【十五】Spark Streaming整合Kafka使用Direct方式(使用Scala语言)
官网介绍
Kafka提供了新的consumer api 在0.8版本和0.10版本之间。0.8的集成是兼容0.9和0.10的。但是0.10的集成不兼容以前的版本。
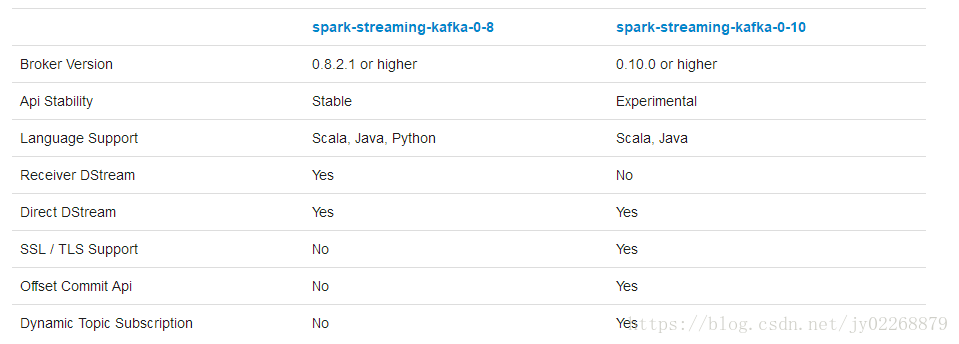
这里使用的集成是spark-streaming-kafka-0-8。官方文档
配置SparkStreaming接收从kafka来的数据有两种方式。老的方式要使用Receiver,新的方式是Spark1.3后引进的不用Receiver。
Approach 1: Receiver-based Approach
Approach 2: Direct Approach (No Receivers)
这里介绍第二种使用Direct的方式。
这是一种新的模式,在Spark1.3中引进的,它有更加强壮的端到端的数据保障。它代替了使用Receiver接收数据。
它周期性的去查询Kafka每一个topic partition最新的偏移量,通过每一个批次处理偏移范围。
当启动Job去处理数据以后,Kafka'simple consumer API 从Kafka中去读偏移量的范围(和读文件系统很类似)。
这个新特性在Spark1.3中支持Scala和Java,在1.4中可以支持Python。
这种方式和Receiver方式对比的优点:
1.简化了并行度。不需要创建多个input Kafka streams再粘合起来。而是直接使用directStream来处理。Spark Streaming将创建多个RDD partitions对接到Kafka paritions去消费,这样从Kafka中读取的数据就是并行的。在Kafka和RDD partitions之间是一对一的映射。
2.性能更高。能够达到零数据丢失。然而在Receiver方式中需要把数据写到WAL( Write Ahead Log)中才能零数据丢失。
3.能够满足“只执行一次“不重复消费。在Receiver方式中要使用Kafka的高级API,去存储消费偏移量在zookeeper中,这是一种传统的消费Kafka的数据方式。
而Direct方式也有一种缺点,不能更新zookeeper中的偏移量,所以基于zookeeper的kafka监控工具就没办法展示处理。每一个批次都需要自己把偏移量更新到zookeeper中去。
实战
1.启动zk
cd /app/zookeeper/bin
./zkServer.sh start
2.启动kafka
cd /app/kafka
bin/kafka-server-start.sh -daemon config/server.properties &
3.创建topic
bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 1 --topic spark_topic
4.控制台测试topic是否能够正常生成和消费信息
发送消息
bin/kafka-console-producer.sh --broker-list node1:9092 --topic spark_topic
hello kafka
hello spark streaming
9092是server.properties中配置的监听端口

