史上最全的C++面试宝典(合集)
参考:https://www.runoob.com/cplusplus/cpp-tutorial.html
本教程旨在提取最精炼、实用的C++面试知识点,供读者快速学习及本人查阅复习所用。
目录
第一章 C++基本语法
1.1 C++程序结构
1.2 命名空间
1.3 预处理器
1.4 相关面试题
第二章 C++数据操作
2.1 数据类型
2.2 变量
2.3 常量
2.4 类型限定符
2.5 存储类
2.6 运算符
2.7 相关面试题
第三章 指针和引用
3.1 指针
3.2 引用
3.3 相关面试题
第四章 函数——C++的编程模块
4.1 函数的定义与声明
4.2 内联函数
4.3 重载
4.4 模板
4.5 相关面试题
第五章 结构体、类与对象
5.1 结构体
5.2 类和对象
5.3 数据抽象与封装
5.4 继承
5.5 多态
5.6 相关面试题
第六章 动态内存
6.1 new和delete运算符
6.2 动态内存分配
6.3 相关面试题
第七章 C++ STL(标准模板库)
7.1 容器
7.2 相关面试题
第八章 异常处理
8.1 抛出异常
8.2 捕获异常
8.3 C++标准的异常
8.4 定义新的异常
第九章 多线程
9.1 基本概念
9.2 C++线程管理
9.3 线程的同步与互斥
9.4 C++中的几种锁
9.5 C++中的原子操作
9.6 相关面试题
第一章 C++基本语法
C++ 程序可以定义为对象的集合,这些对象通过调用彼此的方法进行交互。
- 对象 - 对象具有状态和行为。例如:一只狗的状态 - 颜色、名称、品种,行为 - 摇动、叫唤、吃。
- 类 - 类可以定义为描述对象行为/状态的模板,对象是类的实例。
- 方法 - 从基本上说,一个方法表示一种行为。一个类可以包含多个方法。可以在方法中写入逻辑、操作数据等动作。
- 即时变量 - 每个对象都有其独特的即时变量。
1.1 C++程序结构
下面给出一段基础的C++程序:
#include
using namespace std;
// main() 是程序开始执行的地方
int main()
{
cout << "Hello World" << endl; // 输出 Hello World
return 0;
}
这段程序主要结构如下:
- C++ 语言定义了一些头文件,这些头文件包含了程序中必需的或有用的信息。上面这段程序中,包含了头文件
- using namespace std; 告诉编译器使用 std 命名空间。
- int main() 是主函数,程序从这里开始执行。
1.2 命名空间
- 命名空间这个概念可作为附加信息来区分不同库中相同名称的函数、类、变量等。
- 使用了命名空间即定义了上下文,本质上,命名空间就是定义了一个范围。
1.2.1 定义命名空间
下面通过一个示例来展示如何定义命名空间并使用命名空间中的函数等。
#include
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
}
1.2.2 using指令
可以使用 using namespace xxxx指令,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
1.3 预处理器
预处理器是一些指令,指示编译器在实际编译之前所需完成的预处理。所有的预处理器指令都是以井号(#)开头,只有空格字符可以出现在预处理指令之前。预处理指令不是 C++ 语句,所以它们不会以分号(;)结尾。
1.3.1 #define预处理
#define 预处理指令用于创建符号常量。该符号常量通常称为宏,指令的一般形式是:
#define macro-name replacement-text
//例如
#define PI 3.14159
可以使用 #define 来定义一个带有参数的参数宏,如下所示:
#include
using namespace std;
#define MIN(a,b) (a 1.3.2 条件编译
有几个指令可以用来有选择地对部分程序源代码进行编译。这个过程被称为条件编译。
条件预处理器的结构与 if 选择结构很像。请看下面这段预处理器的代码:
#ifndef NULL
#define NULL 0
#endif
例如,要实现只在调试时进行编译,可以使用一个宏来实现,如下所示:
#ifdef DEBUG
cerr <<"Variable x = " << x << endl;
#endif
使用 #if 0 语句可以注释掉程序的一部分,如下所示:
#if 0
不进行编译的代码
#endif
下面给出一个示例:
#include
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main ()
{
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* 这是注释部分 */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Trace: Inside main function
The minimum is 30
Trace: Coming out of main function
1.4 相关面试题
Q:C++和C的区别
A:设计思想上:
- C++是面向对象的语言,而C是面向过程的结构化编程语言
语法上:
- C++具有封装、继承和多态三种特性
- C++相比C,增加多许多类型安全的功能,比如强制类型转换
- C++支持范式编程,比如模板类、函数模板等
Q:include头文件双引号””和尖括号<>的区别
A:编译器预处理阶段查找头文件的路径不一样:
- 对于使用尖括号包含的头文件,编译器从标准库路径开始搜索
- 对于使用双引号包含的头文件,编译器从用户的工作路径开始搜索
Q:头文件的作用是什么?
A:
- 通过头文件来调用库功能。
- 头文件能加强类型安全检查。
Q:在头文件中进行类的声明,在对应的实现文件中进行类的定义有什么意义?
A:这样可以提高编译效率,因为分开的话,这个类只需要编译一次生成对应的目标文件,以后在其他地方用到这个类时,编译器查找到了头文件和目标文件,就不会再次编译这个类,从而大大提高了效率。
Q:C++源文件从文本到可执行文件经历的过程
A:对于C++源文件,从文本到可执行文件一般需要四个过程:
- 预编译阶段:对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件
- 编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件
- 汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件
- 链接阶段:将多个目标文件及所需要的库链接成最终的可执行目标文件
Q:静态链接与动态链接
A:静态链接是在编译期间完成的。
- 静态链接浪费空间 ,这是由于多进程情况下,每个进程都要保存静态链接函数的副本。
- 更新困难 ,当链接的众多目标文件中有一个改变后,整个程序都要重新链接才能使用新的版本。
- 静态链接运行效率高。
动态链接的进行则是在程序执行时链接。
- 动态链接当系统多次使用同一个目标文件时,只需要加载一次即可,节省内存空间。
- 程序升级变得容易,当升级某个共享模块时,只需要简单的将旧目标文件替换掉,程序下次运行时,新版目标文件会被自动装载到内存并链接起来,即完成升级。
Q:C++11有哪些新特性
A:
- auto关键字:编译器可以根据初始值自动推导出类型,但是不能用于函数传参以及数组类型的推导;
- nullptr关键字:nullptr是一种特殊类型的字面值,它可以被转换成任意其它的指针类型;而NULL一般被宏定义为0,在遇到重载时可能会出现问题。
- 智能指针:C++11新增了std::shared_ptr、std::weak_ptr等类型的智能指针,用于解决内存管理的问题。
- 初始化列表:使用初始化列表来对类进行初始化
- 右值引用:基于右值引用可以实现移动语义和完美转发,消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率
- atomic原子操作用于多线程资源互斥操作
- 新增STL容器array以及tuple
Q:assert()是什么
A:断言是宏,而非函数。assert 宏的原型定义在
(C)、 (C++)中,其作用是如果它的条件返回错误,则终止程序执行。可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include 之前。 #define NDEBUG // 加上这行,则 assert 不可用 #includeassert( p != NULL ); // assert 不可用
Q:C++是不是类型安全的?
A:不是,因为两个不同类型的指针之间可以强制转换(用reinterpret cast)。
Q:系统会自动打开和关闭的3个标准的文件是?
A:
- 标准输入----键盘---stdin
- 标准输出----显示器---stdout
- 标准出错输出----显示器---stder
第二章 C++数据操作
2.1 数据类型
2.1.1 基本类型
C++有7种基本的数据类型:
 基本数据类型
基本数据类型
可以使用signed,unsigned,short,long去修饰这些基本类型:
 类型及大小
类型及大小
2.1.2 typedef
可以使用 typedef 为一个已有的类型取一个新的名字。例如:
//typedef type newname;
typedef int feet;
feet distance
typedef struct Student {
int age;
} S;
S student;
2.2 变量
2.2.1 变量定义
//type variable_name = value;
extern int d = 3, f = 5; // d 和 f 的声明
int d = 3, f = 5; // 定义并初始化 d 和 f
byte z = 22; // 定义并初始化 z
char x = 'x'; // 变量 x 的值为 'x'
2.2.2 变量声明
可以使用extern关键字在任意地方声明一个变量。
// 变量声明
extern int a, b;
extern float f;
int main ()
{
// 变量定义
int a, b;
float f;
return 0;
}
同样的,函数声明是,提供一个函数名即可,而函数的实际定义则可以在任何地方进行。
// 函数声明
int func();
int main()
{
// 函数调用
int i = func();
}
// 函数定义
int func()
{
return 0;
}
2.2.3 变量作用域
- 在函数或一个代码块内部声明的变量,称为局部变量。
- 在函数参数的定义中声明的变量,称为形式参数。
- 在所有函数外部声明的变量,称为全局变量。
注:当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动初始化为下列值:
 变量初始化
变量初始化
2.3 常量
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
2.3.1 define预处理器
下面是使用 #define 预处理器定义常量的形式:
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
2.3.2 const关键字
可以使用 const 前缀声明指定类型的常量,const类型的对象在程序执行期间不能被修改。如下所示:
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
2.4 类型限定符
2.4.1 volatile
volatile 用来修饰变量,表明某个变量的值可能会随时被外部改变,因此使用 volatile 告诉编译器不应对这样的对象进行优化(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值;而被volatile修饰的变量,它不能被缓存到寄存器,每次访问需要到内存中重新读取)。
volatile int n = 10;2.4.2 restrict
由 restrict 修饰的指针是唯一一种访问它所指向的对象的方式。
2.5 存储类
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。
2.5.1 auto存储类
auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断该变量的类型、声明函数时函数返回值的占位符。
2.5.2 static存储类
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。
- 使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
- 当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
- 在 C++ 中,当 static 用在类数据成员上时,会导致仅有一个该成员的副本被类的所有对象共享。
2.5.3 extern存储类
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。通常用于当有两个或多个文件共享相同的全局变量或函数的时候。
2.6 运算符
 算数运算符
算数运算符
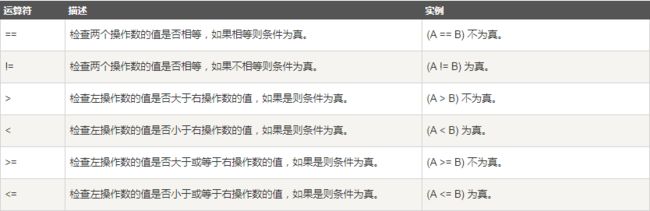 关系运算符
关系运算符
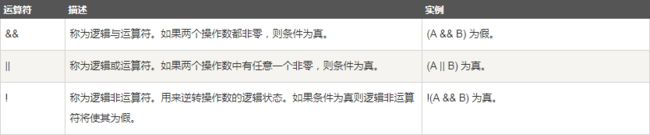 逻辑运算符
逻辑运算符
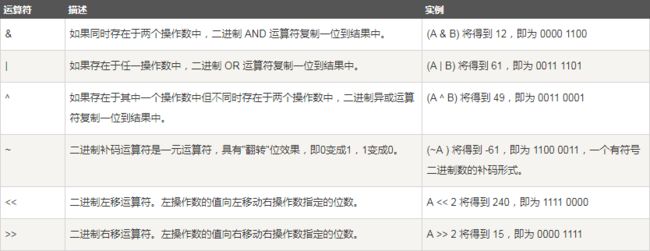 位运算符
位运算符
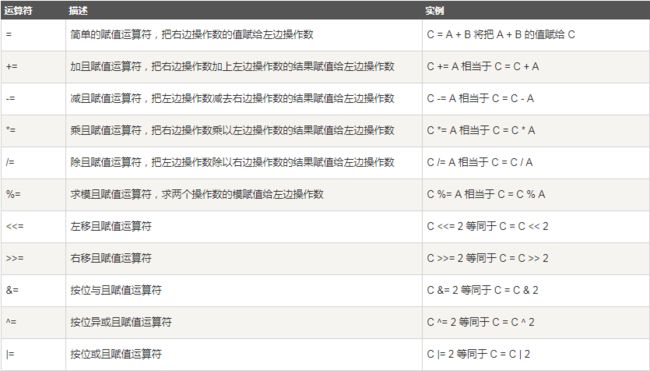 赋值运算符
赋值运算符
 杂项运算符
杂项运算符
 运算符优先级
运算符优先级
2.7 相关面试题
Q:const的作用
A:
- 修饰变量,说明该变量不可以被修改
- 修饰指针,即常量指针和指针常量
- 常量引用,经常用于形参类型,既避免了拷贝,又避免了函数对值的修改
- 修饰类的成员函数,说明该成员函数内不能修改成员变量
// 类 class A { private: const int a; // 常对象成员,只能在初始化列表赋值 public: // 构造函数 A() : a(0) { }; A(int x) : a(x) { }; // 初始化列表 // const可用于对重载函数的区分 int getValue(); // 普通成员函数 int getValue() const; // 常成员函数,不得修改类中的任何数据成员的值 }; void function() { // 对象 A b; // 普通对象,可以调用全部成员函数、更新常成员变量 const A a; // 常对象,只能调用常成员函数 const A *p = &a; // 常指针 const A &q = a; // 常引用 // 指针 char greeting[] = "Hello"; char* p1 = greeting; // 指针变量,指向字符数组变量 const char* p2 = greeting; // 常量指针即常指针,指针指向的地址可以改变,但是所存的内容不能变 char const* p2 = greeting; // 与const char* p2 等价 char* const p3 = greeting; // 指针常量,指针是一个常量,即指针指向的地址不能改变,但是指针所存的内容可以改变 const char* const p4 = greeting; // 指向常量的常指针,指针和指针所存的内容都不能改变,本质是一个常量 } // 函数 void function1(const int Var); // 传递过来的参数在函数内不可变 void function2(const char* Var); // 参数为常量指针即指针所指的内容为常量不能变,指针指向的地址可以改变 void function3(char* const Var); // 参数为指针常量 void function4(const int& Var); // 参数为常量引用,在函数内部不会被进行修改,同时参数不会被复制一遍,提高了效率 // 函数返回值 const int function5(); // 返回一个常数 const int* function6(); // 返回一个指向常量的指针变量即常量指针,使用:const int *p = function6(); int* const function7(); // 返回一个指向变量的常指针即指针常量,使用:int* const p = function7();
Q:说明define和const在语法和含义上有什么不同?
