法还是很实用。
注意:CacheWriter不能与弱键或AsyncLoadingCache一起使用。
5. 统计#
与Guava Cache的统计一样。
Cache cache = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();
通过使用Caffeine.recordStats(), 可以转化成一个统计的集合. 通过 Cache.stats() 返回一个CacheStats。CacheStats提供以下统计方法:
hitRate(): 返回缓存命中率
evictionCount(): 缓存回收数量
averageLoadPenalty(): 加载新值的平均时间
3. SpringBoot 中默认Cache-Caffine Cache#
SpringBoot 1.x版本中的默认本地cache是Guava Cache。在2.x(Spring Boot 2.0(spring 5) )版本中已经用Caffine Cache取代了Guava Cache。毕竟有了更优的缓存淘汰策略。
下面我们来说在SpringBoot2.x版本中如何使用cache。
1. 引入依赖:#
org.springframework.boot
spring-boot-starter-cache
com.github.ben-manes.caffeine
caffeine
2.6.2
2. 添加注解开启缓存支持#
添加@EnableCaching注解:
@SpringBootApplication
@EnableCaching
public class SingleDatabaseApplication {
public static void main(String[] args) {
SpringApplication.run(SingleDatabaseApplication.class, args);
}
}
3. 配置文件的方式注入相关参数#
properties文件
spring.cache.cache-names=cache1
spring.cache.caffeine.spec=initialCapacity=50,maximumSize=500,expireAfterWrite=10s
或Yaml文件
spring:
cache:
type: caffeine
cache-names:
- userCache
caffeine:
spec: maximumSize=1024,refreshAfterWrite=60s
如果使用refreshAfterWrite配置,必须指定一个CacheLoader.不用该配置则无需这个bean,如上所述,该CacheLoader将关联被该缓存管理器管理的所有缓存,所以必须定义为CacheLoader
import com.github.benmanes.caffeine.cache.CacheLoader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description:
*/
@Configuration
public class CacheConfig {
/**
* 相当于在构建LoadingCache对象的时候 build()方法中指定过期之后的加载策略方法
* 必须要指定这个Bean,refreshAfterWrite=60s属性才生效
* @return
*/
@Bean
public CacheLoader cacheLoader() {
CacheLoader cacheLoader = new CacheLoader() {
@Override
public Object load(String key) throws Exception {
return null;
}
// 重写这个方法将oldValue值返回回去,进而刷新缓存
@Override
public Object reload(String key, Object oldValue) throws Exception {
return oldValue;
}
};
return cacheLoader;
}
}
Caffeine常用配置说明:
initialCapacity=[integer]: 初始的缓存空间大小
maximumSize=[long]: 缓存的最大条数
maximumWeight=[long]: 缓存的最大权重
expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期
expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期
refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存
weakKeys: 打开key的弱引用
weakValues:打开value的弱引用
softValues:打开value的软引用
recordStats:开发统计功能
注意:
expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准。
maximumSize和maximumWeight不可以同时使用
weakValues和softValues不可以同时使用
需要说明的是,使用配置文件的方式来进行缓存项配置,一般情况能满足使用需求,但是灵活性不是很高,如果我们有很多缓存项的情况下写起来会导致配置文件很长。所以一般情况下你也可以选择使用bean的方式来初始化Cache实例。
下面的演示使用bean的方式来注入:
package com.rickiyang.learn.cache;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.apache.commons.compress.utils.Lists;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description:
*/
@Configuration
public class CacheConfig {
/**
* 创建基于Caffeine的Cache Manager
* 初始化一些key存入
* @return
*/
@Bean
@Primary
public CacheManager caffeineCacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
ArrayList caches = Lists.newArrayList();
List list = setCacheBean();
for(CacheBean cacheBean : list){
caches.add(new CaffeineCache(cacheBean.getKey(),
Caffeine.newBuilder().recordStats()
.expireAfterWrite(cacheBean.getTtl(), TimeUnit.SECONDS)
.maximumSize(cacheBean.getMaximumSize())
.build()));
}
cacheManager.setCaches(caches);
return cacheManager;
}
/**
* 初始化一些缓存的 key
* @return
*/
private List setCacheBean(){
List list = Lists.newArrayList();
CacheBean userCache = new CacheBean();
userCache.setKey("userCache");
userCache.setTtl(60);
userCache.setMaximumSize(10000);
CacheBean deptCache = new CacheBean();
deptCache.setKey("userCache");
deptCache.setTtl(60);
deptCache.setMaximumSize(10000);
list.add(userCache);
list.add(deptCache);
return list;
}
class CacheBean {
private String key;
private long ttl;
private long maximumSize;
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public long getTtl() {