消费消息
bin/kafka-console-consumer.sh --zookeeper node1:2181 --topic spark_topic

5.项目目录
6.pom.xml
4.0.0
com.sid.spark
spark-train
1.0
2008
2.11.8
0.8.2.1
2.2.0
2.9.0
1.4.4
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
org.scala-lang
scala-library
${scala.version}
org.apache.kafka
kafka_2.11
${kafka.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
servlet-api
javax.servlet
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming-flume_2.11
${spark.version}
org.apache.spark
spark-streaming-flume-sink_2.11
${spark.version}
org.apache.spark
spark-streaming-kafka-0-8_2.11
${spark.version}
net.jpountz.lz4
lz4
1.3.0
mysql
mysql-connector-java
5.1.31
org.apache.commons
commons-lang3
3.5
src/main/scala
src/test/scala
org.scala-tools
maven-scala-plugin
compile
testCompile
${scala.version}
-target:jvm-1.5
org.apache.maven.plugins
maven-eclipse-plugin
true
ch.epfl.lamp.sdt.core.scalabuilder
ch.epfl.lamp.sdt.core.scalanature
org.eclipse.jdt.launching.JRE_CONTAINER
ch.epfl.lamp.sdt.launching.SCALA_CONTAINER
org.scala-tools
maven-scala-plugin
${scala.version}
7.代码
package com.sid.spark
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by jy02268879 on 2018/7/19.
*
* Spark Streaming 基于 Direct 对接Kafka
*/
object KafkaDirect {
def main(args: Array[String]): Unit = {
if(args.length != 2){
System.err.println("Usage: KafkaDirect ")
System.exit(1)
}
val Array(brokers,topics) = args
val sparkConf = new SparkConf().setAppName("KafkaReceiver").setMaster("local[3]")
val ssc = new StreamingContext(sparkConf,Seconds(5))
/**
* @param ssc StreamingContext object
* @param kafkaParams Kafka
* configuration parameters. Requires "metadata.broker.list" or "bootstrap.servers"
* to be set with Kafka broker(s) (NOT zookeeper servers), specified in
* host1:port1,host2:port2 form.
* If not starting from a checkpoint, "auto.offset.reset" may be set to "largest" or "smallest"
* to determine where the stream starts (defaults to "largest")
* @param topics Names of the topics to consume
* @tparam K type of Kafka message key
* @tparam V type of Kafka message value
* @tparam KD type of Kafka message key decoder
* @tparam VD type of Kafka message value decoder
* @return DStream of (Kafka message key, Kafka message value)
*/
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)
val messages= KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc,kafkaParams,topicsSet
)
messages.print()
messages.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
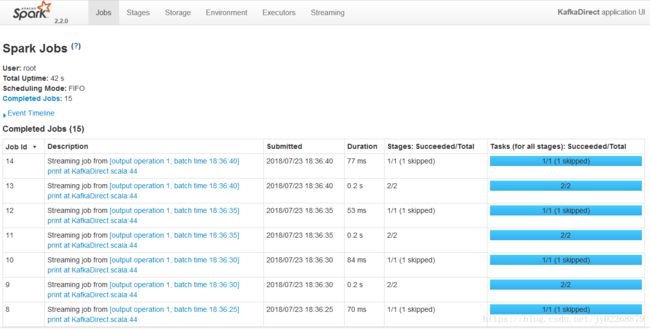
8.运行代码


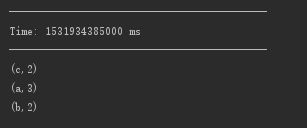
9.在Kafka生成数据 a a a b b c c

10.IDEA查看结果
本地运行成功后测试提交到服务器上运行
修改代码注释掉setAppName和setMaster

maven打包
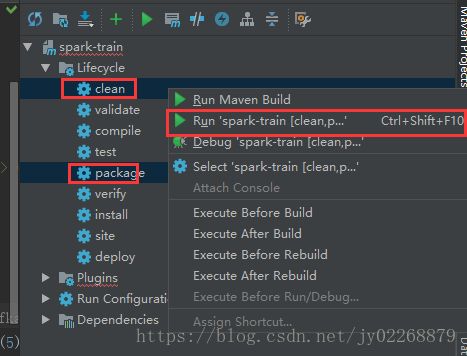
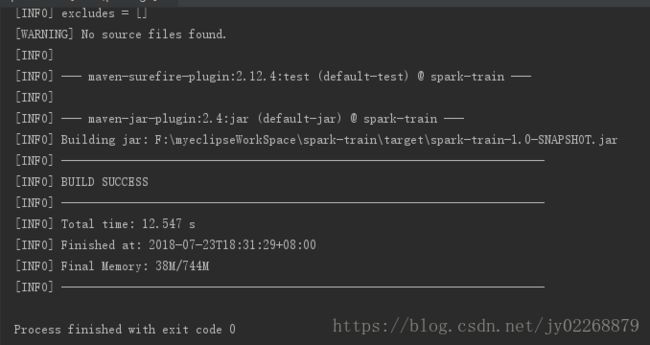
把target生成的jar包传到spark服务器上去
运行
cd /app/spark/spark-2.2.0-bin-2.9.0/bin
./spark-submit --class com.sid.spark.KafkaDirect --master local[2] --name KafkaDirect --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 /app/spark/test_data/spark-train-1.0-SNAPSHOT.jar node1:9092 spark_topic

UI
http://node1:4040