- docker部署kafka(单节点) + Springboot集成kafka
wsdhla
dockerkafkaspringbootzookeeper
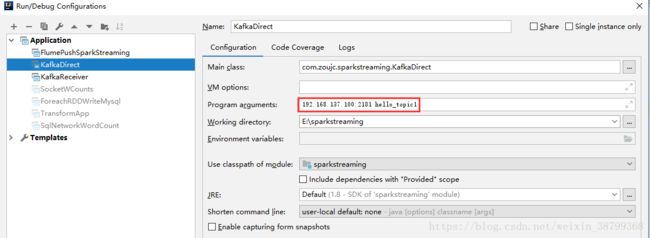
环境:操作系统:win10Docker:DockerDesktop4.21.1(114176)、DockerEnginev24.0.2SpringBoot:2.7.15步骤1:创建网络:dockernetworkcreate--subnet=172.18.0.0/16net-kafka步骤2:安装zk镜像dockerpullzookeeper:latestdockerrun-d--restarta
- 【Python系列】Python 解释器的站点配置
Kwan的解忧杂货铺@新空间代码工作室
s1Pythonpython开发语言
欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:kwan的首页,持续学习,不断总结,共同进步,活到老学到老导航檀越剑指大厂系列:全面总结java核心技术点,如集合,jvm,并发编程redis,kafka,Spring,微服务,Netty等常用开发工具系列:罗列常用的开发工具,如IDEA,M
- Kafka Raft知识整理
自东向西
Kafka知识整理kafka分布式
背景Kafka2.8之后,移除了Zookeeper,而使用了自己研发的KafkaRaft。为什么移除Zookeeper?原来Zookeeper在Kafka中承担了Controller选举、Broker注册、TopicPartition注册和选举、Consumer/Producer元数据管理和负载均衡等。即承担了各种元数据的保存和各种选举。而Zookeeper并“不快”,集群规模大了之后,很容易成为
- Kafka topic、producer、consumer的基础使用
病妖
Kafkakafkabigdata分布式
文章目录Kafka初级前言1.topic的增删改查2.生产者的消息发送3.消费者消费数据Kafka初级前言关于kafka的集群安装这里就先跳过,如果需要相关资料以及学习视频的可以在留言下留下联系信息(邮箱、微信、qq都可),我们直接从kafka的学习开始,这是初级阶段,这篇博主主要讲述kafka的命令行操作。1.topic的增删改查创建主题:切换到kafka的相关目录,进行以下命令行操作bin/k
- kafka消费能力压测:使用官方工具
ezreal_pan
kafka工具kafka分布式
背景在之前的业务场景中,我们发现Kafka的实际消费能力远低于预期。尽管我们使用了kafka-go组件并进行了相关测试,测试情况见《kafka-go:性能测试》这篇文章。但并未能准确找出消费能力低下的原因。我们曾怀疑这可能是由我的电脑网络带宽问题或Kafka部署时的某些未知配置所导致。为了进一步确定问题的根源,我们决定对Kafka的消费能力进行压力测试。在这篇《kafka的Docker镜像使用说明
- Kafka的生产者和消费者模型
Java资深爱好者
kafka分布式
Kafka的生产者和消费者模型是一种消息传递模式,以下是该模型的详细描述:一、生产者(Producer)定义:生产者是消息的生产者,它将消息发布到Kafka的主题(Topic)中。功能:生产者可以将消息发送到指定的分区(Partition)或让Kafka自行选择分区。生产者还可以控制消息的序列化和分区策略。工作原理:生产者通过Kafka提供的API与Kafka集群进行通信,将消息异步发送到指定的主
- 阶段 1:Kafka基础认知
AI航海家(Ethan)
分布式kafkakafka分布式
核心知识点Kafka三大核心角色:Producer(生产者):负责向Kafkatopic推送数据。可以理解为数据流的发起者。Broker:Kafka服务器节点,负责存储数据流。Kafka集群由多个broker组成。Consumer(消费者):负责从Kafkatopic中读取和处理数据,可以是日志分析服务、数据库服务器等。核心概念:Topic:Kafka的基本单元,类似于数据库的表结构,用于对数据进
- 正式开源:使用Kafka FDW 加载数据到 Apache Cloudberry™
数据库开源软件
ApacheCloudberry™(Incubating)由GreenplumDatabase核心开发者创建,是一款领先且成熟的开源大规模并行处理(MassivelyParallelProcessing,MPP)数据库。它基于开源版的PivotalGreenplumDatabase®衍生而来,但采用了更新的PostgreSQL内核,并具备更先进的企业级功能。Cloudberry可以作为数据仓库使用
