数据分析案例实战:逻辑回归-信用卡欺诈检测
学习唐宇迪《python数据分析与机器学习实战》视频
一、数据分析
数据集部分截取: 在此数据集中,为了保护原始数据的隐私,因此,每一列(特征)的名称没有给出,用V1~V28等表示。类别是最后的Class列,有0和1两种情况,样本数为3W多个。
二、数据处理
1、读入数据并观察数据分布
import pandas as pd #数据分析
import matplotlib.pyplot as plt #画图
import numpy as np #数组矩阵运算
%matplotlib inline
#将那些用matplotlib绘制的图显示在页面里而不是弹出一个窗口
# pd.read_csv:读入文件。.py文件和数据文件放在同文件夾,可以不用指定绝对路径。
data = pd.read_csv("creditcard.csv")
#value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
#sort_index()按照索引排序
count_classes = pd.value_counts(data['Class'],sort=True).sort_index()
print(count_classes)
data.head()
#画柱状图
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")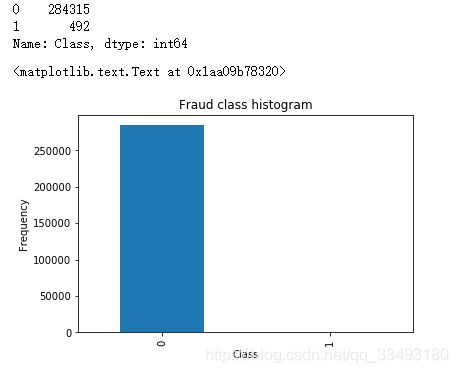
从图中可以看出,正负样本分布严重不均,需要到数据进行处理。
采用下采样和过采样两种方法来处理。
2、数据标准化
from sklearn.preprocessing import StandardScaler
#Scikit-Learn-机器学习库 非常实用的机器学习算法库,这里面包含了基本
#你觉得你能用上所有机器学习算法啦。但还远不止如此,还有很多预处理和
#评估的模块等你来挖掘的!
#标准化数据,(x-均值)/标准差,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
# fit_transform()先拟合数据,再标准化
#Series数据类型没有reshape函数 .解决办法:
#用values方法将Series对象转化成numpy的ndarray再用ndarray的reshape方法.
#reshape(-1,1):变成列向量,给定1列,自动计算多少行(-1)
#data[‘Amount’].values.reshape(-1, 1)
#print(type(data['normAmount'].values))
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1))
#去除多余的两列
data = data.drop(['Time','Amount'],axis=1)
data.head()
3、下采样策略处理数据
#提取所有特征所在列
x = data.ix[:,data.columns!='Class']
#提取类别所在列,class列
y = data.ix[:,data.columns=='Class']
#.loc[],通过选取行(列)标签索引数据
#.iloc[],通过选取行(列)位置编号索引数据
#.ix[],既可以通过行(列)标签索引数据,也可以通过行(列)位置编号索引数据
#计算class==1的样本数量 并 取出对应的索引值并转换成数组
number_records_fraud = len(data[data.Class==1])
fraud_indices = np.array(data[data.Class==1].index)
print(type(fraud_indices))
print(type(data[data.Class==1].index))
#取出class=0的索引值
normal_indices = np.array(data[data.Class==0].index)
#在normal_indices中随机选择number_records_fraud 数量的样本
#replace = True 在一次抽取中,抽取的样本可重复出现
random_normal_indices = np.random.choice(normal_indices, number_records_fraud,replace=False)
print(type(random_normal_indices))
#randon_normal_indices = np.array(random_normal_indices)
#print(type(random_normal_indices))
#合并随机选择的样本和原有的=1的样本个数,这里传入的是两个索引
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
#iloc基于索引位来选取数据集
#下采样完后的总数据
under_sample_data = data.iloc[under_sample_indices,:]
#提取特征和标签
x_undersample = under_sample_data.ix[:,under_sample_data.columns!='Class']
y_undersample = under_sample_data.ix[:, under_sample_data.columns=='Class']
#打印下采样后正负样本的比例
print('Percentage of normal transactions:',len(under_sample_data[under_sample_data.Class==0])/len(under_sample_data))
print('Percentage of fraud transactions:',len(under_sample_data[under_sample_data.Class==1])/len(under_sample_data))
print("Total number of transactions in resampled data: ",len(under_sample_data))
4、将数据切分成训练集和测试集
#交叉验证
#from sklearn.cross_validation import train_test_splitsklearn更新后在执行以上代码时会报错
from sklearn.model_selection import train_test_split
#对原始数据集也做交叉验证
#test_size:测试集的比例 random_state:随机切分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size = 0.3,random_state=0)
print("Number transactions train dataset:",len(x_train))
print("Number transactions test dataset:",len(x_test))
print("Total number of transactions:",len(x_train)+len(x_test))
#对下采样数据集也做交叉验证
x_train_undersample,x_test_undersample,y_train_undersample,y_test_undersample = train_test_split(x_undersample,y_undersample,test_size=0.3,random_state=0)
print("")
print("Number transactions train dataset:",len(x_train_undersample))
print("Number transactions test dataset:",len(x_test_undersample))
print("Total number of transactions:",len(x_train_undersample)+len(x_test_undersample))
5、交叉验证
#模型评估方法
#查全率Recall=TP/(TP+FN)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold,cross_val_score
#sklearn.model_selection代替原代码sklearn.cross_validation.