A:
- #define是C语法中定义符号变量的方法,符号常量只是用来表达一个值,在编译阶段符号就被值替换了,它没有类型;
- const是C++语法中定义常变量的方法,常变量具有变量特性,它具有类型,内存中存在以它命名的存储单元,可以用sizeof测出长度。
Q:static关键字的作用
A:静态变量在程序执行之前就创建,在程序执行的整个周期都存在。可以归类为如下五种:
- 局部静态变量:作用域仅在定义它的函数体或语句块内,该变量的内存只被分配一次,因此其值在下次函数被调用时仍维持上次的值;
- 全局静态变量:作用域仅在定义它的文件内,该变量也被分配在静态存储区内,在整个程序运行期间一直存在;
- 静态函数:在函数返回类型前加static,函数就定义为静态函数。静态函数只是在声明他的文件当中可见,不能被其他文件所用;
- 类的静态成员:在类中,静态成员属于整个类所拥有,对类的所有对象只有一份拷贝,因此可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性;
- 类的静态函数:在类中,静态成员函数不接收this指针,因而只能访问类的static成员变量,如果静态成员函数中要引用非静态成员时,可通过对象来引用。(调用静态成员函数使用如下格式:<类名>::<静态成员函数名>(<参数表>);)
Q:请你来说一下C++里是怎么定义常量的?常量存放在内存的哪个位置?
A:常量在C++里使用const关键字定义,常量定义必须初始化。对于局部对象,常量存放在栈区;对于全局对象,编译期一般不分配内存,放在符号表中以提高访问效率;对于字面值常量,存放在常量存储区。
Q:sizeof()和strlen()
A:sizeof是运算符,能获得保证能容纳实现所建立的最大对象的字节大小:
- sizeof 对数组,得到整个数组所占空间大小;
- sizeof 对指针,得到指针本身所占空间大小(4个字节);
- 当一个类A中没有生命任何成员变量与成员函数,这时sizeof(A)的值是1。
strlen()是函数,可以计算字符串的长度,直到遇到结束符NULL才结束,返回的长度大小不包含NULL。
Q:C++ 字节对齐
A:定义:字节按照一定的规律在空间上排列。现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
使用原因:不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放;同时,如果不按照平台要求对存放数据进行对齐,会带来存取效率上的损失。
Q:强制类型转换运算符
A:static_cast
- 特点:静态转换,编译时执行。
- 应用场合:主要用于C++中内置的基本数据类型之间的转换,同一个继承体系中类型的转换,任意类型与空指针类型void* 之间的转换,但是没有运行时类型检查(RTTI)来保证转换的安全性。
const_cast
- 特点:去常转换,编译时执行。
- 应用场合: const_cast可以用于修改类型的const或volatile属性,去除指向常数对象的指针或引用的常量性。
reinterpret_cast:
- 特点:重解释类型转换,编译时执行。
- 应用场合: 可以用于任意类型的指针之间的转换,对转换的结果不做任何保证。
dynamic_cast:
- 特点:动态类型转换,运行时执行。
- 应用场合:只能用于存在虚函数的父子关系的强制类型转换,只能转指针或引用。对于指针,转换失败则返回nullptr,对于引用,转换失败会抛出异常
Q:请你说说你了解的RTTI
A:
定义:RTTI(Run Time Type Identification)即通过运行时类型识别,程序能够使用基类的指针或引用来检查着这些指针或引用所指的对象的实际派生类型。
RTTI机制产生原因:C++是一种静态类型语言,其数据类型是在编译期就确定的,不能在运行时更改。然而由于面向对象程序设计中多态性的要求,C++中的指针或引用本身的类型,可能与它实际代表(指向或引用)的类型并不一致。有时我们需要将一个多态指针转换为其实际指向对象的类型,就需要知道运行时的类型信息,这就产生了运行时类型识别的要求。
C++中有两个函数用于运行时类型识别,分别是dynamic_cast和typeid,具体如下:
- typeid函数返回一个对type_info类对象的引用,可以通过该类的成员函数获得指针和引用所指的实际类型;
- dynamic_cast操作符,将基类类型的指针或引用安全地转换为其派生类类型的指针或引用。
Q:explicit(显式)关键字
A:
- explicit 修饰构造函数时,可以防止隐式转换和复制初始化,必须显式初始化
- explicit 修饰转换函数时,可以防止隐式转换,但按语境转换 除外
struct B { explicit B(int) {} explicit operator bool() const { return true; } }; int main() { B b1(1); // OK:直接初始化 B b2 = 1; // 错误:被 explicit 修饰构造函数的对象不可以复制初始化 B b3{ 1 }; // OK:直接列表初始化 B b4 = { 1 }; // 错误:被 explicit 修饰构造函数的对象不可以复制列表初始化 B b5 = (B)1; // OK:允许 static_cast 的显式转换 doB(1); // 错误:被 explicit 修饰构造函数的对象不可以从 int 到 B 的隐式转换 if (b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换 bool b6(b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换 bool b7 = b1; // 错误:被 explicit 修饰转换函数 B::operator bool() 的对象不可以隐式转换 bool b8 = static_cast(b1); // OK:static_cast 进行直接初始化 return 0; }
Q::: 范围解析运算符
A:该运算符可分为如下三类:
- 全局作用域符(::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间
- 类作用域符(class::name):用于表示指定类型的作用域范围是具体某个类的
- 命名空间作用域符(namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
第三章 指针和引用
3.1 指针
3.1.1 指针定义
指针是一个变量,其值为另一个变量的内存地址。指针变量声明的一般形式为:
type *var-name;
int *ip; /* 一个整型的指针 */
所有指针的值的实际数据类型,不管是整型、浮点型、字符型,还是其他的数据类型,都是一样的,都是一个代表内存地址的长的十六进制数。不同数据类型的指针之间唯一的不同是,指针所指向的变量或常量的数据类型不同。
3.1.2 指针的使用
使用指针时会频繁进行以下几个操作:定义一个指针变量、把变量地址赋值给指针、访问指针变量中可用地址的值。这些是通过使用一元运算符 * 来返回位于操作数所指定地址的变量的值。
#include
using namespace std;
int main ()
{
int var = 20; // 实际变量的声明
int *ip; // 指针变量的声明
ip = &var; // 在指针变量中存储 var 的地址
cout << "Value of var variable: ";
cout << var << endl;
// 输出在指针变量中存储的地址
cout << "Address stored in ip variable: ";
cout << ip << endl;
// 访问指针中地址的值
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}
其结果为:
Value of var variable: 20
Address stored in ip variable: 0xbfc601ac
Value of *ip variable: 20
3.1.3 常用指针操作
//空指针
int *ptr = NULL;
cout << "ptr 的值是 " << ptr ; //结果是:ptr 的值是 0
//指针递增
int var[3] = {10, 100, 200};
ptr = var; //数组的变量名代表指向第一个元素的指针
ptr++;
//指向指针的指针
int var;
int *ptr;
int **pptr;
var = 3000;
// 获取 var 的地址
ptr = &var;
// 使用运算符 & 获取 ptr 的地址
pptr = &ptr;
3.2 引用
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。引用很容易与指针混淆,它们之间有三个主要的不同:
- 不存在空引用。引用必须连接到一块合法的内存。
- 一旦引用被初始化为一个对象,就不能被指向到另一个对象。指针可以在任何时候指向到另一个对象。
- 引用必须在创建时被初始化。指针可以在任何时间被初始化。
// 声明简单的变量
int i;
double d;
// 声明引用变量
int& r = i;
double& s = d;
3.3 相关面试题
Q:C/C++ 中指针和引用的区别?
A:
- 指针有自己的一块空间,而引用只是一个别名;
- 指针可以被初始化为NULL,而引用必须被初始化;
- 指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能被改变;
- 指针可以有多级指针(**p),而引用只有一级;
Q:指针函数和函数指针?
A:
- 指针函数本质上是一个函数,函数的返回值是一个指针;
- 函数指针本质上是一个指针,C++在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址,有了函数指针后,就可用该指针变量调用函数。
char * fun(char * p) {…} // 指针函数fun char * (*pf)(char * p); // 函数指针pf pf = fun; // 函数指针pf指向函数fun pf(p); // 通过函数指针pf调用函数fun
Q:在什么时候需要使用“常引用”?
A:如果既要利用引用提高程序的效率,又要保护传递给函数的数据不在函数中被改变,就应使用常引用。
Q:C++中的四个智能指针: shared_ptr、unique_ptr、weak_ptr、auto_ptr
A:智能指针出现的原因:智能指针的作用就是用来管理一个指针,将普通的指针封装成一个栈对象,当栈对象的生命周期结束之后,会自动调用析构函数释放掉申请的内存空间,从而防止内存泄露。(https://www.cnblogs.com/WindSun/p/11444429.html)
- shared_ptr实现共享式拥有概念。多个智能指针指向相同对象,该对象和其相关资源会在最后一个引用被销毁时被释放。
- unique_ptr实现独占式拥有概念,保证同一时间内只有一个智能指针可以指向该对象。
- weak_ptr 是一种共享但不拥有对象的智能指针, 它指向一个 shared_ptr 管理的对象。进行该对象的内存管理的是那个强引用的 shared_ptr,weak_ptr只是提供了对管理对象的一个访问手段,它的构造和析构不会引起引用计数的增加或减少。weak_ptr 设计的目的是为协助 shared_ptr工作的,用来解决shared_ptr相互引用时的死锁问题。注意的是我们不能通过weak_ptr直接访问对象的方法,以通过调用lock函数来获得shared_ptr,再通过shared_ptr去调用对象的方法。
- auto_ptr采用所有权模式,C++11中已经抛弃。
Q:shared_ptr的底层实现
A:
templateclass smart_ptrs { public: smart_ptrs(T*); //用普通指针初始化智能指针 smart_ptrs(smart_ptrs&); // 拷贝构造 T* operator->(); //自定义指针运算符 T& operator*(); //自定义解引用运算符 smart_ptrs& operator=(smart_ptrs&); //自定义赋值运算符 ~smart_ptrs(); //自定义析构函数 private: int *count; //引用计数 T *p; //智能指针底层保管的指针 }; //构造函数 template smart_ptrs ::smart_ptrs(T *p): count(new int(1)), p(p) {} //对普通指针进行拷贝,同时引用计数器加1,因为需要对参数进行修改,所以没有将参数声明为const template smart_ptrs ::smart_ptrs(smart_ptrs &sp): count(&(++*sp.count)), p(sp.p) {} //指针运算符 template T* smart_ptrs ::operator->() {return p;} //定义解引用运算符 template T& smart_ptrs ::operator*() {return *p;} //定义赋值运算符,左边的指针计数减1,右边指针计数加1,当左边指针计数为0时,释放内存: template smart_ptrs & smart_ptrs ::operator=(smart_ptrs& sp) { ++*sp.count; if (--*count == 0) { //自我赋值同样能保持正确 delete count; delete p; } this->p = sp.p; this->count = sp.count; return *this; } // 定义析构函数: template smart_ptrs ::~smart_ptrs() { if (--*count == 0) { delete count; delete p; } }
Q:野指针
A:野指针就是指向一个已销毁或者访问受限内存区域的指针。产生野指针通常是因为几种疏忽:
- 指针变量未被初始化;
- 指针释放后未置空;
- 指针操作超越变量作用域(例如变量被释放了,指针还是指向它)。
Q:什么时候会发生段错误?