- RabbitMQ,RocketMQ,Kafka 消息模型对比分析
Java架构设计
javaJava程序员消息模型开发语言程序人生
消息模型消息队列的演进消息队列模型早期的消息队列是按照”队列”的数据结构来设计的。生产者(Producer)产生消息,进行入队操作,消费者(Consumer)接收消息,就是出队操作,存在于服务端的消息容器就称为消息队列。当然消费者也可能不止一个,存在的多个消费者是竞争的关系,消息被其中的一个消费者消费了,其它的消费者就拿不到消息了。发布订阅模型如果一个人消息想要同时被多个消费者消费,那么上面的队列
- Kafka日志文件探秘:从数据解析到故障排查的完整指南
磐基Stack专业服务团队
Kafkakafka分布式
#作者:猎人文章目录1、查看Log文件基本数据信息2、index文件健康性检查(--index-sanity-check)3、转储文件(--max-message-size)4、偏移量解码(--offsets-decoder)5、日志数据解析(--transaction-log-decoder)6、查询Log文件具体数据(--print-data-log)7、查看index文件具体内容8、查看ti
- 消息队列简述
八二年的栗子
java
消息队列(MessageQueue),是分布式系统中重要的组件,其通用的使用场景可以简单地描述为:当不需要立即获得结果,但是并发量又需要进行控制的时候,差不多就是需要使用消息队列的时候。消息队列主要解决了应用耦合、异步处理、流量削锋等问题。当前使用较多的消息队列有RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMq等,而部分数据库如Redis、Mysql以及
- kafka搭建
瀟湘夜雨-秋雨梧桐
kafka分布式zookeeper大数据数据仓库
文章目录前言一、kafka是什么?二、应用场景1.实时数据处理2.日志聚合与分析3.事件驱动架构场景三、kafka搭建流程1.确定环境2.整理机器清单3.确定组件版本4JDK安装5kafka安装5.1master安装5.2slave_1从节点安装5.3slave_2从节点安装5.4配置环境变量5.5启动kafak5.5kafka集群一键管理脚本总结前言Kafka以其卓越的性能、高可靠性和可扩展性,
- Spring Boot 整合 Kafka 详解
码农爱java
KafkaKafkaMQSpringBoot微服务中间件1024程序员节
前言:上一篇分享了Kafka的一些基本概念及应用场景,本篇我们来分享一下在SpringBoot项目中如何使用Kafka。Kafka系列文章传送门Kafka简介及核心概念讲解SpringBoot集成Kafka引入Kafka依赖在项目的pom.xml文件中引入Kafka依赖,如下:org.springframework.cloudspring-cloud-starter-stream-kafka3.1
- linux 搭建kafka集群
节点。csn
linuxkafka运维
目录、一、环境准备二、文件配置三、集群启动一、环境准备1、我这里是准备三台服务器节点ipnode1192.168.72.132node2192.168.72.133node3192.168.72.1342、安装jdklinux环境安装jdk_openjdk1.8.0_345-CSDN博客3、下载kafka安装包安装包下载wget--nhttps://downloads.apache.org/kaf
- 【Redis系列】Redis安装与使用
m0_74825409
面试学习路线阿里巴巴redis数据库缓存
???欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:kwan的首页,持续学习,不断总结,共同进步,活到老学到老导航檀越剑指大厂系列:全面总结java核心技术点,如集合,jvm,并发编程redis,kafka,Spring,微服务,Netty等常用开发工具系列:罗列常用的开发工具,如IDE
- Flink在指定时间窗口内统计均值,超过阈值后报警
小的~~
flink均值算法大数据
1、需求统计物联网设备收集上来的温湿度数据,如果5分钟内的均值超过阈值(30摄氏度)则发出告警消息,要求时间窗口和阈值可在管理后台随时修改,实时生效(完成当前窗口后下一个窗口使用最新配置)。物联网设备的数据从kafka中读取,配置数据从mysql中读取,有个管理后台可以调整窗口和阈值大小。2、思路使用flink的双流join,配置数据使用广播流,设备数据使用普通流。3、实现代码packagecu.
