【mangoDB新手教程】沙雕肥宅教你搞定mangoDB(一)
前言
本文旨在帮助mangoDB的小白初建认识。重点在于介绍mango是什么、它能做什么、有什么优势,这样在使用时哪怕不会操作,对整体的认识也能帮助自己进行有效的查证。所以具体操作和细节还得查看官方文档,或本文参考资料:
MongoDB教程 | 菜鸟教程
1. 概述
MongoDB 是一个可多机集群的分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
非关系数据库的功能往往极其有限,比如Redis并不支持查找,而MongoDB灵活丰富的功能让它作为一个非关系数据库,却是最像关系数据库的一位。

1.1 分布式系统
分布式系统(distributed system)由多机组成,并通过计算机网络连接(本地网络或广域网)通信实现整体功能。
1.2 为什么Nosql
Not Only Sql,它不仅仅是Sql。
很多数据由关系数据库来管理,这使得数据建模和应用程序编程更简单,比如JavaBean和Mysql。
但是今天可以轻松地通过第三方平台(如:Google,Facebook等)访问和抓取数据。由于用户数据和用户操作日志成倍增加,在数据挖掘中,NoSQL 数据库的发展能更好的处理这些大的数据。
1.2.1 nosql的优点
- 不需要固定的模式,高扩展性。
- 支持分布式
- 半结构数据,架构灵活
- 没有复杂的关系
1.2.2 nosql的缺点
- 没有标准化
- 查询功能有限
- 不够直观
1.2.3 nosql的种类
有很多,我只写少数几个大概对比一下
| 类型 | 举例 | 特点 |
|---|---|---|
| 文档储存 | MongoDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value储存 | Redis, Memcache | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。 |
| 列存储 | Hbase | 按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
2 什么是mongoDB
- 基于C++编写的开源分布式数据库
- 在高负载时可以通过添加结点保证服务器性能
- 库中每条数据称作一个“文档”(Document),每个文档数据都是Josn格式,由多个key-value结构的数据构成。
{
name: "一个朋友",
gender: "男性",
hobby: ["萝莉", "宅", "女装"] // 域值也可以是数组
}
![]()
2.1 主要特点
- 面向文档储存(例如上文的肥宅信息)
- 支持通过索引实现排序(索引就是将某个列按类似字典的排序展开),提高排序速度。
如果不懂索引可以看(超详细长文预警)→ 树和B+树原理及在索引中的应用【补充组合版】 - 可以创建数据镜像(支持拷贝)
- 可以多机负载,成为分片
- 支持丰富的查询,如update操作
- Mongodb中的Map/reduce可以用来进行批量处理和聚合操作。
- 支持遍历集合中的所有记录
- 支持多种语言:RUBY,PYTHON,JAVA,C++,PHP,C#等
所以,这么强大的功能还敢说是非关系数据库??Σ(っ°Д°;)っ
2.2 主要概念
这里和sql做一个简单的对比
| sql术语 | MongoDB术语 | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| index | index | 索引 |
| primary key | primary key | 主键 / 如果不设置主键,mongoDB会自动生成主键 |
| table | collection | 表 / 集合 |
| row | document | 行 / 文档 |
| column | field | 列 / 域 |
| table joins | / | 表连接 / 不支持 |
可以发现只有后四行概念不同,还是很容易理解的。至于表联合在mangoDB中体现为文档嵌套,例如大括号里还有大括号:
{
"tag": "肥宅1号",
"detail": {
"_id": ObjectId("xxxxxxxxx"),
"name": "一个朋友",
"gender": "男性",
"hobby": ["萝莉", "宅", "幻想"]
}
},
{
"tag": "肥宅2号",
"detail": {...}
},
...
而表格中提到自动生成的主键大概长这样 ↓
2.2.1 ObjectId
{
"_id": ObjectId("xxxxxxxxx"),
"name": "一个朋友",
"gender": "男性",
"hobby": ["萝莉", "宅", "幻想"]
}
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

