python+request+unittest+ddt+HTMLTestRunner自动化测试框架项目实战
首先我们要从开发手上拿到接口测试文档,下面我们要开始我们的一个python+request+unittest+ddt+HTMLTestRunner自动化测试框架,本人新手,如果写的不对,希望得到建议。
1.创建项目、包、库、配置文件、文件夹
123 项目名称,起个好听的名字
-------------data 文件夹,存放测试用例(Excel格式)
-------------demo 包,放一些的案例、demo
---------------------course 课程管理相关的demo
---------------------login 登录相关的demo
---------------------other 其他案例demo
-------------lib 包,存放公共的函数、类
-------------report 文件夹,存放生成的测试报告
-------------testCase 包,存放测试用例
---------------------course 包,课程管理模块测试用例
---------------------teacher 包,教师管理模块测试用例
-------------config.py 配置文件
-------------doReport.py 执行生成报告
2. 在demo文件夹,创建接口文档对应的接口请求
目的是间接评审接口文档。确保每个接口请求都是正确的,下面我写个demo_add的例子
import requests
from config import HOST
from lib.loginLib import login
session=login('xxxxxxxxx','xxxxxxxx')
dict1={'Content-Type':'application/x-www-form-urlencoded'}
payload={
}
cookie={'sessionid':session}
r=requests.post(f"{HOST}xxxxxxxxxxx"
,headers=dict1,data=payload,cookies=cookie
)
print(r.text)
根据返回值比较接口文档确保写的没有问题,为下面的环节节约时间。
3. 在config.py 配置文件中,定义全局变量
定义全局变量的目的方便维护。
4.在lib包目录下,定义函数
• 实现课程管理模块:courseLib.py
定义新增课程[add]、列出课程[list]、修改课程[modfy]、删除课程[delete]函数
修改demo,添加函数调用
• 实现用户登录模块:loginLIb.py
定义login函数
下面我来写的courseLib.py
import requests
from config import HOST
import pprint
from lib.loginLib import login
# 新增课程1
def add(name,desc,display_idx,SessionID):
dict1 = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {
}
cookie={'sessionid':SessionID}
try:
r = requests.post(f"{HOST}xxxxxxxxxxxxxxxxxxx"
, headers=dict1, data=payload,cookies=cookie
)
return r.json()
except:
return {'retcode':999,'reason':'异常情况'}
#2.列出课程
def list(pagenum,pagesize,SessionID):
payload = {
}
cookie = {'sessionid': SessionID}
try:
r = requests.get(f'{HOST}XXXXXXXXXXXXXXXXXX', params=payload,cookies=cookie)
return r.json()
except:
return {'retcode': 999, 'reason': '异常情况'}
#3. 删除课程
def delete(id,SessionID):
header = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = { }
cookie = {'sessionid': SessionID}
try:
r = requests.delete(f'{HOST}XXXXXXXXXXXXXXXX', headers=header, data=payload,cookies=cookie)
return r.json()
except:
return {'retcode': 999, 'reason': '异常情况'}
#4.修改课程
def modify(id,name,desc,display_idx,SessionID):
header = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {
}
cookie = {'sessionid': SessionID}
try:
r = requests.put(f'{HOST}XXXXXXXXXXXXX', headers=header, data=payload,cookies=cookie)
return r.json()
except:
return {'retcode': 999, 'reason': '异常情况'}
#5.新增课程2
def add2(name,desc,display_idx,SessionID):
dict1 = {'Content-Type': 'application/json'}
payload = f'''
{{
}}
}}
'''
cookie = {'sessionid': SessionID}
try:
r = requests.post(f'{HOST}XXXXXXXXXXXXXXXXXXX', headers=dict1,
data=payload.encode(encoding='UTF-8'),cookies=cookie)
return r.json()
except:
return {'retcode': 999, 'reason': '异常情况'}
到这里简单的测试接口已经完毕了,下面我们可能拿到如下一个表

我们要开始做我们的工作了,思路是这样的:我们先要利用python语言找到这个Excel表,然后再在这个表里找到这个工作簿,从上面的图片我们可以看出这个就是一个简单的测试用例表,我们要做的是根据调用方法,和请求参数,得出执行结果。
下面我们做第一个工作:工作表进行循环-逐行取出数据–放入列表中。
这时候我们要利用到python的一个库xlrd
import xlrd
from xlutils.copy import copy
def readExcel(filePath,sheet_index):
print(filePath)
# 1-1 打开Excel,获取【workBook】 对象
workBook = xlrd.open_workbook(filePath)
print(workBook.sheet_names())
# 1-2 从工作簿中,获取【workSheet】对象
workSheet = workBook.sheet_by_index(sheet_index)
# workSheet =workBook.sheet_by_name('课程管理')
# 1-4得到工作表中的数据总行数
nrows = workSheet.nrows
print(nrows)
listDate = []
# 1-5 对【workSheet】工作表进行循环-逐行取出数据--放入列表中
for i in range(1, nrows):
row = workSheet.row_values(i)
listDate.append(row)
# 1-6 返回数据列表
return listDate
def getNewExcel(filePath):
# 1-1 打开Excel,得到workBook 对象
workBook = xlrd.open_workbook(filePath, formatting_info=True)
# 1-2 复制一个全新的工作簿
workBookNew = copy(workBook)
return workBookNew
list=readExcel(r'C:/Users/caowei/PycharmProjects/api/data/教管系统-测试用例V1.2.xls',2)
print(list)
这样我们就可以把工作簿所有的内容以列表的形式生成,方面我们下面对数据的操作。
再根据这张图我们需要每一行的第4数据进行判断接口请求类型,第5数据输入,再根据第6元素判断,然后我们还要把生成的结果,和不通过的原因放到第7,8列.