from sklearn.metrics import confusion_matrix,recall_score,classification_report
#confusion_matrix:混淆矩阵;recall_score = TP/(TP+FN)以上这段代码本身是没有问题的,但由于库版本的原因,有的人在运行这段代码后,出现以下错误: ModuleNotFoundError: No module named 'sklearn.cross_validation' 为此他将from sklearn.cross_validation import KFold改为from sklearn.model_selection import KFold,再运行却发现有了新的问题: TypeError: init() got multiple values for argument 'shuffle' 这是为什么呢?其实这是导入 KFold的方式不同引起的。如果你这样做:from sklearn.cross_validation import KFold,那么: KFold(n,5,shuffle=False) # n为总数,需要传入三个参数 但如果你这样做:from sklearn.model_selection import KFold,那么: fold = KFold(5,shuffle=False) # 无需传入n
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(5,shuffle=False) # 5折交叉验证
print(fold)
#k_fold = KFold(n=6, n_folds=3)
#Train: [2 3 4 5] | test: [0 1]
#Train: [0 1 4 5] | test: [2 3]
#Train: [0 1 2 3] | test: [4 5]
#正则化惩罚项
c_param_range = [0.01,0.1,1,10,100]#惩罚力度
results_table = pd.DataFrame(index = range(len(c_param_range),2),columns = ['C_parameter'])
results_table['C_parameter']=c_param_range
# the k-fold will give 2 lists: train_indices = indices[0], test_indices = indices[1]
j = 0
for c_param in c_param_range:
print('-------------------------------------------')
print('C parameter:',c_param)
print('-------------------------------------------')
print('')
recall_accs=[]
for iteration,indices in enumerate(fold.split(y_train_data),start=1):
#实例化模型
lr = LogisticRegression(C=c_param,penalty='l1',solver='liblinear')
# Use the training data to fit the model. In this case, we use the portion of the fold to train the model
# with indices[0]. We then predict on the portion assigned as the 'test cross validation' with indices[1]
#训练,第一个参数:特征矩阵X,第二个参数:标签矩阵y,ravel():转化为1维数组
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
#使用训练数据中的测试集预测
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
#计算查全率并将其加到表示当前c_parameter的查全率列表中
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
recall_accs.append(recall_acc)
print('Iteration',iteration,': recall score= ',recall_acc)
results_table.ix[j,'Mean recall score'] = np.mean(recall_accs)
j+=1
print("")
print('Mean recall score',np.mean(recall_accs))
print("")
#best_c = results_table
#best_c.dtypes.eq(object)
#new = best_c.columns[best_c.dtypes.eq(object)]
#best_c[new] = best_c[new].apply(pd.to_numeric,errors='coerce',axis=0)
#.idxmax()最大值的索引值
best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_parameter']
#最后,我们可以检查哪个c参数(惩罚力度)是最好的选择
print('*********************************************************************************')
print('Best model to choose from cross validation is with C parameter=',best_c)
print('*********************************************************************************')
return best_c
best_c=printing_Kfold_scores(x_train_undersample,y_train_undersample)
6、混淆矩阵
def plot_confusion_matrix(cm,classes,title="Confusion matrix",cmap=plt.cm.Blues):
'''
此函数打印并绘制混淆矩阵
'''
plt.imshow(cm, interpolation='nearest', cmap=cmap)
#cm变量存储图像
#参数cmap用于设置热图的Colormap
#通常图片都是由RGB组成,一块一块的,
#这里想把某块显示成一种颜色,则需要调用interpolation='nearest'
plt.title(title)
plt.colorbar()#增加颜色类标的代码是plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max()/2.