return ttl;
}
public void setTtl(long ttl) {
this.ttl = ttl;
}
public long getMaximumSize() {
return maximumSize;
}
public void setMaximumSize(long maximumSize) {
this.maximumSize = maximumSize;
}
}
}
创建了一个SimpleCacheManager作为Cache的管理对象,然后初始化了两个Cache对象,分别存储user,dept类型的缓存。当然构建Cache的参数设置我写的比较简单,你在使用的时候酌情根据需要配置参数。
4. 使用注解来对 cache 增删改查#
我们可以使用spring提供的 @Cacheable、@CachePut、@CacheEvict等注解来方便的使用caffeine缓存。
如果使用了多个cahce,比如redis、caffeine等,必须指定某一个CacheManage为@primary,在@Cacheable注解中没指定 cacheManager 则使用标记为primary的那个。
cache方面的注解主要有以下5个:
- @Cacheable 触发缓存入口(这里一般放在创建和获取的方法上,
@Cacheable注解会先查询是否已经有缓存,有会使用缓存,没有则会执行方法并缓存) - @CacheEvict 触发缓存的eviction(用于删除的方法上)
- @CachePut 更新缓存且不影响方法执行(用于修改的方法上,该注解下的方法始终会被执行)
- @Caching 将多个缓存组合在一个方法上(该注解可以允许一个方法同时设置多个注解)
- @CacheConfig 在类级别设置一些缓存相关的共同配置(与其它缓存配合使用)
说一下@Cacheable 和 @CachePut的区别:
@Cacheable:它的注解的方法是否被执行取决于Cacheable中的条件,方法很多时候都可能不被执行。
@CachePut:这个注解不会影响方法的执行,也就是说无论它配置的条件是什么,方法都会被执行,更多的时候是被用到修改上。
简要说一下Cacheable类中各个方法的使用:
public @interface Cacheable {
/**
* 要使用的cache的名字
*/
@AliasFor("cacheNames")
String[] value() default {};
/**
* 同value(),决定要使用那个/些缓存
*/
@AliasFor("value")
String[] cacheNames() default {};
/**
* 使用SpEL表达式来设定缓存的key,如果不设置默认方法上所有参数都会作为key的一部分
*/
String key() default "";
/**
* 用来生成key,与key()不可以共用
*/
String keyGenerator() default "";
/**
* 设定要使用的cacheManager,必须先设置好cacheManager的bean,这是使用该bean的名字
*/
String cacheManager() default "";
/**
* 使用cacheResolver来设定使用的缓存,用法同cacheManager,但是与cacheManager不可以同时使用
*/
String cacheResolver() default "";
/**
* 使用SpEL表达式设定出发缓存的条件,在方法执行前生效
*/
String condition() default "";
/**
* 使用SpEL设置出发缓存的条件,这里是方法执行完生效,所以条件中可以有方法执行后的value
*/
String unless() default "";
/**
* 用于同步的,在缓存失效(过期不存在等各种原因)的时候,如果多个线程同时访问被标注的方法
* 则只允许一个线程通过去执行方法
*/
boolean sync() default false;
}
基于注解的使用方法:
package com.rickiyang.learn.cache;
import com.rickiyang.learn.entity.User;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
/**
* @author: rickiyang
* @date: 2019/6/15
* @description: 本地cache
*/
@Service
public class UserCacheService {
/**
* 查找
* 先查缓存,如果查不到,会查数据库并存入缓存
* @param id
*/
@Cacheable(value = "userCache", key = "#id", sync = true)
public void getUser(long id){
//查找数据库
}
/**
* 更新/保存
* @param user
*/
@CachePut(value = "userCache", key = "#user.id")
public void saveUser(User user){
//todo 保存数据库
}
/**
* 删除
* @param user
*/
@CacheEvict(value = "userCache",key = "#user.id")
public void delUser(User user){
//todo 保存数据库
}
}
如果你不想使用注解的方式去操作缓存,也可以直接使用SimpleCacheManager获取缓存的key进而进行操作。
注意到上面的key使用了spEL 表达式。Spring Cache提供了一些供我们使用的SpEL上下文数据,下表直接摘自Spring官方文档:
| 名称 | 位置 | 描述 | 示例 |
|---|---|---|---|
| methodName | root对象 | 当前被调用的方法名 | #root.methodname |
| method | root对象 | 当前被调用的方法 | #root.method.name |
| target | root对象 | 当前被调用的目标对象实例 | #root.target |
| targetClass | root对象 | 当前被调用的目标对象的类 | #root.targetClass |
| args | root对象 | 当前被调用的方法的参数列表 | #root.args[0] |
| caches | root对象 | 当前方法调用使用的缓存列表 | #root.caches[0].name |
| Argument Name | 执行上下文 | 当前被调用的方法的参数,如findArtisan(Artisan artisan),可以通过#artsian.id获得参数 | #artsian.id |
| result | 执行上下文 | 方法执行后的返回值(仅当方法执行后的判断有效,如 unless cacheEvict的beforeInvocation=false) | #result |
注意:
1.当我们要使用root对象的属性作为key时我们也可以将“#root”省略,因为Spring默认使用的就是root对象的属性。 如
@Cacheable(key = "targetClass + methodName +#p0")
2.使用方法参数时我们可以直接使用“#参数名”或者“#p参数index”。 如:
@Cacheable(value="userCache", key="#id")
@Cacheable(value="userCache", key="#p0")
SpEL提供了多种运算符
| 类型 | 运算符 |
|---|---|
| 关系 | <,>,<=,>=,==,!=,lt,gt,le,ge,eq,ne |
| 算术 | +,- ,* ,/,%,^ |
| 逻辑 | &&,||,!,and,or,not,between,instanceof |
| 条件 | ?: (ternary),?: (elvis) |
| 正则表达式 | matches |
| 其他类型 | ?.,?[…],![…],^[…],$[…] |
作者: rickiyang
出处:https://www.cnblogs.com/rickiyang/p/11074158.html
本站使用「CC BY 4.0」创作共享协议,转载请在文章明显位置注明作者及出处