A:段错误通常发生在访问非法内存地址的时候,具体来说分为以下几种情况:
- 使用了野指针
- 试图修改字符串常量的内容
- 数组越界导致栈溢出Q:什么是右值引用,跟左值又有什么区别?
A:左值:能对表达式取地址的具名对象/变量等。一般指表达式结束后依然存在的持久对象。
右值:不能对表达式取地址的字面量、函数返回值、匿名函数或匿名对象。一般指表达式结束就不再存在的临时对象。
右值引用和左值引用的区别在于:
- 通过&获得左值引用,左值引用只能绑定左值。
- 通过&&获得右值引用,右值引用只能绑定右值,基于右值引用可以实现移动语义和完美转发,右值引用的好处是减少右值作为参数传递时的复制开销,提高效率。
Q:什么是std::move()以及什么时候使用它?
A:std::move()是C ++标准库中用于转换为右值引用的函数。当需要在其他地方“传输”对象的内容时使用std :: move,对象可以在不进行复制的情况下获取临时对象的内容,避免不必要的深拷贝。
Q:C++类的内部可以定义引用数据成员吗?
A:可以,必须通过成员函数初始化列表初始化
class MyClass { public: MyClass(int &i): a(1), b(i){ // 构造函数初始化列表中是初始化工作 // 在这里做的是赋值而非初始化工作 } private: const int a; int &b; // 引用数据成员b,必须通过列表初始化! };
第四章 函数——C++的编程模块
4.1 函数的定义与声明
4.1.1 函数定义
return_type function_name( parameter list )
{
body of the function
}
// 示例:函数返回两个数中较大的那个数
int max(int num1, int num2)
{
// 局部变量声明
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
4.1.2 函数声明
return_type function_name( parameter list );
//示例
int max(int num1, int num2);
//在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
int max(int, int);
注:当你在一个源文件中定义函数且在另一个文件中调用函数时,函数声明是必需的。在这种情况下,您应该在调用函数的文件顶部声明函数。
4.1.3 函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。当调用函数时,有多种向函数传递参数的方式:
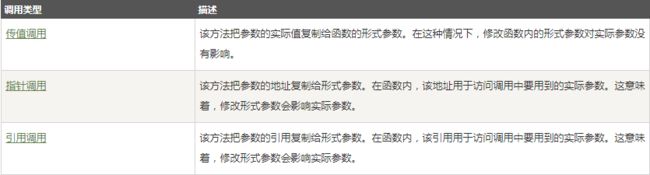 参数调用
参数调用
1、传值调用
默认情况下,C++ 使用传值调用来传递参数。
2、指针调用
把参数的地址复制给形参
#include
using namespace std;
// 函数定义
void swap(int *x, int *y)
{
int temp;
temp = *x; /* 保存地址 x 的值 */
*x = *y; /* 把 y 赋值给 x */
*y = temp; /* 把 x 赋值给 y */
return;
}
int main ()
{
// 局部变量声明
int a = 100;
int b = 200;
cout << "交换前,a 的值:" << a << endl;
cout << "交换前,b 的值:" << b << endl;
/* 调用函数来交换值
* &a 表示指向 a 的指针,即变量 a 的地址
* &b 表示指向 b 的指针,即变量 b 的地址
*/
swap(&a, &b);
cout << "交换后,a 的值:" << a << endl;
cout << "交换后,b 的值:" << b << endl;
return 0;
}
其中,&a、&b是指变量的地址,swap函数的形参*x、*y中的*是指从x、y的地址取值(即实参为地址,形参通过指针引用)。
3、引用调用
#include
using namespace std;
// 函数定义
void swap(int &x, int &y)
{
int temp;
temp = x; /* 保存地址 x 的值 */
x = y; /* 把 y 赋值给 x */
y = temp; /* 把 x 赋值给 y */
return;
}
int main ()
{
// 局部变量声明
int a = 100;
int b = 200;
cout << "交换前,a 的值:" << a << endl;
cout << "交换前,b 的值:" << b << endl;
/* 调用函数来交换值 */
swap(a, b);
cout << "交换后,a 的值:" << a << endl;
cout << "交换后,b 的值:" << b << endl;
return 0;
}
实参为变量,形参通过加&引用实参变量(区别于传值引用)
4、参数默认值
int sum(int a, int b=20)
{
int result;
result = a + b;
return (result);
}
//调用的时候可以不传入b
sum(a);
4.2 内联函数
当函数被声明为内联函数之后,编译器会将其内联展开,而不是按通常的函数调用机制进行调用。引入内联函数的目的是为了解决程序中函数调用的效率问题,程序在编译器编译的时候,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体进行替换,而对于其他的函数,都是在运行时候才被替代。这其实就是个空间代价换时间的节省。所以内联函数一般都是10行以下的小函数,如果想把一个函数定义为内联函数,则需要在函数名前面放置关键字 inline,在调用函数之前需要对函数进行定义。
 内联函数注意点
内联函数注意点
注:在类中定义的成员函数全部默认为内联函数,在类中声明,但在类外定义的为普通函数。
4.3 重载
4.3.1 重载函数
C++ 允许在同一个作用域内声明几个功能类似的同名函数,但是这些同名函数的形式参数(指参数的个数、类型或者顺序)必须不同。不能仅通过返回类型的不同来重载函数。
调用一个重载函数或重载运算符时,编译器通过把您所使用的参数类型与定义中的参数类型进行比较,决定选用最合适的定义。选择最合适的重载函数或重载运算符的过程,称为重载决策。
#include
using namespace std;
class printData
{
public:
void print(int i) {
cout << "整数为: " << i << endl;
}
void print(double f) {
cout << "浮点数为: " << f << endl;
}
void print(char c[]) {
cout << "字符串为: " << c << endl;
}
};
int main(void)
{
printData pd;
// 输出整数
pd.print(5);
// 输出浮点数
pd.print(500.263);
// 输出字符串
char c[] = "Hello C++";
pd.print(c);
return 0;
}
4.3.2 重载运算符
重载的运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。与其他函数一样,重载运算符有一个返回类型和一个参数列表,例如:
#include
using namespace std;
class Box
{
public:
double getVolume(void)
{
return length * breadth * height;
}
void setLength( double len )
{
length = len;
}
void setBreadth( double bre )
{
breadth = bre;
}
void setHeight( double hei )
{
height = hei;
}
// 重载 + 运算符,用于把两个 Box 对象相加
Box operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // 长度
double breadth; // 宽度
double height; // 高度
};
// 程序的主函数
int main( )
{
Box Box1; // 声明 Box1,类型为 Box
Box Box2; // 声明 Box2,类型为 Box
Box Box3; // 声明 Box3,类型为 Box
double volume = 0.0; // 把体积存储在该变量中
// Box1 详述
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// Box2 详述
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// Box1 的体积
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume < 4.3.3 可重载与不可重载运算符
 可重载运算符
可重载运算符
 不可重载运算符
不可重载运算符
4.4 模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
4.4.1 函数模板
模板函数定义的一般形式如下所示:
template
ret-type func-name(parameter list)
{
// 函数的主体
}
实例如下:
#include
#include
using namespace std;
//使用const&可节省传递时间,同时保证值不被改变
template
inline T const& Max (T const& a, T const& b)
{
return a < b ? b:a;
}
int main ()
{
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}
4.4.2 类模板
泛型类声明的一般形式如下所示:
template
class class-name {
//类的主体
}
实例如下:
#include
#include
#include
#include
#include
using namespace std;
template
class Stack {
private:
vector elems; // 元素
public:
void push(T const&); // 入栈
void pop(); // 出栈
T top() const; // 返回栈顶元素
bool empty() const{ // 如果为空则返回真。
return elems.empty();
}
};
template
void Stack::push (T const& elem)
{
// 追加传入元素的副本
elems.push_back(elem);
}
template
void Stack::pop ()
{
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// 删除最后一个元素
elems.pop_back();
}
template
T Stack::top () const
{
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// 返回最后一个元素的副本
return elems.back();
}
int main()
{
try {
Stack intStack; // int 类型的栈
Stack stringStack; // string 类型的栈
// 操作 int 类型的栈
intStack.push(7);
cout << intStack.top() < 4.5 相关面试题
Q:C语言是怎么进行函数调用的?
A:每一个函数调用都会分配函数栈,在栈内进行函数执行过程。调用前,先把返回地址压栈,然后把当前函数的esp指针压栈。
Q:函数参数压栈方式为什么是从右到左的?
A:因为C++支持可变函数参数。C程序栈底为高地址,栈顶为低地址,函数最左边确定的参数在栈上的位置必须是确定的,否则意味着已经确定的参数是不能定位和找到的,这样式无法保证函数正确执行的。
Q:C++如何处理返回值
A:生成一个临时变量存入内存单元,调用程序访问该内存单元,获得返回值。
Q:fork,wait,exec函数的作用
A:
- fork函数可以创建一个和当前映像一样的子进程,这个函数会返回两个值:从子进程返回0,从父进程返回子进程的PID;
- 调用了wait函数的父进程会发生阻塞,直到有子进程状态改变(执行成功返回0,错误返回-1);
- exec函数可以让子进程执行与父进程不同的程序,即让子进程执行另一个程序(exec执行成功则子进程从新的程序开始运行,无返回值,执行失败返回-1)。
Q:inline内联函数是什么?
A:当一个函数被声明为内联函数之后,在编译阶段,编译器会用内联函数的函数体取替换程序中出现的内联函数调用表达式,而其他的函数都是在运行时才被替换,这其实就是用空间换时间,提高了函数调用的效率。同时,内联函数具有几个特点:
- 内联函数中不可以出现循环、递归或开关操作;
- 内联函数的定义必须出现在内联函数的第一次调用前;
- 类的成员函数(除了虚函数)会自动隐式的当成内联函数。
Q:内联函数的优缺点
A:优点:
- 内联函数在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等操作,从而提高程序运行速度;
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换,而宏定义则不会;
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能;
- 内联函数在运行时可调试,而宏定义不可以。
缺点:
- 代码膨胀,消耗了更多的内存空间;
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接;
- 内联函数其实是不可控的,它只是对编译器的建议,是否对函数内联,决定权在于编译器。
Q:虚函数可以是内联函数吗?
A:虚函数可以是内联函数,但是当虚函数表现多态性的时候不能内联。
Q:函数重载、重写、隐藏和模板
A:
- 重载:在同一作用域中,两个函数名相同,但是参数列表不同(个数、类型、顺序),返回值类型没有要求;
- 重写:子类继承了父类,父类中的函数是虚函数,在子类中重新定义了这个虚函数,这种情况是重写;
- 隐藏:派生类中函数与基类中的函数同名,但是这个函数在基类中并没有被定义为虚函数,此时基类的函数会被隐藏;
- 模板:模板函数是一个通用函数,函数的类型和形参不直接指定而用虚拟类型来代表,只适用于参数个数相同而类型不同的函数。
Q:构造函数和析构函数能不能被重载?