- 【动态路由】系统Web URL资源整合系列(后端技术实现)【apisix实现】
飞火流星02027
URL整合apisix反向代理apisix网关apisix实现web资源整合系统URL资源整合apisix基于请求参数的路由apisix基于请求头的路由APISIXDashboard
需求说明软件功能需求:反向代理功能(描述:apollo、eureka控、apisix、sentinel、普米、kibana、timetask、grafana、hbase、skywalking-ui、pinpoint、cmak界面、kafka-map、nacos、gateway、elasticsearch、oa-portal业务应用等多个web资源等只能通过有限个代理地址访问),不考虑SSO。软件质
- Apache ZooKeeper 分布式协调服务
slovess
分布式apachezookeeper
1.ZooKeeper概述1.1定义与定位核心定位:分布式系统的协调服务,提供强一致性的配置管理、命名服务、分布式锁和集群管理能力核心模型:基于树形节点(ZNode)的键值存储,支持Watcher监听机制生态地位:Hadoop/Kafka等生态核心依赖,分布式系统基础设施级组件1.2设计目标强一致性:所有节点数据最终一致(基于ZAB协议)高可用性:集群半数以上节点存活即可提供服务顺序性:全局唯一递
- 深入理解Kafka—如何保证Exactly Once语义
AI天才研究院
Python实战自然语言处理人工智能语言模型编程实践开发语言架构设计
作者:禅与计算机程序设计艺术1.简介Kafka是一种高吞吐量、分布式、可分区、多副本的消息系统。它在使用上非常灵活,可以作为Pulsar、RabbitMQ的替代品。但同时也带来了一些复杂性和问题,比如ExactlyOnce语义。从本质上说,ExactlyOnce就是对消费者读取的数据只要不丢失,就一定能得到一次完整的处理,而且不会被重复处理。确保ExactlyOnce语义一直是企业级应用中必须考虑
- 【kafka系列】生产者
漫步者TZ
kafkakafka数据库大数据
目录发送流程1.流程逻辑分析阶段一:主线程处理阶段二:Sender线程异步发送核心设计思想2.流程关键点总结重要参数一、核心必填参数二、可靠性相关参数三、性能优化参数四、高级配置五、安全性配置(可选)六、错误处理与监控典型配置示例关键注意事项发送流程序列化与分区:消息通过Partitioner选择目标分区(默认轮询或哈希),序列化后加入RecordAccumulator缓冲区。批次合并:Sende
- 【kafka系列】broker
漫步者TZ
kafka数据库分布式kafka
目录Broker接收生产者消息和返回消息给消费者的流程逻辑分析Broker处理生产者消息的核心流程Broker处理消费者消息的核心流程关键点总结Broker接收生产者消息和返回消息给消费者的流程逻辑分析Broker处理生产者消息的核心流程接收请求Broker的SocketServer接收来自生产者的ProduceRequest(基于Reactor网络模型)。请求解析与验证解析请求头(Topic、P
- 【kafka系列】如何选择消息语义?