2.2.2 集合
集合是一个文档组,相当于表,我们可以把多个文档插入集合,例如名为“肥宅”的集合含有以下文档
{"name": "肥宅", job: "程序员"}
{"name": "薯片肥宅", "hobby": "女装", "job": "程序员"}
{"name": "可乐肥宅", "hobby": "格子衫", "job": "后端"}
2.2.3 字符串和时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
2.2.4 js支持与时间
首先通过执行mongod.exe运行MongoDB服务,然后window双击mongo.exe即可进入客户端命令行。客户端支持 js 代码:
- 例如打印算式会直接得到结果
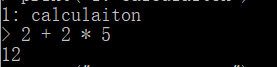
- 或者根据new Date() 和 Date()得到时间,也可以把时间存到变量再打印
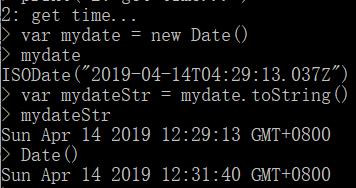
3. 基本操作一览
大致介绍mongoDB能做的事,细节就没讲太多啦

3.1 操作数据库
| 操作 | 说明 |
|---|---|
| use DATABASE_NAME | 用use切换本地数据库,如果没有则创建 |
| db | 打印当前数据库名 |
| show dbs | 查看本地所有数据库 |
| db.dropDatabase() | 先删库,后跑路 |
要注意新建的数据库如果还没有插入文档,在show dbs是不会显示的
3.2 集合
| 操作 | 说明 |
|---|---|
| db.createCollection(name, options) | 创建集合 |
| show collections | 显示集合 |
| db.collection_name.drop() | 删除指定集合 |
而创建 “集合” 也支持定制噢~

例如以下可选项:
db.createCollection(“mycol”, { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
| 选项 | 说明 |
|---|---|
| capped | 创建固定集合如果为 true,则创建固定集合。固定集合的数据不能被修改。只能查找-删除-再插入,当存储达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 指定固定集合的存储空间,单位字节 |
| max | 指定固定集合中最大文档数量 |
客官您还满意吗(娇羞)
3.3 文档
之前说过,文档就相当于mysql中的行。所有存储在集合中的数据都是BSON格式。BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
文档操作一览,参数详见 3.3.1 - 3.3.4
| 操作 | 说明 |
|---|---|
| db.collection.insert(document) | 增 |
| db.collection.remove(条件) | 删 |
| db.collection.update(条件) | 改 |
| db.collection.find() | 查 |
3.3.1 插入文档
举例
//插入文档
db.肥宅.insert({
"name": "一个朋友",
"gender": "男性",
"hobby": ["萝莉", "宅", "幻想"]
})
//也可以用js的方式,先定义document到上下文 再插入 ⁄(⁄⁄•⁄ω⁄•⁄⁄)⁄ 变量
document = ({
"name": "一个朋友",
"gender": "男性",
"hobby": ["萝莉", "宅", "幻想"]
})
db.肥宅.insert(document)
3.3.2 删除文档
语法格式如下:
db.collection.remove(
,
{
justOne: , //是否只删一条
writeConcern:
}
)
这个比较简单不再赘述,这个梗玩太久了,如果你觉得没意思也可以通过删除集合
db.肥宅.remove({})
来删除所有肥宅 (;′⌒`)
3.3.3 更新文档
①updata 方法
看起来比较复杂,大括号里是可选项
db.collection.update(
, //查询条件
, //更新规则,填入一些操作符
{
upsert: , //如果不存在该查询记录,是否创建并插入
multi: , //默认只更新查到的第一条记录,true时更新所有
writeConcern: //可选,抛出异常的级别
}
)
那么举个栗子 \\\٩(‘ω’)و////
// 方法1
db.肥宅.update(
{"age" : {$gt: 20}}, //查询条件:年龄大于20
{$set: {"tag": "资深宅"}}, //更新规则:Tag字段设为资深宅
{multi: true} //范围:多条(所有)
)
// 方法2 待更新
②save方法
save() 方法通过传入的文档来替换已有文档,没有则新增,比较像mysql里的replace。
注意: 固定集合中的文档不可修改
db.collection.save(
,
{
writeConcern: //可选,抛出异常的级别
}
)
举个栗子
>db.肥宅.save({
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"name": "一个朋友",
"gender": "男性",
"hobby": ["_装", "左右为_", "强人所_"]
})
这样就更新了id好为 56064f89ade2f21f36b03136 的肥宅数据啦
3.3.4 查询文档
| 操作 | 说明 |
|---|---|
| db.collection.find(query, projection) | 查询 |
| db.col.find().pretty() | 查询并格式化输出所有文档 |
再看看相关选项
| 选项 | 说明 |
|---|---|
| query | 可选,使用查询操作符指定查询条件,如{“age” : {$gt: 20}} |
| projection | 可选,指定文档中返回的键(不填返回所有键) |
今天到此为止。太难写了ahah,关于运算符、统计、排序、聚合敬请期待收看下期教程了~