A:构造函数可以被重载,析构函数不可以被重载。因为构造函数可以有多个且可以带参数, 而析构函数只能有一个,且不能带参数。
Q:拷贝构造函数和赋值运算符重载的区别?
A:
- 拷贝构造函数是函数,赋值运算符是运算符的重载;
- 拷贝构造函数会生成新的类对象,赋值运算符不会;
- 拷贝构造函数是用一个已存在的对象去构造一个不存在的对象;而赋值运算符重载函数是用一个存在的对象去给另一个已存在并初始化过的对象进行赋值。
Q:类模板是什么?
A:类模板是对一批仅数据成员类型不同的类的抽象,用于解决多个功能相同、数据类型不同的类需要重复定义的问题。在建立类时候使用template及任意类型标识符T,之后在建立类对象时,会指定实际的类型,这样才会是一个实际的对象。
Q:select、poll和epoll的区别、原理、性能、限制
A:select,poll,epoll都是I/O多路复用技术的具体实现。I/O多路复用就是在单个线程中,通过记录并跟踪每个I/O流的状态,来同时管理多个I/O流,一旦某个I/O流已经就绪,就能够通知程序进行相应的读写操作,以此提高服务器的吞吐能力。这种机制的优势不是在于对单个连接能处理得更快,而是在于能处理更多的连接,也就是多路网络连接复用一个I/O线程。
select
select是第一个实现I/O复用概念的函数。它用一个结构体fd_set让内核监听多个文件描述符。fd_set(文件描述符集合)本质上就是一个数组,当调用select函数后,就会去里面轮询查找看是否有描述符被置位,也就是有需要被处理的I/O事件。
select函数主要存在三个问题:
- 内置数组的形式使得select支持的最大文件描述符受限于FD_SIZE;
- 每次调用select前都要重新初始化描述符集,将fd从用户态拷贝到内核态,每次调用select后,都需要将fd从内核态拷贝到用户态;
- 每次调用select后都要去轮询排查所有文件描述符,这在文件描述符个数很多的时候,效率很低。
poll
poll可以理解为一个加强版的select。它通过一个可变长度的数组解决了select文件描述符受限的问题。数组中元素是结构体pollfd,这个结构体保存了描述符的信息,每增加一个文件描述符就向数组中加入一个结构体。同时,结构体只需要拷贝一次到内核态,解决了select重复初始化的问题。但是,它仍然存在轮询排查效率低的问题。
epoll
轮询排查所有文件描述符的效率不高,使服务器并发能力受限。因此,epoll采用只返回状态发生变化的文件描述符,便解决了轮寻的瓶颈。
第五章 结构体、类与对象
5.1 结构体
5.1.1 定义结构
struct 语句定义了一个包含多个成员的新的数据类型,struct 语句的格式如下:
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
在结构定义的末尾,最后一个分号之前,可以指定一个或多个结构变量,这是可选的。上面是声明一个结构体类型 Books,变量为 book。
5.1.2 访问结构成员
为了访问结构的成员,我们使用成员访问运算符(.)。
Books Book1; // 定义结构体类型 Books 的变量 Book1
// Book1 详述
strcpy( Book1.title, "C++ 教程");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "编程语言");
Book1.book_id = 12345;
5.1.3 结构作为函数参数
#include
#include
using namespace std;
void printBook( struct Books book );
// 声明一个结构体类型 Books
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main( )
{
Books Book1; // 定义结构体类型 Books 的变量 Book1
Books Book2; // 定义结构体类型 Books 的变量 Book2
// Book1 详述
strcpy( Book1.title, "C++ 教程");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "编程语言");
Book1.book_id = 12345;
// Book2 详述
strcpy( Book2.title, "CSS 教程");
strcpy( Book2.author, "Runoob");
strcpy( Book2.subject, "前端技术");
Book2.book_id = 12346;
// 输出 Book1 信息
printBook( Book1 );
// 输出 Book2 信息
printBook( Book2 );
return 0;
}
void printBook( struct Books book )
{
cout << "书标题 : " << book.title < 5.1.4 指向结构的指针
定义指向结构的指针,方式与定义指向其他类型变量的指针相似。为了使用指向该结构的指针访问结构的成员,必须使用 -> 运算符,如下所示:
struct Books *struct_pointer;
struct_pointer = &Book1;
struct_pointer->title;
5.2 类和对象
5.2.1 类的定义
class Box
{
public:
double length; // 盒子的长度
double breadth; // 盒子的宽度
double height; // 盒子的高度
double getVolume(void);// 返回体积
};
5.2.2 类的声明
Box box1;
Box box2 = Box(parameters);
Box box3(parameters);
Box* box4 = new Box(parameters);
5.2.3 访问类的成员
box1.length = 5.0;
cout << box1.length << endl;
5.2.4 类成员函数
成员函数可以定义在类定义内部,或者单独使用范围解析运算符 :: 来定义。
class Box
{
public:
double length; // 长度
double breadth; // 宽度
double height; // 高度
double getVolume(void)
{
return length * breadth * height;
}
};
//您也可以在类的外部使用范围解析运算符 :: 定义该函数
double Box::getVolume(void)
{
return length * breadth * height;
}
//调用成员函数同样是在对象上使用点运算符(.)
Box myBox; // 创建一个对象
myBox.getVolume(); // 调用该对象的成员函数
5.2.5 类访问修饰符
数据封装是面向对象编程的一个重要特点,它防止函数直接访问类的内部成员。类成员的访问限制是通过在类主体内部对各个区域标记 public、private、protected 来指定的。关键字 public、private、protected 称为访问修饰符。
class Base {
public:
// 公有成员
protected:
// 受保护成员
private:
// 私有成员
};
- 公有成员在程序中类的外部是可访问的。
- 私有成员变量或函数在类的外部是不可访问的,甚至是不可查看的。只有类和友元函数可以访问私有成员。如果没有使用任何访问修饰符,类的成员将被假定为私有成员
- 保护成员变量或函数与私有成员十分相似,但有一点不同,保护成员在派生类(即子类)中是可访问的。
5.2.6 类的特殊函数
1)构造函数
类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。
2)析构函数
类的析构函数是类的一种特殊成员函数,它会在每次删除所对象时执行。析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
class Line
{
public:
void setLength( double len );
double getLength( void );
Line(); // 这是构造函数
Line(double len); // 这是带参数的构造函数
~Line(); // 这是析构函数声明
private:
double length;
};
// 成员函数定义,包括构造函数
Line::Line(void)
{
cout << "Object is being created" << endl;
}
Line::Line( double len)
{
cout << "Object is being created, length = " << len << endl;
length = len;
}
Line::~Line(void)
{
cout << "Object is being deleted" << endl;
delete ptr;
}
3)拷贝构造函数
拷贝构造函数是一种特殊的构造函数,通常用于:通过使用另一个同类型的对象来初始化新创建的对象。
class Line
{
public:
int getLength( void );
Line( int len ); // 简单的构造函数
Line( const Line &obj); // 拷贝构造函数
~Line(); // 析构函数
private:
int *ptr;
};
Line::Line(const Line &obj)
{
cout << "调用拷贝构造函数并为指针 ptr 分配内存" << endl;
ptr = new int;
*ptr = *obj.ptr; // 拷贝值
}
4)友元函数
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
class Box
{
double width;
public:
friend void printWidth( Box box );
void setWidth( double wid );
};
// 请注意:printWidth() 不是任何类的成员函数
void printWidth( Box box )
{
/* 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员 */
cout << "Width of box : " << box.width <5.2.7 this指针
在 C++ 中,每一个对象都能通过 this 指针来访问自己的地址。this 指针是所有成员函数的隐含参数。因此,在成员函数内部,它可以用来指向调用对象。
class Box{
public:
Box(){;}
~Box(){;}
Box* get_address() //得到this的地址
{
return this;
}
double Volume()
{
return length * breadth * height;
}
int compare(Box box)
{
//指针通过->访问类成员,对象通过.访问类成员
return this->Volume() > box.Volume();
}
};
注:友元函数没有 this 指针,因为友元不是类的成员。只有成员函数才有 this 指针。
5.2.8 指向类的指针
int main(void)
{
Box Box1(3.3, 1.2, 1.5); // Declare box1
Box Box2(8.5, 6.0, 2.0); // Declare box2
Box *ptrBox; // Declare pointer to a class.
// 其中ptrBox为地址,*表示从其地址取值
// 保存第一个对象的地址
ptrBox = &Box1;
// 现在尝试使用成员访问运算符来访问成员
cout << "Volume of Box1: " << ptrBox->Volume() << endl;
// 保存第二个对象的地址
ptrBox = &Box2;
// 现在尝试使用成员访问运算符来访问成员
cout << "Volume of Box2: " << ptrBox->Volume() << endl;
return 0;
}
5.2.9 类的静态成员
我们可以使用 static 关键字来把类成员定义为静态的。静态成员在类的所有对象中是共享的,当我们声明类的成员为静态时,这意味着无论创建多少个类的对象,静态成员都只有一个副本。
注:如果不存在其他的初始化语句,在创建第一个对象时,所有的静态数据都会被初始化为零。我们不能把静态成员的初始化放置在类的定义中,但是可以在类的外部通过使用范围解析运算符 :: 来重新声明静态变量从而对它进行初始化
class Box
{
public:
static int objectCount;
// 构造函数定义
Box(double l=2.0, double b=2.0, double h=2.0)
{
cout <<"Constructor called." << endl;
length = l;
breadth = b;
height = h;
// 每次创建对象时增加 1
objectCount++;
}
double Volume()
{
return length * breadth * height;
}
private:
double length; // 长度
double breadth; // 宽度
double height; // 高度
};
// 初始化类 Box 的静态成员
int Box::objectCount = 1;
如果把函数成员声明为静态的,就可以把函数与类的任何特定对象独立开来。静态成员函数即使在类对象不存在的情况下也能被调用,静态函数只要使用类名加范围解析运算符 :: 就可以访问。

5.3 数据抽象与封装
5.3.1 定义
数据抽象是一种仅向用户暴露接口而把具体的实现细节隐藏起来的机制,是一种依赖于接口实现分离的设计技术。
数据封装是一种把数据和操作数据的函数捆绑在一起的机制。
#include
using namespace std;
class Adder{
public:
// 构造函数
Adder(int i = 0)
{
total = i;
}
// 对外的接口
void addNum(int number)
{
total += number;
}
// 对外的接口
int getTotal()
{
return total;
};
private:
// 对外隐藏的数据
int total;
};
int main( )
{
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() < 上面的类把数字相加,并返回总和。公有成员 addNum 和 getTotal 是对外的接口,用户需要知道它们以便使用类。私有成员 total 是用户不需要了解的,但又是类能正常工作所必需的。
数据抽象的好处
- 类的内部受到保护,不会因无意的用户级错误导致对象状态受损。
- 类实现可能随着时间的推移而发生变化,数据抽象可以更好的取应对不断变化的需求。
设计策略
- 通常情况下,我们都会设置类成员状态为私有(private),除非我们真的需要将其暴露,这样才能保证良好的封装性。抽象把代码分离为接口和实现。所以在设计组件时,必须保持接口独立于实现,这样,如果改变底层实现,接口也将保持不变。在这种情况下,不管任何程序使用接口,接口都不会受到影响,只需要将最新的实现重新编译即可。
5.3.2 接口
接口描述了类的行为和功能,而不需要完成类的特定实现。如果类中至少有一个函数被声明为纯虚函数,则这个类就是抽象类。
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <设计抽象类(通常称为 ABC)的目的,是为了给其他类提供一个可以继承的适当的基类。抽象类不能被用于实例化对象,它只能作为接口使用。因此,如果一个 ABC 的子类需要被实例化,则必须实现每个虚函数,如果没有在派生类中重写纯虚函数,就尝试实例化该类的对象,会导致编译错误。可用于实例化对象的类被称为具体类。
5.4 继承
继承代表了 is a 关系。例如,哺乳动物是动物,狗是哺乳动物,因此,狗是动物,等等。一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。类派生列表以一个或多个基类命名,形式如下:
class derived-class: access-specifier base-class
//例如
#include
using namespace std;
// 基类 Shape
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 基类 PaintCost
class PaintCost
{
public:
int getCost(int area)
{
return area * 70;
}
};
// 派生类
class Rectangle: public Shape, public PaintCost
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// 输出对象的面积
cout << "Total area: " << Rect.getArea() << endl;
// 输出总花费
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
派生类可以访问基类中所有的非私有成员,同时,一个派生类继承了所有的基类方法,但下列情况除外:
- 基类的构造函数、析构函数和拷贝构造函数。
- 基类的重载运算符。
- 基类的友元函数。
5.5 多态
5.5.1 虚函数
虚函数是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定。
C++ 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数,例如:
#include
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <area(); //Rectangle class area
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area(); //Triangle class area
return 0;
}
注意:若在基类中不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数,在函数参数后直接加 = 0 告诉编译器,函数没有主体,这种虚函数即是纯虚函数。
5.6 相关面试题
Q:C++中struct和class的区别
A:struct 更适合看成是一个数据结构的实现体,class 更适合看成是一个对象的实现体。它们最本质的一个区别就是:struct 访问权限默认是 public 的,class 默认是 private 的。
Q:析构函数是否需要是虚函数?