漫步者TZ
kafkakafka分布式数据库大数据
目录业务权衡如何选择消息语义?业务权衡维度At-Most-OnceAt-Least-OnceExactly-Once消息丢失风险高低无消息重复风险无高无网络开销最低(无重试)中等(可能重试)最高(事务+协调)适用场景可容忍丢失的实时数据流不允许丢失的日志采集金融交易、精准统计如何选择消息语义?At-Most-Once:优先性能与低延迟,接受数据丢失(如实时监控)。At-Least-Once:优先可
- kafka动态监听主题
S Y H
微服务组件kafkalinq分布式
简单版本importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.core.ConsumerFactory;importorg.springframework.kafka.listener.ConcurrentMessageListenerContainer;import
- 【kafka系列】Exactly Once语义
漫步者TZ
kafkakafka数据库大数据分布式
目录1.Exactly-Once语义的定义2.Kafka实现Exactly-Once的机制3.端到端Exactly-Once示例场景描述3.1生产者配置与代码3.2消费者配置与代码4.异常场景与Exactly-Once保障场景1:生产者发送消息后宕机场景2:消费者处理消息后宕机场景3:Broker宕机5.关键实现细节6.总结1.Exactly-Once语义的定义Exactly-Once(精确一次)
- 【Golang学习之旅】Go 语言微服务架构实践(gRPC、Kafka、Docker、K8s)
程序员林北北
架构golang学习微服务云原生kafka
文章目录1.前言:为什么选择Go语言构建微服务架构1.1微服务架构的兴趣与挑战1.2为什么选择Go语言构建微服务架构2.Go语言简介2.1Go语言的特点与应用2.2Go语言的生态系统3.微服务架构中的gRPC实践3.1什么是gRPC?3.2gRPC在Go语言中的实现1.前言:为什么选择Go语言构建微服务架构1.1微服务架构的兴趣与挑战随着互联网技术的飞速发展,尤其是云计算的普及,微服务架构已经成为
- zipkin备忘
dzl84394
springboot学习日志javazipkin
server安装https://zipkin.io/pages/quickstart.html这里提供了几种安装方式当天他可以吧数据方存cassandra,kafka,es,等地方服务器直接下载curl-sSLhttps://zipkin.io/quickstart.sh|bash-s得到zipkin.jar启动nohup/usr/local/jdk17/bin/java-jarzipkin.ja
- org.apache.kafka.common.errors.TimeoutException
一张假钞
apachekafka分布式
个人博客地址:org.apache.kafka.common.errors.TimeoutException|一张假钞的真实世界使用kafka-console-producer.sh向远端Kafka写入数据时遇到以下错误:$bin/kafka-console-producer.sh--broker-list172.16.72.202:9092--topictestThisisamessage[20
- kafka的kafka-console-consumer.sh和kafka-console-producer.sh如何使用
WilsonShiiii
kafka分布式
一、两款工具对比功能用途kafka-console-consumer.sh是简单的命令行消费者工具,主要用于在控制台显示从Kafka主题消费的消息,适用于测试生产者是否正常发送消息、查看消息格式等调试场景。kafka-consumer-perf-test.sh则专为测试Kafka消费者性能设计,能在指定条件下(如消息数量、线程数等)测试消费者吞吐量等性能指标,帮助进行性能评估、优化及容量规划。参数
- RocketMQ与kafka如何解决消息积压问题?
一个儒雅随和的男子
RocketMQrocketmqkafka分布式
前言 消息积压问题简单来说,就是MQ存在了大量没法快速消费完的数据,造成消息积压的原因主要在于“进入的多,消费的少”,或者生产的速度过快,而消费速度赶不上,基于这一问题,我们主要介绍如何通过前期的开发设置去避免出现消息积压的问题。主要介绍两款产品RocketMQ和Kafka的解决方式,以及其差异,本质上的差异就是RocketMQ与Kafka之间的存储结构差异带来的,基本的处理思路还是怎么控制生产
- 浅聊MQ之Kafka与RabbitMQ简用
天天向上杰
kafkarabbitmq分布式
(前记:内容有点多,先看目录再挑着看。)Kafka与RabbitMQ的使用举例Kafka的使用举例安装与启动:从ApacheKafka官网下载Kafka中间件的运行脚本。解压后,通过命令行启动Zookeeper(Kafka的运行依赖于Zookeeper)。启动Kafka的服务器进程。基本功能实现:生产者:启动生产者进程,向指定的主题(Topic)发送消息。消费者:启动消费者进程,从指定的主题中接收
- 解读Servlet原理篇二---GenericServlet与HttpServlet
周凡杨
javaHttpServlet源理GenericService源码
在上一篇《解读Servlet原理篇一》中提到,要实现javax.servlet.Servlet接口(即写自己的Servlet应用),你可以写一个继承自javax.servlet.GenericServletr的generic Servlet ,也可以写一个继承自java.servlet.http.HttpServlet的HTTP Servlet(这就是为什么我们自定义的Servlet通常是exte
- MySQL性能优化
