基于Spark MLlib平台和基于模型的协同过滤算法的电影推荐系统(三) 作业里的拓展
20161205spark第四次作业
使用Spark ALS explicit训练,得到模型,并进行评价;
要求:1. 代码(只需要保留评价代码,建模代码,数据分割代码即可);
2. 相关图表(建模截图(包含参数)、评价截图、不同k值precesion、recall表格及图);
3. 测试数据集保留不超过10个用户即可;
4. 不同模型对比(1,2,3再做一遍,对比,可选)
前提:
1. 要有原始original数据 (百度云链接: http://pan.baidu.com/s/1hrAQYs0 密码: yiux)
2. explicit显式
original数据格式: 后面会用到的movies数据的格式:


1.数据分割代码
//做了toList操作的original,按时间戳从大到小排序
val original = sc.textFile("/ratings.dat").map{x => val f = x.split("::");(f(3).toInt,(f(0).toInt,f(1).toInt,f(2).toDouble))}.sortByKey(false).collect.toList
//没有做toList操作的original2,按时间戳从小到大排序
val original2 = sc.textFile("/ratings.dat").map{x => val f = x.split("::");(f(3).toInt,(f(0),f(1),f(2)))}.sortByKey(false)
//取出n个不同用户的记录放入空列表,返回最后一条记录的时间戳
def spiltdata(list:List[(Int,(Int,Int,Double))],n:Int):Int = {
var tmp:List[(Int,(Int,Int,Double))] = List();
for(l <- list){
tmp = tmp :+ l;
if(tmp.map(x => x._2._1).distinct.size >= n){
return tmp.last._1
}
};
0
}
//求出时间戳分割点,n取10(10个用户)
val splitTimeStamp = data(original,10).collect//小于这个时间戳的记录归为训练集
val train = original2.filter(x => x._1 < splitTimeStamp).map(x => Rating(x._2._1.toInt,x._2._2.toInt,x._2._3.toDouble))//大于这个时间戳的记录归为测试集,测试集中只有前n个用户的m条记录
val test = original2.filter(x => x._1 >= splitTimeStamp).map(x => (x._2._1.toInt,x._2._2.toInt,x._2._3.toDouble))2.建模代码:
//使用昨天作业中的最优模型的参数建模
val model =ALS.train(train,10,10,0.1)3.评价代码:
•precesion正确率 = 正确识别的个体总数 / 识别出的个体总数
(如果识别出的个体总数为null/0,那就是我们的模型识别不了,那我们就把正确率和召回率设为0)
•recall召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
•F值 = 正确率 * 召回率 * 2/ ( 正确率 + 召回率 )
//遍历allTestUsers(test数据集中用户的id),返回(user,precesion,recall,f)
val allTestUsers = test.map(x => (x._1)). collect.toList
val result =for( user <- allTestUsers;
val movieIds = movies.keys;
val ratedMovies = train.filter(_.user == user).map(_.product);
val movieCans = movieIds.subtract(ratedMovies);
// 预测,针对用户user
val k = 5; //val k =10;//val k =15;//val k = 20;
val preMovies = model.predict(movieIds.map((user,_))).sortBy(x => x.rating,false).map(x => x.product).take(k);
// 测试数据中用户评价过的电影
val ratedMoviesTest = test.filter(_._1 == user).map(_._2).collect.toList;
// 推荐并且用户看过的电影
val same = preMovies.intersect(ratedMoviesTest);
val precesion = same.size.toDouble / preMovies.size;
val recall = same.size.toDouble / ratedMoviesTest.size;
val f = precesion * recall *2/(precesion +recall)
) yield (user,precesion,recall,f)
//result返回的格式为List((user1,x1,y1,z1),(user2,x2,y2,z2), (user3,x3,y3,z3), (user4,x4,y4,z4), (user4,x4,y4,z4),(user5,x5,y5,z5), (user6,x6,y6,z6) (user7,x7,y7,z7), (user8,x8,y8,z8),(user9,x9,y9,z9), (user10,x10,y10,z10),) ,而我们想要的返回格式为(k,准确率的平均值,召回率的平均值,F的平均值),所以定义了下面的final_average()。注意: F为NaN无意义,所以不为NaN的F才用来计算F的均值,。
def final_average(result:List[(Int, Double, Double, Double)]) = {
val precision_average = result.map(x => x._2).sum/10
val recall_average = result.map(x => x._3).sum/10
val f_average = result.map(x => x._4).filter(x => !x.isNaN())sum/10
println(k,precision_average,recall_average,f_average)
}
//输出
final_average(result)二、相关图表
1. 时间戳分割点截图:
![]()
2.建模截图(包含参数)

3.评价截图
(1)10个用户,k=5
![]()
(2)10个用户,k=10
![]()
(3)10个用户,k=15

![]()
(4)10个用户,k=20

![]()
三、不同模型对比
不同k值precesion、recall表格及图


总结1:随着K的增大,recall先增大再减小
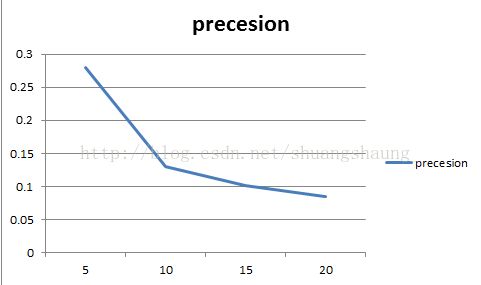
总结2:随着K的增大,precesion先增大再减小
总结3:Recall和precesion随K增大,变化趋势相同。

总结4:随K的增大,F先增大,再减小