A:只有当一个类需要当作父类时,才将它的析构函数设置为虚函数。
- 将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们new一个子类,然后使用基类指针指向该子类对象,释放基类指针时可以释放掉子类的空间,防止内存泄漏;
- C++默认的析构函数不是虚函数,着是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。而对于不会被继承的类来说,其析构函数如果是虚函数,就会浪费内存。
Q:C++中析构函数的特点
A:
- 当对象结束其生命周期,如对象所在的函数已调用完毕时,系统会自动执行析构函数;
- 析构函数名与类名相同,只是在函数名前面加一个位取反符~,只能有一个析构函数,不能重载;
- 如果用户没有编写析构函数,编译系统会自动生成一个缺省的析构函数;
- 如果一个类中有指针,且在使用的过程中动态的申请了内存,那么最好显式构造析构函数,在销毁类之前释放掉申请的内存空间,避免内存泄漏;
- 类析构顺序:1)派生类本身的析构函数;2)对象成员析构函数;3)基类析构函数。
Q:静态函数和虚函数的区别
A:
- 静态函数在编译的时候就已经确定运行时机,虚函数在运行的时候动态绑定。
- 虚函数因为用了虚函数表机制,调用的时候会增加一次内存开销。
Q:必须使用成员初始化列表的场合
A:初始化列表的好处:少了一次调用默认构造函数的过程,提高了效率。
有些场合必须要用初始化列表:
- 常量成员,因为常量只能初始化不能赋值,所以必须放在初始化列表里面
- 引用类型,引用必须在定义的时候初始化,并且不能重新赋值,所以也要写在初始化列表里面
- 没有默认构造函数的类类型,因为使用初始化列表可以不必调用默认构造函数来初始化
Q:面向对象三大特征
A:
- 封装:把数据和操作绑定在一起封装成抽象的类,仅向用户暴露接口,而对其隐藏具体实现,以此避免外界干扰和不确定性访问;
- 继承:让某种类型对象获得另一个类型对象的属性和方法,提高了代码的可维护性;
- 多态:让同一事物体现出不同事物的状态,提高了代码的扩展性。
Q:C++ 多态分类及实现
A:
- 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载(静态多态)
- 子类型多态(Subtype Polymorphism,运行期):虚函数(动态多态)
- 参数多态(Parametric Polymorphism,编译期):类模板、函数模板
- 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
Q:是不是一个父类写了一个virtual 函数,如果子类重写它的函数不加virtual ,也能实现多态?
A:virtual修饰符会被隐形继承,因此可加可不加,子类覆盖它的函数不加virtual,也能实现多态。
Q:虚表指针、虚函数指针和虚函数表
A:
- 虚表指针:在含有虚函数的类的对象中,指向虚函数表的指针,在运行时确定。
- 虚函数指针:指向虚函数的地址的指针。
- 虚函数表:在程序只读数据段,存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚函数表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。
Q:简单描述虚继承与虚基类?
A:定义:在C++中,在定义公共基类A的派生类B、C...的时候,如果在继承方式前使用关键字virtual对继承方式限定,这样的继承方式就是虚拟继承,公共基类A成为虚基类。这样,在具有公共基类的、使用了虚拟继承方式的多个派生类B、C...的公共派生类D中,该基类A的成员就只有一份拷贝。
作用:一个类有多个基类,这样的继承关系称为多继承。在多继承的情况下,如果不同基类的成员名称相同,匹配度相同, 则会造成二义性。为了避免多继承产生的二义性,在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
Q:抽象类、接口类、聚合类
A:
- 抽象类:含有纯虚函数的类
- 接口类:仅含有纯虚函数的抽象类
- 聚合类:用户可以直接访问其成员,并且具有特殊的初始化语法形式。满足如下特点:1)所有成员都是 public;2)没有定义任何构造函数;3)没有类内初始化;4)没有基类,也没有 virtual 函数
Q:如何定义一个只能在堆上(栈上)生成对象的类?
A:
- 只能在堆上
- 方法: 将析构函数设置为私有
- 原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
- 只能在栈上
- 方法:将 new 和 delete 重载为私有
- 原因: 在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
Q:构造函数是否可以用private修饰,如果可以,会有什么效果?
A:如果一个类的构造函数只有一个且为private:
- 可以编译通过;
- 如果类的内部没有专门创建实例的代码,则是无法创建任何实例的;
- 如果类的内部有专门创建实例的代码,则只能创建一个或多个实例(根据类内部声明的成员对象个数来定);
- private 构造函数如果参数 为void(无参),则子类无法编译。
Q:子类的指针能否转换为父类的指针?父类指针能否访问子类成员?
A:首先要明确,当一个父类指针指向子类对象时是安全的,但只能访问从父类继承的成员;然而当一个子类指针指向父类对象时,因为可能调用父类不存在的方法,所以是不安全的,会爆语法错误。
- 当自己的类指针指向自己类的对象时,无论调用的是虚函数还是实函数,其调用的都是自己的;
- 当指向父类对象的父类指针被强制转换成子类指针时,也就是子类指针指向父类对象,此时,子类指针调用函数时,只有非重写函数是自己的,虚函数是父类的;
- 当指向子类对象的子类指针被强制转换成父类指针时,也就是父类指针指向子类对象,此时,父类指针调用的虚函数都是子类的,而非虚函数都是自己的。
Q:this 指针
A:this 指针是一个隐含于每一个非静态成员函数中的特殊指针,它指向调用该成员函数的对象的首地址。
- 当对一个对象调用成员函数时,编译程序先将对象的地址赋给 this 指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用 this 指针。
- this 指针被隐含地声明为: ClassName *const this,这意味着不能给 this 指针赋值。
- this 并是个右值,所以不能取 this 的地址。
Q:delete this
A:
- 类的成员函数中可以调用delete this,但是在释放后,对象后续调用的方法不能再用到this指针;
- delete this释放了类对象的内存空间,但是内存空间却并不是马上被回收到系统中,此时其中的值是不确定的;
- delete的本质是为将被释放的内存调用一个或多个析构函数,如果在类的析构函数中调用delete this,会陷入无限递归,造成栈溢出。
Q:一个空类class中有什么?
A:构造函数、拷贝构造函数、析构函数、赋值运算符重载、取地址操作符重载、被const修饰的取地址操作符重载
Q:C++计算一个类的sizeof
A:
- 一个空的类sizeof返回1,因为一个空类也要实例化,所谓类的实例化就是在内存中分配一块地址;
- 类内的普通成员函数不参与sizeof的统计,因为sizeof是针对实例的,而普通成员函数,是针对类体的;
- 一个类如果含有虚函数,则这个类中有一个指向虚函数表的指针,占4个字节;
- 静态成员不影响类的大小,被编译器放在程序的数据段中;
- 普通继承的类sizeof,会得到基类的大小加上派生类自身成员的大小;
- 当存在虚拟继承时,派生类中会有一个指向虚基类表的指针。所以其大小应为普通继承的大小,再加上虚基类表的指针大小。
Q:构造函数和析构函数能被继承吗?
A:不能。构造函数和析构函数是用来处理对象的创建和析构的,它们只知道对在它们的特殊层次的对象做什么。
Q:构造函数能不能是虚函数?
A:不能。虚函数对应一个虚函数表,可是这个虚函数表存储在对象的内存空间的。问题就在于,如果构造函数是虚的,就需要通过 虚函数表来调用,可是对象还没有实例化,也就是内存空间还没有,就不会有虚函数表。
Q:构造函数和析构函数能不能被重载 ?
A:构造函数可以被重载,析构函数不可以被重载。因为构造函数可以有多个且可以带参数, 而析构函数只能有一个,且不能带参数。
Q:构造函数调用顺序,析构函数呢?
A:基类的构造函数——成员类对象的构造函数——派生类的构造函数;析构函数相反。
Q:构造函数和析构函数调用时机?
A:
- 全局范围中的对象:构造函数在所有函数调用之前执行,在主函数执行完调用析构函数。
- 局部自动对象:建立对象时调用构造函数,函数结束时调用析构函数。
- 动态分配的对象:建立对象时调用构造函数,调用释放时调用析构函数。
- 静态局部变量对象:建立对象时调用构造函数,在主函数结束时调用析构函数。
Q:拷贝构造函数中深拷贝和浅拷贝区别?
A:
- 深拷贝会先申请一块和拷贝数据一样大的内存空间,然后将数据逐字节拷贝过去,拷贝后两个指针指向不同的两个内存空间;
- 浅拷贝仅是拷贝指针地址,拷贝后两个指针指向同一个内存空间。
当浅拷贝时,如果原来的对象调用析构函数释放掉指针所指向的数据,则会产生空悬指针,因为所指向的内存空间已经被释放了。
Q:拷贝构造函数在什么时候会被调用?
A:
- 当用类的一个对象去初始化该类的另一个对象(或引用)时系统自动调用拷贝构造函数实现拷贝赋值;
- 若函数的形参为类对象,调用函数时,实参赋值给形参,系统自动调用拷贝构造函数;
- 当函数的返回值是类对象时,系统自动调用拷贝构造函数;
- 需要产生一个临时类对象时。
Q:什么时候必须重写拷贝构造函数?
A:当构造函数涉及到动态内存分配时,要自己写拷贝构造函数,并且要深拷贝。
Q:什么是常对象?
A:常对象是指在任何场合都不能对其成员的值进行修改的对象。
Q:面向过程编程和面向对象编程的区别
A:面向过程:就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现。
面向对象:面向对象是一种对现实世界理解和抽象的方法,强调的是通过将需求要素转化为对象进行问题处理的一种思想。
Q:为什么内联函数,构造函数,静态成员函数不能为virtual函数?
A:
内联函数
内联函数是在编译时期展开,而虚函数的特性是运行时才动态联编,所以两者矛盾,不能定义内联函数为虚函数。构造函数
构造函数用来创建一个新的对象,而虚函数的运行是建立在对象的基础上,在构造函数执行时,对象尚未形成,所以不能将构造函数定义为虚函数。静态成员函数
静态成员函数属于一个类而非某一对象,没有this指针,它无法进行对象的判别。友元函数
C++不支持友元函数的继承,对于没有继承性的函数没有虚函数。
Q:如何定义和实现一个类的成员函数为回调函数?
