Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句。
如果是ROLLUP(A, B, C)的话,首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),则首先会对(A、B、C)进行GROUP BY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行GROUP BY操作。
1. 普通的group by
select trade_date, deal_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by trade_date, deal_type;
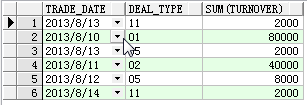
2. 使用group by rollup()单列
select trade_date, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by rollup(trade_date);
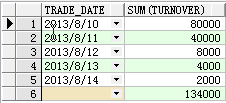
可以看到,在最后一行做了汇总。
3. 使用group by rollup()多列
select trade_date, deal_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by rollup(trade_date, deal_type);
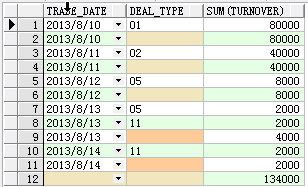
从上图可以看到:
#1.根据trade_date做了汇总;
#2.最后一行做了总的汇总。
按照rollup()的语法,是不会对deal_type做group by的。上面的SQL做了(trade_date,deal_type)的group by;(trade_date)的group by;以及对全表进行group by 操作。
如果是rollup()3列呢?
select trade_date, deal_type, deal_sub_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by rollup(deal_type, trade_date, deal_sub_type)
order by 1, 2, 3;
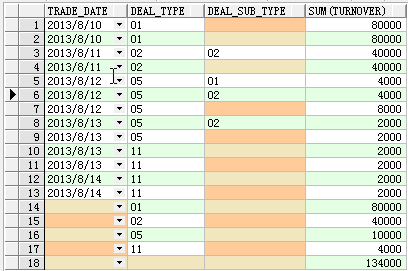
依次做了下面的group by操作:
#1.(deal_type,trade_date,deal_sub_type);这个不用解释,上图很明显。
#2.(deal_type,trade_date);第2行、第4行、第7行、第9行、第11行、第13行。
#3.(deal_type)。第14到第17行。
第18行是总的一个汇总。
4. 使用cube()单列
select trade_date, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by cube(trade_date);

跟rollup()对比,你会发现rollup()是在最后一行汇总,cube()是在第1行。
如果想在最后一行汇总,可以使用order by trade_date nulls last排序。
如下:
select trade_date, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by cube(trade_date)
order by trade_date nulls last;
5. 使用cube()多列
select trade_date, deal_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by cube(trade_date, deal_type)
order by 1 nulls last;

“order by 1 nulls last”中的1当然指的就是你查询的第1列,即trade_date了。
通过上图我们可以发现这样几点:
#1.对整体group by了。
#2.对trade_date进行group by了。
#3.对deal_type进行group by了。
#4.对整体进行汇总。
6. 使用grouping和grouping_id来标记group by的结果
select grouping(trade_date),
trade_date,
grouping(deal_type),
deal_type,
sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by cube(trade_date, deal_type)
order by 1 nulls last;
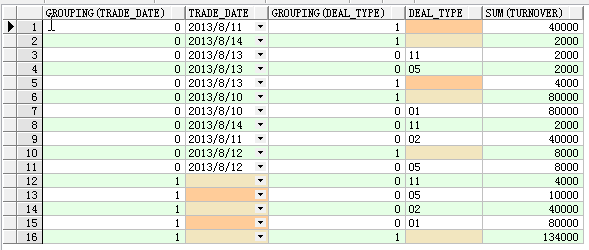
通过上图你可以发现,如果列的值为空,则显示的值为1;否则显示的0.
显示为1的就是合计的列,由此我们可以使用grouping_id来标识group by后的结果。
select decode(grouping_id(trade_date), 1, '合计', trade_date),
decode(grouping_id(deal_type), 1, '合计', deal_type),
sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by cube(trade_date, deal_type)
order by 1 nulls last;

原来合计的列显示的空白,现在都显示的“合计”。
7. 使用grouping sets
select trade_date, deal_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by grouping sets(trade_date, deal_type)
order by 1 nulls last;
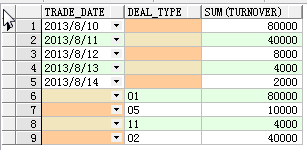
你可以看到,上面的效果不正等同于使用union all吗?
select trade_date, null, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by trade_date
union all
select null, deal_type, sum(turnover)
from test t
where t.trade_date >= date '2013-08-10'
group by deal_type;