from lib.excelManage import readExcel
import json
from lib.courseLib import add,add2,list,delete,modify
import time
def SendCrourseRequest(row,sessionID):
# print(row)
# 1.取到第六列的请求参数
data = json.loads(row[5])
# print(data)
# 2.定义一个空的返回列表
dictBody=[]
if (row[4]=='add'):
# 定义一个随机变量
randomStr = str(int(time.time() * 10000))
# 从请求参数中获取课程名称
courseName=data['name']
# 把课程名称带变量标记的,替换为随机变量
courseName=(courseName).replace('{{courseName}}',randomStr)
# 发送课程新增请求
dictBody=add(courseName,data['desc'],data['display_idx'],sessionID)
elif (row[4]=='list'):
dictBody =list(data['pagenum'],data['pagesize'],sessionID)
elif (row[4]=='delete'):
dictBody = delete(data['id'],sessionID)
# return 结果
return dictBody
doExcel.py写入测试结果
from lib.excelManage import readExcel,getNewExcel
from lib.sendCourseRequset import SendCrourseRequest
import time
from xlutils.copy import copy
import xlrd
import json
#读取测试用例
path=r'C:/Users/caowei/PycharmProjects/api/data/教管系统-测试用例V1.2.xls'
savepath=r'C:/Users/caowei/PycharmProjects/api/report/教管系统11.xls'
list=readExcel(path,0)
#复制一个全新的工作簿
workbooknew=getNewExcel(path)
#得到工作表
workSheet=workbooknew.get_sheet(0)
#执行测试用例
#dictBobys=[]
for i in range(0,len(list)):
row=list[i]
dictBoby=SendCrourseRequest(row)
#dictBobys.append(dictBoby)
time.sleep(0.001)
#写到7,8行
test = json.loads(row[6])
if(dictBoby['retcode']==test['code']):
print(row[0],'测试通过')
#i+1(不包括标题)
workSheet.write(i+1,7,'pass')
else:
print(row[0], '测试不通过')
# i+1(不包括标题)
workSheet.write(i + 1, 7, 'fail')
#判断reason在dictBoby
if 'reason' in dictBoby.keys():
workSheet.write(i + 1, 8, dictBoby['reason'])
#保存
workbooknew.save(savepath)
这时候我们发现我们缺少环境清除这个步骤,这个时候我们运用到了unittest框架
我来写一个简单的unittest构成`
class UnittesDemo(unittest.TestCase):
#初始化方法
@classmethod
def setUpClass(cls):
print('setup类方法运行')
#清除方法
@classmethod
def tearDownClass(cls):
print('tearDown类方法运行')
def setUp(self):
print('setup方法运行')
def tearDown(self):
print('tearDown方法运行')
#想要跳过这个测试用例
@unittest.skip('不想执行的原因')
def test_001(self):
#断言判断
self.assertEqual(1,2,'测试不通过')
print('1运行')
def test_002(self):
print('2运行')
def test_003(self):
print('3运行')
def test_004(self):
print('4运行')
根据这个我们来写写我们这个的写法运用到ddt数据驱动
from lib.loginLib import login
from lib.courseLib import list,delete
path=r'C:/Users/caowei/PycharmProjects/api/data/教管系统-测试用例V1.2.xls'
mydata=readExcel(path,0)
@ddt
class UnittestDemo4(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.sessionID=login('auto','sdfsdfsdf')
# 1-方式一 调用删除方法删除
cls.clearData()