for i,j in itertools.product(range(cm.shape[0]),range(cm.shape[1])):
plt.text(j,i,cm[i,j],horizontalalignment='center',color='white' if cm[i,j]>thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')下采样数据集:
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(x_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(x_test_undersample.values)
#计算混淆矩阵(下采样数据集)
cnf_matrix=confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)#设置输出精度
print("Recall metric in the testing dataset:",cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names=[0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix,classes=class_names,title='Confusion matrix')
plt.show()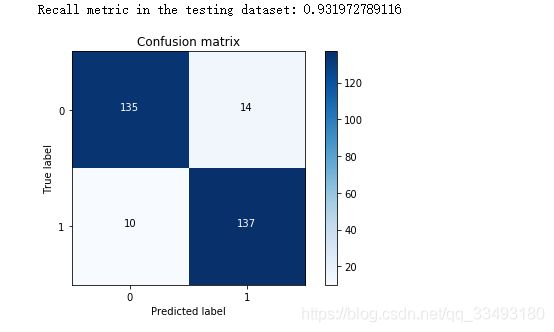
原始数据集:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(x_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(x_test.values)
# 计算混淆矩阵(原始数据集)
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix,classes=class_names,title='Confusion matrix')
plt.show()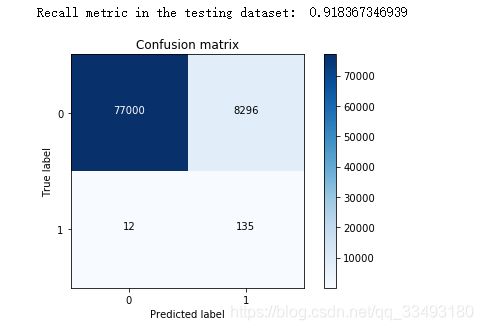
对比发现下采样建立的模型虽然查全率较好, 但是在原始中发现误杀的比例较多, 也就是精度大大降低了 如果不做下采样, 直接对原始数据进行验证, 看看查全率如何
best_c = printing_Kfold_scores(x_train,y_train)
7、改变阈值
改变阈值来观察效果(sogmoid一般是0.5)
lr = LogisticRegression(C = 0.01, penalty = 'l1')
lr.fit(x_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample_proba = lr.predict_proba(x_test_undersample.values)
# 一般默认使用的阈值是0.5, 现在手动指定阈值
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plot_confusion_matrix(cnf_matrix,classes=class_names,title='Threshold >= %s'%i)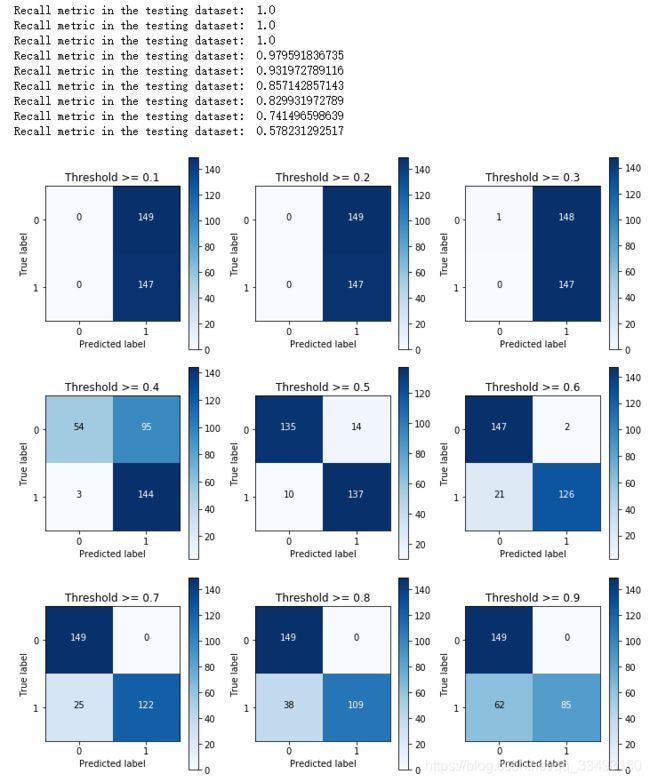
由此发现, 随着阈值的上升, recall值在降低, 也就是判断信用卡欺诈的条件越来越严格.并且阈值取0.5,0.6时相对效果较好
8、过采样策略处理数据
SMOTE样本生成
import pandas as ad
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
# The labels are in the last column ('Class'). Simply remove it to obtain features columns
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,labels,test_size=0.2,random_state=0)
#生成SMOTE模型
oversampler=SMOTE(random_state=0)
#训练
os_features,os_labels=oversampler.fit_sample(features_train,labels_train)
len(os_labels[os_labels==1])
os_features=pd.DataFrame(os_features)
os_labels=pd.DataFrame(os_labels)
best_c=printing_Kfold_scores(os_features,os_labels)
lr = LogisticRegression(C = best_c, penalty = 'l1')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix,classes=class_names,title='Confusion matrix')
plt.show()