A:所谓的回调函数,就是预先在系统的对函数进行注册,让系统知道这个函数的存在,以后,当某个事件发生时,再调用这个函数对事件进行响应。
定义一个类的成员函数时在该函数前加CALLBACK即将其定义为回调函数,函数的实现和普通成员函数没有区别。
第六章 动态内存
C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
6.1 new和delete运算符
在 C++ 中,可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。如果不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
#include
using namespace std;
int main ()
{
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存
*pvalue = 29494.99; // 在分配的地址存储值
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // 释放内存
return 0;
}
6.2 动态内存分配
6.2.1 数组的动态内存分配
假设我们要为一个字符数组(一个有 20 个字符的字符串)分配内存,我们可以使用上面实例中的语法来为数组动态地分配内存:
char* pvalue = NULL; // 初始化为 null 的指针
pvalue = new char[20]; // 为变量请求内存
要删除我们刚才创建的数组,语句如下:
delete [] pvalue; // 删除 pvalue 所指向的数组
二维数组示例:
#include
using namespace std;
int main()
{
int **p;
int i,j; //p[4][8]
//开始分配4行8列的二维数据
p = new int *[4];
for(i=0;i<4;i++){
p[i]=new int [8];
}
for(i=0; i<4; i++){
for(j=0; j<8; j++){
p[i][j] = j*i;
}
}
//打印数据
for(i=0; i<4; i++){
for(j=0; j<8; j++)
{
if(j==0) cout< 6.2.2 对象的动态内存分配
对象与简单的数据类型没有什么不同:
#include
using namespace std;
class Box
{
public:
Box() {
cout << "调用构造函数!" < 如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数。
6.3 相关面试题
Q:new/delete具体步骤
A:使用new操作符来分配对象内存时会经历三个步骤:
- 第一步:调用operator new 函数分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
- 第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
- 第三部:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
- 第一步:调用对象的析构函数。
- 第二步:编译器调用operator delete函数释放内存空间。
Q:new/delete与malloc/free的区别是什么?
A:
- malloc/free是C语言的标准库函数, new/delete是C++的运算符。它们都可用于申请动态内存和释放内存;
- malloc/free不会去自动调用构造和析构函数,对于基本数据类型的对象而言,光用malloc/free无法满足动态对象的要求;
- malloc/free需要指定分配内存的大小,而new/delete会自动计算所需内存大小;
- new返回的是指定对象的指针,而malloc返回的是void*,因此malloc的返回值一般都需要进行强制类型转换。
Q:C++内存管理
A:在C++中,虚拟内存分为代码段、数据段、BSS段、堆区、栈区以及文件映射区六部分。
- 代码段:包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。
- 数据段:存储程序中已初始化的全局变量和静态变量
- BSS段:存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。
- 堆区:调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。
- 映射区:存储动态链接库以及调用mmap函数进行的文件映射
- 栈区:使用栈空间存储函数的返回地址、参数、局部变量、返回值
Q:内存的分配方式
A:内存分配方式有三种:
- 静态存储区,是在程序编译时就已经分配好的,在整个运行期间都存在,如全局变量、常量。
- 栈上分配,函数内的局部变量就是从这分配的,但分配的内存容易有限。
- 堆上分配,也称动态分配,如我们用new,malloc分配内存,用delete,free来释放的内存。
Q:简单介绍内存池?
A:内存池是一种内存分配方式。通常我们习惯直接使用new、malloc申请内存,这样做的缺点在于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能。内存池则是在真正使用内存之前,预先申请分配一定数量、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存。这样做的一个显著优点是,使得内存分配效率得到提升。
Q:简单描述内存泄漏?
A:内存泄漏一般是指堆内存的泄漏,也就是程序在运行过程中动态申请的内存空间不再使用后没有及时释放,导致那块内存不能被再次使用。
Q:C++中的不安全是什么概念?
A:C++中的不安全包括两种:一是程序得不到正确的结果,二是发生不可预知的错误(占用了不该用的内存空间)。可能会发生如下问题:
- 最严重的:内存泄漏,程序崩溃;
- 一般严重的:发生一些逻辑错误,且不便于调试;
- 较轻的:丢失部分数据,就像强制转换一样。
Q:内存中的堆与栈有什么区别?
A:
- 申请方式:栈由系统自动分配和管理,堆由程序员手动分配和管理。
- 效率:栈由系统分配,计算机底层对栈提供了一系列支持:分配专门的寄存器存储栈的地址,压栈和入栈有专门的指令执行,因此,其速度快,不会有内存碎片;堆由程序员分配,堆是由C/C++函数库提供的,机制复杂,需要一些列分配内存、合并内存和释放内存的算法,因此效率较低,可能由于操作不当产生内存碎片。
- 扩展方向:栈从高地址向低地址进行扩展,堆由低地址向高地址进行扩展。
- 程序局部变量是使用的栈空间,new/malloc动态申请的内存是堆空间;同时,函数调用时会进行形参和返回值的压栈出栈,也是用的栈空间。
第七章 C++ STL(标准模板库)
STL(Standard Template Library),即标准模板库,是一个具有工业强度的,高效的C++程序库。STL中包括六大组件:容器、迭代器、算法、仿函数、迭代适配器、空间配置器。
7.1 容器
STL中的常用容器包括:序列式容器(vector、deque、list)、关联式容器(map、set)、容器适配器(queue、stack)。
7.1.1 序列式容器
1)vector
vector是一种动态数组,在内存中具有连续的存储空间,支持快速随机访问。由于具有连续的存储空间,所以在插入和删除操作方面,效率比较慢。其常用操作如下:
//需要包含头文件
#include
//1.定义和初始化
vector vec1; //默认初始化,vec1为空
vector vec2(vec1); //使用vec1初始化vec2
vector vec3(vec1.begin(),vec1.end());//使用vec1初始化vec2
vector vec4(10); //10个值为0的元素
vector vec5(10,4); //10个值为4的元素
//2.常用操作方法
//2.1 添加函数
vec1.push_back(100); //尾部添加元素
vec1.insert(vec1.end(),5,3); //从vec1.back位置插入5个值为3的元素
//2.2 删除函数
vec1.pop_back(); //删除末尾元素
vec1.erase(vec1.begin(),vec1.begin()+2); //删除vec1[0]-vec1[2]之间的元素,不包括vec1[2]其他元素前移
vec1.clear(); //清空元素,元素在内存中并未消失,通常使用swap()来清空
vector().swap(V); //利用swap函数和临时对象交换内存,交换以后,临时对象消失,释放内存。
//2.3 遍历函数
vec1[0]; //取得第一个元素
vec1.at(int pos); //返回pos位置元素的引用
vec1.front(); //返回首元素的引用
vec1.back(); //返回尾元素的引用
vector::iterator begin= vec1.begin(); //返回向量头指针,指向第一个元素
vector::iterator end= vec1.end(); //返回向量尾指针,指向向量最后一个元素的下一个位置
vector::iterator rbegin= vec1.rbegin(); //反向迭代器,指向最后一个元素
vector::iterator rend= vec1.rend(); //反向迭代器,指向第一个元素之前的位置
//2.4 判断函数
bool isEmpty = vec1.empty(); //判断是否为空
//2.5 大小函数
int size = vec1.size(); //元素个数
vec1.capacity(); //返回容器当前能够容纳的元素个数
vec1.max_size(); //返回容器最大的可能存储的元素个数
//2.6 改动函数
vec1.assign(int n,const T& x); //赋n个值为x的元素到vec1中,这会清除掉vec1中以前的内容。
vec1.assign(const_iterator first,const_iterator last); //当前向量中[first,last)中元素设置成迭代器所指向量的元素,这会清除掉vec1中以前的内容。
2)deque
所谓的deque是”double ended queue”的缩写,双向队列不论在尾部或头部插入元素,都十分迅速。而在中间插入元素则会比较费时,因为必须移动中间其他的元素。
#include // 头文件
//1.声明和初始化
deque deq; // 声明一个元素类型为type的双端队列que
deque deq(size); // 声明一个类型为type、含有size个默认值初始化元素的的双端队列que
deque deq(size, value); // 声明一个元素类型为type、含有size个value元素的双端队列que
deque deq(mydeque); // deq是mydeque的一个副本
deque deq(first, last); // 使用迭代器first、last范围内的元素初始化deq
//2.常用成员函数
deq[index]; //用来访问双向队列中单个的元素。
deq.at(index); //用来访问双向队列中单个的元素。
deq.front(); //返回第一个元素的引用。
deq.back(); //返回最后一个元素的引用。
deq.push_front(x); //把元素x插入到双向队列的头部。
deq.pop_front(); //弹出双向队列的第一个元素。
deq.push_back(x); //把元素x插入到双向队列的尾部。
deq.pop_back(); //弹出双向队列的最后一个元素。
3)list
list是STL实现的双向链表,与vector相比, 它允许快速的插入和删除,但是随机访问却比较慢。
#include
//1.定义和初始化
listlst1; //创建空list
list lst2(5); //创建含有5个元素的list
listlst3(3,2); //创建含有3个元素值为2的list
listlst4(lst2); //使用lst2初始化lst4
listlst5(lst2.begin(),lst2.end()); //同lst4
//2.常用操作函数
lst1.assign(lst2.begin(),lst2.end()); //给list赋值为lst2
lst1.back(); //返回最后一个元素
lst1.begin(); //返回指向第一个元素的迭代器
lst1.clear(); //删除所有元素
lst1.empty(); //如果list是空的则返回true
lst1.end(); //返回末尾的迭代器
lst1.erase(); //删除一个元素
lst1.front(); //返回第一个元素
lst1.insert(); //插入一个元素到list中
lst1.max_size(); //返回list能容纳的最大元素数量
lst1.merge(); //合并两个list
lst1.pop_back(); //删除最后一个元素
lst1.pop_front(); //删除第一个元素
lst1.push_back(); //在list的末尾添加一个元素
lst1.push_front(); //在list的头部添加一个元素
lst1.rbegin(); //返回指向第一个元素的逆向迭代器
lst1.remove(); //从list删除元素
lst1.remove_if(); //按指定条件删除元素
lst1.rend(); //指向list末尾的逆向迭代器
lst1.resize(); //改变list的大小
lst1.reverse(); //把list的元素倒转
lst1.size(); //返回list中的元素个数
lst1.sort(); //给list排序
lst1.splice(); //合并两个list
lst1.swap(); //交换两个list
lst1.unique(); //删除list中相邻重复的元素
7.1.2 关联式容器
1)map
map是STL的一个关联容器,它是一种键值对容器,里面的数据都是成对出现的,可在我们处理一对一数据的时候,在编程上提供快速通道。map内部自建一颗红黑树(一种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。
#include 2)set
set的含义是集合,它是一个有序的容器,里面的元素都是排序好的支持插入、删除、查找等操作,就像一个集合一样,所有的操作都是严格在logn时间内完成,效率非常高,使用方法类似list。
7.2 相关面试题
Q:六大组件介绍
A:容器:数据结构,用来存放数据
算法:常用算法
迭代器:容器和算法之间的胶合剂,“范型指针”
仿函数:一种重载了operator()的类,使得这个类的使用看上去像一个函数
配置器:为容器分配并管理内存
适配器:修改其他组件接口
Q:STL常用的容器有哪些以及各自的特点是什么?