bijian1013
数据库mysql
性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有:
a.优化查询
b.优化数据库结构
- ThreadPool定时重试
dai_lm
javaThreadPoolthreadtimertimertask
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
- Oracle 查看数据库的连接情况
周凡杨
sqloracle 连接
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
- 类的继承
朱辉辉33
java
类的继承可以提高代码的重用行,减少冗余代码;还能提高代码的扩展性。Java继承的关键字是extends
格式:public class 类名(子类)extends 类名(父类){ }
子类可以继承到父类所有的属性和普通方法,但不能继承构造方法。且子类可以直接使用父类的public和
protected属性,但要使用private属性仍需通过调用。
子类的方法可以重写,但必须和父类的返回值类
- android 悬浮窗特效
肆无忌惮_
android
最近在开发项目的时候需要做一个悬浮层的动画,类似于支付宝掉钱动画。但是区别在于,需求是浮出一个窗口,之后边缩放边位移至屏幕右下角标签处。效果图如下:
一开始考虑用自定义View来做。后来发现开线程让其移动很卡,ListView+动画也没法精确定位到目标点。
后来想利用Dialog的dismiss动画来完成。
自定义一个Dialog后,在styl
- hadoop伪分布式搭建
林鹤霄
hadoop
要修改4个文件 1: vim hadoop-env.sh 第九行 2: vim core-site.xml <configuration> &n
- gdb调试命令
aigo
gdb
原文:http://blog.csdn.net/hanchaoman/article/details/5517362
一、GDB常用命令简介
r run 运行.程序还没有运行前使用 c cuntinue
- Socket编程的HelloWorld实例
alleni123
socket
public class Client
{
public static void main(String[] args)
{
Client c=new Client();
c.receiveMessage();
}
public void receiveMessage(){
Socket s=null;
BufferedRea
- 线程同步和异步
百合不是茶
线程同步异步
多线程和同步 : 如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法
多线程和异步:多线程可以做不同的事情,涉及到线程通知
&
- JSP中文乱码分析
bijian1013
javajsp中文乱码
在JSP的开发过程中,经常出现中文乱码的问题。
首先了解一下Java中文问题的由来:
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,
- js实现页面跳转重定向的几种方式
bijian1013
JavaScript重定向
js实现页面跳转重定向有如下几种方式:
一.window.location.href
<script language="javascript"type="text/javascript">
window.location.href="http://www.baidu.c
- 【Struts2三】Struts2 Action转发类型
bit1129
struts2
在【Struts2一】 Struts Hello World http://bit1129.iteye.com/blog/2109365中配置了一个简单的Action,配置如下
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configurat
- 【HBase十一】Java API操作HBase
bit1129
hbase
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
- nginx gzip
ronin47
nginx gzip
Nginx GZip 压缩
Nginx GZip 模块文档详见:http://wiki.nginx.org/HttpGzipModule
常用配置片段如下:
gzip on; gzip_comp_level 2; # 压缩比例,比例越大,压缩时间越长。默认是1 gzip_types text/css text/javascript; # 哪些文件可以被压缩 gzip_disable &q
- java-7.微软亚院之编程判断俩个链表是否相交 给出俩个单向链表的头指针,比如 h1 , h2 ,判断这俩个链表是否相交
bylijinnan
java
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
- Spring源码学习-JdbcTemplate batchUpdate批量操作
bylijinnan
javaspring
Spring JdbcTemplate的batch操作最后还是利用了JDBC提供的方法,Spring只是做了一下改造和封装
JDBC的batch操作:
String sql = "INSERT INTO CUSTOMER " +
"(CUST_ID, NAME, AGE) VALUES (?, ?, ?)";
- [JWFD开源工作流]大规模拓扑矩阵存储结构最新进展
comsci
工作流
生成和创建类已经完成,构造一个100万个元素的矩阵模型,存储空间只有11M大,请大家参考我在博客园上面的文档"构造下一代工作流存储结构的尝试",更加相信的设计和代码将陆续推出.........