# 2-方式二 直接从数据库表中删除
# delete * from 表名 where 用户id='xxxxxxxxx'
@classmethod
def tearDownClass(cls):
cls.clearDate()
# 6. 批量执行excel测试用例
@data(*mydata)
def test_006(self,row):
# print(row)
dictBody = SendCrourseRequest(row,self.sessionID)
time.sleep(0.001)
test = json.loads(row[6])
print('>>>>用例6运行了')
if 'reason' in dictBody.keys():
self.assertEqual(dictBody['retcode'], test['code'],dictBody['reason'])
else:
self.assertEqual(dictBody['retcode'], test['code'])
# 1-方式一 调用删除方法删除
@classmethod
def clearData(cls):
listCourse = list(1, 999,cls.sessionID)
for course in listCourse['retlist']:
delete(course['id'],cls.sessionID)
assertEqual判断方法
1.1 UnitTest概念与用法
• UnitTest是python自带的单元测试框架, 主要适用于单元测试,可以对多个测试用例进行管理和封装
• UnitTest 也叫 PyUnit,它提供了很多类和方法来处理各种测试工作
• 测试用例----testcase
测试用例必须在类中
测试用例所在的类,必须继承TestCase
测试用例的方法名称必须以test开头
测试用例的执行顺序,按照Ascill码顺序(09,AZ,a~z)
利用父类TestCase的assertXXXX方法来断言
用@unittest.skip(reason)装饰来跳过测试用例
• 测试固件----testfixture
也叫测试夹件,主要工作是【初始化和善后】
测试固件分为两种,一种是类级别的,一种是方法级别的
类级别的测试固件,所有测试用例执行之前与之后运行一次
方法级别的测试固件,每个测试用例执行之前与之后都运行一次
• 测试套件----testsuite
是用来组织测试用例的
如:
方法一:用例逐个添加到suite
suite = unittest.TestSuite()
suite.addTest(MyTest200(“test_203”))
suite.addTest(MyTest200(“test_201”))
方法二:用例放入列表中,再添加到suite
suite = unittest.TestSuite()
list=[类名1(“方法名1”),类名2(“方法名2”)]
suite.addTests(list)
方法三:通过TestLoader类的discover 方法来
unittest.defaultTestLoader.discover(‘用例所在的模块’, pattern=“通配.py”)
discover(start_dir,pattern=‘test*.py’,top_level_dir=None)
-case_dir:这个是待执行用例的目录。
-pattern:这个是匹配脚本名称的规则,test*.py 意思是匹配 test 开头的所有脚本。
-top_level_dir:这个是顶层目录的名称,一般默认等于 None 就行了。
• 测试运行器----testrunner
是用来执行测试用例的
runner=unittest.TextTestRunner() #实例化TestRunner类
runner.run(suite)#执行用例
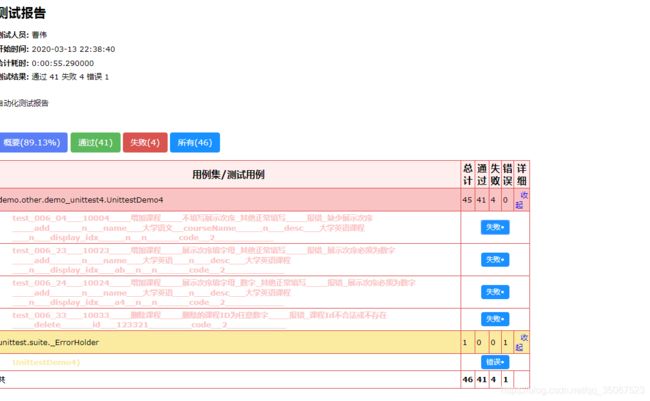
1.2 HtmlTestRunner 生成报告
• 经典报告:
reportFile=open(’./report/经典Html报告3.html’,‘wb’)
代码如下
import ddt
import unittest
from demo.other.demo_unittest import UnittesDemo
from ClassicHTMLTestRunner import HTMLTestRunner
#执行测试用例
#suite = unittest.TestSuite()
#方法一:用例逐个添加到suite
# suite.addTest(UnittesDemo('test_003'))
#2
suite=unittest.defaultTestLoader.discover('demo.other',pattern='demo_unittest4.py')
3
# list=[UnittesDemo('test_001'),UnittesDemo('test_002')]
# suite.addTest(list)
#测试运行器testrunner
# runner=unittest.TextTestRunner()
# runner.run(suite)
#使用HTMLrunner
reportfile=open(r'C:/Users/caowei/PycharmProjects/api/report/HTML报告22.html','wb')
runner=HTMLTestRunner(tester='曹伟',title=' 测试报告',description='自动化测试报告',stream=reportfile,verbosity=2)
runner.run(suite)