A:
- vector:底层数据结构为数组 ,支持快速随机访问。
- list:底层数据结构为双向链表,支持快速增删。
- deque:底层数据结构为一个中央控制器和多个缓冲区,支持首尾(中间不能)快速增删,也支持随机访问。
- stack:底层一般用deque/list实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时。
- queue:底层一般用deque/list实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时。
- priority_queue:的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现。
- set:底层数据结构为红黑树,有序,不重复。
- multiset:底层数据结构为红黑树,有序,可重复。
- map:底层数据结构为红黑树,有序,不重复。
- multimap:底层数据结构为红黑树,有序,可重复。
- unordered_set:底层数据结构为hash表,无序,不重复。
- unordered_multiset:底层数据结构为hash表,无序,可重复 。
- unordered_map :底层数据结构为hash表,无序,不重复。
- unordered_multimap:底层数据结构为hash表,无序,可重复。
Q:说说 vector 和 list 的区别
A:
- vector底层实现是数组,所以在内存中是连续存放的,随机读取效率高,但插入、删除效率低;list底层实现是双向链表,所以在内存中是任意存放的,插入、删除效率高,但访问元素效率低。
- vector在中间节点进行插入、删除会导致内存拷贝,而list不会。
- vector一次性分配好内存,不够时才进行2倍扩容;list每次插入新节点都会进行内存申请。
Q:vector扩容原理
A:以原内存空间大小的两倍配置一份新的内存空间,并将原空间数据拷贝过来进行初始化。
Q:map 和 set 有什么区别
A:
- map中的元素是键值对;Set仅是关键字的简单集合;
- set的迭代器是const的,不允许修改元素的值;map允许修改value,但不允许修改key;
- map支持用关键字作下标操作,set不支持下标操作。
Q:map和unordered_map的区别
A:
- map: map内部实现了一个红黑树,红黑树的每一个节点都代表着map的一个元素,因此所有元素都是有序的,对其进行查找、插入、删除得效率都是O(log n);但是,因为每个结点都需要额外保存数据,所以空间占用率比较高。
- unordered_map: unordered_map内部实现了一个哈希表,因此内部元素是无序的,对其进行查找、插入、删除得效率都是O(1);但是建立哈希表比较费时。
Q:STL 中迭代器的作用,有指针为何还要迭代器
A:
- Iterator(迭代器)模式又称Cursor(游标)模式,用于提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示。
- 迭代器不是指针,是类模板,表现的像指针。他只是模拟了指针的一些功能,通过重载了指针的一些操作符,->、*、++、--等,相当于一种智能指针。
- 迭代器产生原因:Iterator采用的是面向对象的思想,把不同集合类的访问逻辑抽象出来,使得不用暴露集合内部的结构而达到循环遍历集合的效果。
第八章 异常处理
C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。它后面通常跟着一个或多个 catch 块。
8.1 抛出异常
可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
8.2 捕获异常
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}
上面的代码会捕获一个类型为 ExceptionName 的异常。如果想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...,例如:
try
{
// 保护代码
}catch(...)
{
// 能处理任何异常的代码
}
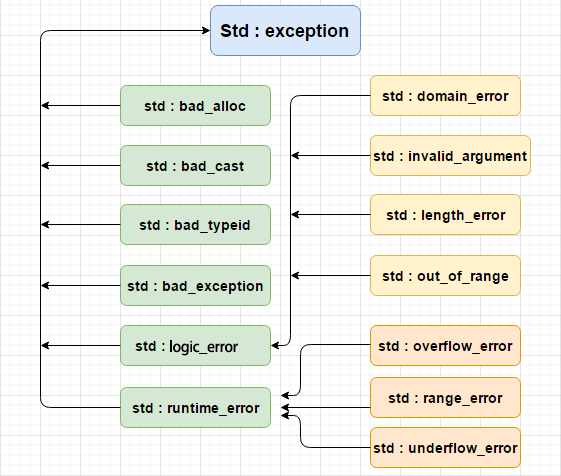
8.3 C++标准的异常
C++ 提供了一系列标准的异常,定义在
8.4 定义新的异常
可以通过继承和重载 exception 类来定义新的异常。
#include
#include
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的错误
}
}
第九章 多线程
多线程是多任务处理的一种特殊形式,一般情况下,有基于进程和基于线程的两种类型的多任务处理方式。
- 基于进程的多任务处理是程序的并发执行。
- 基于线程的多任务处理是同一程序的片段的并发执行。
9.1 基本概念
9.1.1 进程与线程
进程是资源分配和调度的一个独立单位;而线程是进程的一个实体,是CPU调度和分配的基本单位。
同一个进程中的多个线程的内存资源是共享的,各线程都可以改变进程中的变量。因此在执行多线程运算的时候要注意执行顺序。
9.1.2 并行与并发
并行(parallellism)指的是多个任务在同一时刻同时在执行。
并发(concurrency)是指在一个时间段内,多个任务交替进行。虽然看起来像在同时执行,但其实是交替的。
9.2 C++线程管理
- C++11的标准库中提供了多线程库,使用时需要#include
头文件,该头文件主要包含了对线程的管理类std::thread以及其他管理线程相关的类。 - 每个应用程序至少有一个进程,而每个进程至少有一个主线程,除了主线程外,在一个进程中还可以创建多个子线程。每个线程都需要一个入口函数,入口函数返回退出,该线程也会退出,主线程就是以main函数作为入口函数的线程。
9.2.1 启动线程
std::thread的构造函数需要的是可调用(callable)类型,除了函数外,还可以调用例如:lambda表达式、重载了()运算符的类的实例。
#include
#include
using namespace std;
void output(int i)
{
cout << i << endl;
}
int main()
{
for (uint8_t i = 0; i < 4; i++)
{
//创建一个线程t,第一个参数为调用的函数,第二个参数为传递的参数
thread t(output, i);
//表示允许该线程在后台运行
t.detach();
}
return 0;
}
在多线程并行的条件下,其输出结果不一定是顺序呢的输出1234,可能如下:
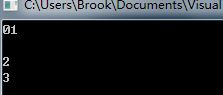 多线程并行
多线程并行
注意:
- 把函数对象传入std::thread时,应传入函数名称(命名变量,如:output)而不加括号(临时变量,如:output())。
- 当启动一个线程后,一定要在该线程thread销毁前,调用t.join()或者t.detach(),确定以何种方式等待线程执行结束:
- detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。
- join方式,等待关联的线程完成,才会继续执行join()后的代码。
- 在以detach的方式执行线程时,要将线程访问的局部数据复制到线程的空间(使用按值传递),一定要确保线程没有使用局部变量的引用或者指针,除非你能肯定该线程会在局部作用域结束前执行结束。
9.2.2 向线程传递参数
向线程调用的函数只需要在构造thread的实例时,依次传入即可。
thread t(output, arg1, arg2, arg3, ...);9.2.3 调用类成员函数
class foo
{
public:
void bar1(int n)
{
cout<<"n = "<thread t1(f1);
thread t3(move(t1));
将线程从t1转移给t3,这时候t1就不再拥有线程的所有权,调用t1.join或t1.detach会出现异常,要使用t3来管理线程。这也就意味着thread可以作为函数的返回类型,或者作为参数传递给函数,能够更为方便的管理线程。
9.2.5 线程标识的获取
线程的标识类型为std::thread::id,有两种方式获得到线程的id:
- 通过thread的实例调用get_id()直接获取;
- 在当前线程上调用this_thread::get_id()获取。
9.2.6 线程暂停
如果让线程从外部暂停会引发很多并发问题,这也是为什么std::thread没有直接提供pause函数的原因。如果线程在运行过程中,确实需要停顿,就可以用this_thread::sleep_for。
void threadCaller()
{
this_thread::sleep_for(chrono::seconds(3)); //此处线程停顿3秒。
cout<<"thread pause for 3 seconds"<9.2.7 异常情况下等待线程完成
为了避免主线程出现异常时将子线程终结,就要保证子线程在函数退出前完成,即在函数退出前调用join()。
方法一:异常捕获
void func() {
thread t([]{
cout << "hello C++ 11" << endl;
});
try
{
do_something_else();
}
catch (...)
{
t.join();
throw;
}
t.join();
}
方法二:资源获取即初始化(RAII)
class thread_guard
{
private:
thread &t;
public:
/*加入explicit防止隐式转换,explicit仅可加在带一个参数的构造方法上,如:Demo test; test = 12.2;
这样的调用就相当于把12.2隐式转换为Demo类型,加入explicit就禁止了这种转换。*/
explicit thread_guard(thread& _t) {
t = _t;
}
~thread_guard()
{
if (t.joinable())
t.join();
}
thread_guard(const thread_guard&) = delete; //删除默认拷贝构造函数
thread_guard& operator=(const thread_guard&) = delete; //删除默认赋值运算符
};
void func(){
thread t([]{
cout << "Hello thread" <无论是何种情况,当函数退出时,对象guard调用其析构函数销毁,从而能够保证join一定会被调用。
9.3 线程的同步与互斥
线程之间通信的两个基本问题是互斥和同步:
- 线程同步是指线程之间所具有的一种制约关系,一个线程的执行依赖另一个线程的消息,当它没有得到另一个线程的消息时应等待,直到消息到达时才被唤醒。
- 线程互斥是指对于共享的操作系统资源,在各线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。
线程互斥是一种特殊的线程同步。实际上,同步和互斥对应着线程间通信发生的两种情况:
- 当一个线程需要将某个任务已经完成的情况通知另外一个或多个线程时;
- 当有多个线程访问共享资源而不使资源被破坏时。
在WIN32中,同步机制主要有以下几种:
- 临界区(Critical Section):通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
- 事件(Event):用来通知线程有一些事件已发生,从而启动后继任务的开始。
- 信号量(Semaphore):为控制一个具备有限数量用户资源而设计。
- 互斥量(Mutex):为协调一起对一个共享资源的单独访问而设计的。
9.3.1 临界区
临界区(Critical Section)是一段独占对某些共享资源访问的代码,在任意时刻只允许一个线程对共享资源进行访问。如果有多个线程试图同时访问临界区,那么在有一个线程进入后其他所有试图访问此临界区的线程将被挂起,并一直持续到进入临界区的线程离开。临界区在被释放后,其他线程可以继续抢占,并以此达到用原子方式操作共享资源的目的。
临界区在使用时以CRITICAL_SECTION结构对象保护共享资源,并分别用EnterCriticalSection()和LeaveCriticalSection()函数去标识和释放一个临界区。所用到的CRITICAL_SECTION结构对象必须经过InitializeCriticalSection()的初始化后才能使用,而且必须确保所有线程中的任何试图访问此共享资源的代码都处在此临界区的保护之下。否则临界区将不会起到应有的作用,共享资源依然有被破坏的可能。
#include "stdafx.h"
#include
#include
using namespace std;
int number = 1; //定义全局变量
CRITICAL_SECTION Critical; //定义临界区句柄
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
EnterCriticalSection(&Critical);
cout << "thread 1 :"< 9.3.2 事件
事件对象能够通过通知操作的方式来保持线程的同步,并且能够实现不同进程中的线程同步操作。事件可以处于激发状态(signaled or true)或未激发状态(unsignal or false)。根据状态变迁方式的不同,事件可分为两类:
- 手动设置:这种对象只可能用程序手动设置,在需要该事件或者事件发生时,采用SetEvent及ResetEvent来进行设置。
- 自动恢复:一旦事件发生并被处理后,自动恢复到没有事件状态,不需要再次设置。
使用”事件”机制应注意以下事项:
- 如果跨进程访问事件,必须对事件命名,在对事件命名的时候,要注意不要与系统命名空间中的其它全局命名对象冲突;
- 事件是否要自动恢复;
- 事件的初始状态设置。
#include "stdafx.h"
#include
#include
using namespace std;
int number = 1; //定义全局变量
HANDLE hEvent; //定义事件句柄
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hEvent, INFINITE); //等待对象为有信号状态
cout << "thread 1 :"< 由于event对象属于内核对象,故进程B可以调用OpenEvent函数通过对象的名字获得进程A中event对象的句柄,然后将这个句柄用于ResetEvent、SetEvent和WaitForMultipleObjects等函数中。此法可以实现一个进程的线程控制另一进程中线程的运行,例如:
HANDLE hEvent=OpenEvent(EVENT_ALL_ACCESS,true,"MyEvent");
ResetEvent(hEvent);9.3.3 信号量
信号量对象对线程的同步方式和前面几种方法不同,信号允许多个线程同时使用共享资源,但是需要限制在同一时刻访问此资源的最大线程数目。
用CreateSemaphore()创建信号量时即要同时指出允许的最大资源计数和当前可用资源计数。一般是将当前可用资源计数配置为最大资源计数,每增加一个线程对共享资源的访问,当前可用资源计数就会减1,只要当前可用资源计数是大于0的,就能够发出信号量信号。但是当前可用计数减小到0时则说明当前占用资源的线程数已达到了所允许的最大数目,不能在允许其他线程的进入,此时的信号量信号将无法发出。线程在处理完共享资源后,应在离开的同时通过ReleaseSemaphore()函数将当前可用资源计数加1。在任何时候当前可用资源计数决不可能大于最大资源计数。
信号量包含的几个操作原语:
- CreateSemaphore() 创建一个信号量
- OpenSemaphore() 打开一个信号量
- ReleaseSemaphore() 释放信号量
- WaitForSingleObject() 等待信号量
#include "stdafx.h"
#include
#include
using namespace std;
int number = 1; //定义全局变量
HANDLE hSemaphore; //定义信号量句柄
unsigned long __stdcall ThreadProc1(void* lp)
{
long count;
while (number < 100)
{