竞争对手的能力也很强.......,我相信..你们一定能够先于我们推出大规模拓扑扫描和分析系统的....
- base64编码和url编码
cuityang
base64url
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
- web应用集群Session保持
dalan_123
session
关于使用 memcached 或redis 存储 session ,以及使用 terracotta 服务器共享。建议使用 redis,不仅仅因为它可以将缓存的内容持久化,还因为它支持的单个对象比较大,而且数据类型丰富,不只是缓存 session,还可以做其他用途,一举几得啊。1、使用 filter 方法存储这种方法比较推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简
- Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR模式']
dcj3sjt126com
数据库
public function getMinLimit () { $sql = "..."; $result = yii::app()->db->createCo
- solr StatsComponent(聚合统计)
eksliang
solr聚合查询solr stats
StatsComponent
转载请出自出处:http://eksliang.iteye.com/blog/2169134
http://eksliang.iteye.com/ 一、概述
Solr可以利用StatsComponent 实现数据库的聚合统计查询,也就是min、max、avg、count、sum的功能
二、参数
- 百度一道面试题
greemranqq
位运算百度面试寻找奇数算法bitmap 算法
那天看朋友提了一个百度面试的题目:怎么找出{1,1,2,3,3,4,4,4,5,5,5,5} 找出出现次数为奇数的数字.
我这里复制的是原话,当然顺序是不一定的,很多拿到题目第一反应就是用map,当然可以解决,但是效率不高。
还有人觉得应该用算法xxx,我是没想到用啥算法好...!
还有觉得应该先排序...
还有觉
- Spring之在开发中使用SpringJDBC
ihuning
spring
在实际开发中使用SpringJDBC有两种方式:
1. 在Dao中添加属性JdbcTemplate并用Spring注入;
JdbcTemplate类被设计成为线程安全的,所以可以在IOC 容器中声明它的单个实例,并将这个实例注入到所有的 DAO 实例中。JdbcTemplate也利用了Java 1.5 的特定(自动装箱,泛型,可变长度
- JSON API 1.0 核心开发者自述 | 你所不知道的那些技术细节
justjavac
json
2013年5月,Yehuda Katz 完成了JSON API(英文,中文) 技术规范的初稿。事情就发生在 RailsConf 之后,在那次会议上他和 Steve Klabnik 就 JSON 雏形的技术细节相聊甚欢。在沟通单一 Rails 服务器库—— ActiveModel::Serializers 和单一 JavaScript 客户端库——&
- 网站项目建设流程概述
macroli
工作
一.概念
网站项目管理就是根据特定的规范、在预算范围内、按时完成的网站开发任务。
二.需求分析
项目立项
我们接到客户的业务咨询,经过双方不断的接洽和了解,并通过基本的可行性讨论够,初步达成制作协议,这时就需要将项目立项。较好的做法是成立一个专门的项目小组,小组成员包括:项目经理,网页设计,程序员,测试员,编辑/文档等必须人员。项目实行项目经理制。
客户的需求说明书
第一步是需
- AngularJs 三目运算 表达式判断
qiaolevip
每天进步一点点学习永无止境众观千象AngularJS
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {
- Spark算子:统计RDD分区中的元素及数量
superlxw1234
sparkspark算子Spark RDD分区元素
关键字:Spark算子、Spark RDD分区、Spark RDD分区元素数量
Spark RDD是被分区的,在生成RDD时候,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时候,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。
可以利用RDD的mapPartitionsWithInd
- Spring 3.2.x将于2016年12月31日停止支持
wiselyman
Spring 3
Spring 团队公布在2016年12月31日停止对Spring Framework 3.2.x(包含tomcat 6.x)的支持。在此之前spring团队将持续发布3.2.x的维护版本。
请大家及时准备及时升级到Spring
- fis纯前端解决方案fis-pure
zccst
JavaScript
作者:zccst
FIS通过插件扩展可以完美的支持模块化的前端开发方案,我们通过FIS的二次封装能力,封装了一个功能完备的纯前端模块化方案pure。
1,fis-pure的安装
$ fis install -g fis-pure
$ pure -v
0.1.4
2,下载demo到本地
git clone https://github.com/hefangshi/f