WaitForSingleObject(hSemaphore, INFINITE); //等待信号量为有信号状态
cout << "thread 1 :"< 9.3.4 互斥量
采用互斥对象机制。 只有拥有互斥对象的线程才有访问公共资源的权限,因为互斥对象只有一个,所以能保证公共资源不会同时被多个线程访问。互斥不仅能实现同一应用程序的公共资源安全共享,还能实现不同应用程序的公共资源安全共享。
互斥量包含的几个操作原语:
- CreateMutex() 创建一个互斥量
- OpenMutex() 打开一个互斥量
- ReleaseMutex() 释放互斥量
- WaitForMultipleObjects() 等待互斥量对象
#include "stdafx.h"
#include
#include
using namespace std;
int number = 1; //定义全局变量
HANDLE hMutex; //定义互斥对象句柄
unsigned long __stdcall ThreadProc1(void* lp)
{
while (number < 100)
{
WaitForSingleObject(hMutex, INFINITE);
cout << "thread 1 :"< 9.4 C++中的几种锁
在9.3.4中我们讲到了互斥量,其中CreateMutex等是Win32 api函数,而本节要介绍的std :: mutex来自C++标准库。
在C++11中线程之间的锁有:互斥锁、条件锁、自旋锁、读写锁、递归锁。
9.4.1 互斥锁
互斥锁是一种简单的加锁的方法来控制对共享资源的访问。
通过std::mutex可以方便的对临界区域加锁,std::mutex类定义于mutex头文件,是用于保护共享数据避免从多个线程同时访问的同步原语,它提供了lock、try_lock、unlock等几个接口。使用方法如下:
std::mutex mtx;
mtx.lock()
do_something...; //共享的数据
mtx.unlock();mutex的lock和unlock必须成对调用,lock之后忘记调用unlock将是非常严重的错误,再次lock时会造成死锁。
此时可以使用类模板std::lock_guard,通过RAII机制在其作用域内占有mutex,当程序流程离开创建lock_guard对象的作用域时,lock_guard对象被自动销毁并释放mutex。lock_guard构造时还可以传入一个参数adopt_lock或者defer_lock。adopt_lock表示是一个已经锁上了锁,defer_lock表示之后会上锁的锁。
std::mutex mtx;
std::lock_guard guard(mtx);
do_something...; //共享的数据
lock_guard类最大的缺点也是简单,没有给程序员提供足够的灵活度,因此C++11定义了另一个unique_guard类。这个类和lock_guard类似,也很方便线程对互斥量上锁,但它提供了更好的上锁和解锁控制,允许延迟锁定、锁定的有时限尝试、递归锁定、所有权转移和与条件变量一同使用。
#include // std::cout
#include // std::thread
#include // std::mutex, std::unique_lock
#include
std::mutex mtx; // mutex for critical section
std::once_flag flag;
void print_block (int n, char c) {
//unique_lock有多组构造函数, 这里std::defer_lock不设置锁状态
std::unique_lock my_lock (mtx, std::defer_lock);
//尝试加锁, 如果加锁成功则执行
//(适合定时执行一个job的场景, 一个线程执行就可以, 可以用更新时间戳辅助)
if(my_lock.try_lock()){
for (int i=0; i ver;
int num = 0;
for (auto i = 0; i < 10; ++i){
ver.emplace_back(print_block,50,'*');
ver.emplace_back(run_one, std::ref(num));
}
for (auto &t : ver){
t.join();
}
std::cout << num << std::endl;
return 0;
} unique_lock比lock_guard使用更加灵活,功能更加强大,但使用unique_lock需要付出更多的时间、性能成本。
9.4.2 条件锁
条件锁就是所谓的条件变量,当某一线程满足某个条件时,可以使用条件变量令该程序处于阻塞状态;一旦该条件状态发生变化,就以“信号量”的方式唤醒一个因为该条件而被阻塞的线程。
最为常见就是在线程池中,起初没有任务时任务队列为空,此时线程池中的线程因为“任务队列为空”这个条件处于阻塞状态。一旦有任务进来,就会以信号量的方式唤醒一个线程来处理这个任务。
- 头文件:
- 类型:std::condition_variable(只与std::mutex一起工作)、std::condition_variable_any(可与符合类似互斥元的最低标准的任何东西一起工作)。
std::deque q;
std::mutex mu;
std::condition_variable cond;
void function_1() //生产者
{
int count = 10;
while (count > 0)
{
std::unique_lock locker(mu);
q.push_front(count);
locker.unlock();
cond.notify_one(); // Notify one waiting thread, if there is one.
std::this_thread::sleep_for(std::chrono::seconds(1));
count--;
}
}
void function_2() //消费者
{
int data = 0;
while (data != 1)
{
std::unique_lock locker(mu);
while (q.empty())
cond.wait(locker); // Unlock mu and wait to be notified
data = q.back();
q.pop_back();
locker.unlock();
std::cout << "t2 got a value from t1: " << data << std::endl;
}
}
int main()
{
std::thread t1(function_1);
std::thread t2(function_2);
t1.join();
t2.join();
return 0;
} 上面是一个生产者-消费者模型,软件开启后,消费者线程进入循环,在循环里获取锁,如果消费品队列为空则wait,wait会自动释放锁;此时消费者已经没有锁了,在生产者线程里,获取锁,然后往消费品队列生产产品,释放锁,然后notify告知消费者退出wait,消费者重新获取锁,然后从队列里取消费品。
9.4.3 自旋锁
当发生阻塞时,互斥锁会让CPU去处理其他的任务,而自旋锁则会让CPU一直不断循环请求获取这个锁。由此可见“自旋锁”是比较耗费CPU的。在C++中我们可以通过原子操作实现自旋锁:
//使用std::atomic_flag的自旋锁互斥实现
class spinlock_mutex{
private:
std::atomic_flag flag;
public:
spinlock_mutex():flag(ATOMIC_FLAG_INIT) {}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
}9.4.4 读写锁
说到读写锁我们可以借助于“读者-写者”问题进行理解。
计算机中某些数据被多个进程共享,对数据库的操作有两种:一种是读操作,就是从数据库中读取数据不会修改数据库中内容;另一种就是写操作,写操作会修改数据库中存放的数据。因此可以得到我们允许在数据库上同时执行多个“读”操作,但是某一时刻只能在数据库上有一个“写”操作来更新数据。这就是一个简单的读者-写者模型。
头文件:boost/thread/shared_mutex.cpp
类型:boost::shared_lock、boost::shared_mutex
shared_mutex比一般的mutex多了函数lock_shared() / unlock_shared(),允许多个(读者)线程同时加锁和解锁;而shared_lock则相当于共享版的lock_guard。对于shared_mutex使用lock_guard或unique_lock就可以达到写者线程独占锁的目的。
读写锁的特点:
- 如果一个线程用读锁锁定了临界区,那么其他线程也可以用读锁来进入临界区,这样可以有多个线程并行操作。这个时候如果再用写锁加锁就会发生阻塞。写锁请求阻塞后,后面继续有读锁来请求时,这些后来的读锁都将会被阻塞。这样避免读锁长期占有资源,防止写锁饥饿。
- 如果一个线程用写锁锁住了临界区,那么其他线程无论是读锁还是写锁都会发生阻塞。
9.4.5 递归锁
递归锁又称可重入锁,在同一个线程在不解锁的情况下,可以多次获取锁定同一个递归锁,而且不会产生死锁。递归锁用起来固然简单,但往往会隐藏某些代码问题。比如调用函数和被调用函数以为自己拿到了锁,都在修改同一个对象,这时就很容易出现问题。
9.5 C++中的原子操作
9.5.1 atomic模版函数
为了避免多个线程同时修改全局变量,C++11除了提供互斥量mutex这种方法以外,还提供了atomic模版函数。使用atomic可以避免使用锁,而且更加底层,比mutex效率更高。
#include
#include
#include
#include
using namespace std;
void func(int& counter)
{
for (int i = 0; i < 100000; ++i)
{
++counter;
}
}
int main()
{
//atomic counter(0);
atomic_int counter(0); //新建一个整型原子counter,将counter初始化为0
//int counter = 0;
vector threads;
for (int i = 0; i < 10; ++i)
{
threads.push_back(thread(func, ref(counter)));
}
for (auto& current_thread : threads)
{
current_thread.join();
}
cout << "Result = " << counter << '\n';
return 0;
} 为了避免多个线程同时修改了counter这个数导致出现错误,只需要把counter的原来的int型,改为atomic_int型就可以了,非常方便,也不需要用到锁。
9.5.2 std::atomic_flag
std::atomic_flag是一个原子型的布尔变量,只有两个操作:
1)test_and_set,如果atomic_flag 对象已经被设置了,就返回True,如果未被设置,就设置之然后返回False
2)clear,把atomic_flag对象清掉
注意这个所谓atomic_flag对象其实就是当前的线程。如果当前的线程被设置成原子型,那么等价于上锁的操作,对变量拥有唯一的修改权。调用clear就是类似于解锁。
下面先看一个简单的例子,main() 函数中创建了 10 个线程进行计数,率先完成计数任务的线程输出自己的 ID,后续完成计数任务的线程不会输出自身 ID:
#include // std::cout
#include // std::atomic, std::atomic_flag, ATOMIC_FLAG_INIT
#include // std::thread, std::this_thread::yield
#include // std::vector
std::atomic ready(false); // can be checked without being set
std::atomic_flag winner = ATOMIC_FLAG_INIT; // always set when checked
void count1m(int id)
{
while (!ready) {
std::this_thread::yield();
} // 等待主线程中设置 ready 为 true.
for (int i = 0; i < 1000000; ++i) {
} // 计数.
// 如果某个线程率先执行完上面的计数过程,则输出自己的 ID.
// 此后其他线程执行 test_and_set 是 if 语句判断为 false,
// 因此不会输出自身 ID.
if (!winner.test_and_set()) {
std::cout << "thread #" << id << " won!\n";
}
};
int main()
{
std::vector threads;
std::cout << "spawning 10 threads that count to 1 million...\n";
for (int i = 1; i <= 10; ++i)
threads.push_back(std::thread(count1m, i));
ready = true;
for (auto & th:threads)
th.join();
return 0;
} 再来一个例子:
#include
#include
#include
#include
#include
std::atomic_flag lock = ATOMIC_FLAG_INIT; //初始化原子flag
std::stringstream stream;
void append_number(int x)
{
while(lock.test_and_set()); //如果原子flag未设置,那么返回False,就继续后面的代码。否则一直返回True,就一直停留在这个循环。
stream<<"thread#" < threads;
for(int i=0;i<10;i++)
threads.push_back(std::thread(append_number, i));
for(auto& th:threads)
th.join();
std::cout< 9.6 相关面试题
Q:C++怎么保证线程安全
A:
Q:悲观锁和乐观锁
A:悲观锁:悲观锁是就是悲观思想,即认为读少写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会 block 直到拿到锁。
乐观锁:乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复【读 - 比较 - 写】的操作。
Q:什么是死锁
A:所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
Q:死锁形成的必要条件
A:
产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生:
- 互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
- 不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
- 请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
- 循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合 {Pl, P2, …, pn},其中 Pi 等 待的资源被 P (i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0 占有
Q:什么是活锁
A:活锁和死锁在表现上是一样的两个线程都没有任何进展,但是区别在于:死锁,两个线程都处于阻塞状态,而活锁并不会阻塞,而是一直尝试去获取需要的锁,不断的 try,这种情况下线程并没有阻塞所以是活的状态,我们查看线程的状态也会发现线程是正常的,但重要的是整个程序却不能继续执行了,一直在做无用功。
Q:公平锁与非公平锁
A:公平锁:是指多个线程在等待同一个锁时,必须按照申请锁的先后顺序来一次获得锁。
非公平锁:理解了公平锁,非公平锁就很好理解了,它无非就是不用排队,当餐厅里的人出来后将钥匙往地上一扔,谁抢到算谁的。