第1章 初探大数据
1、1导学
功能实现
统计imooc(慕课网)主站最受欢迎的课程/手记的Top N访问次数
按地市统计imooc主站最受欢迎的Top N课程
按流量统计imocc主站最受欢迎的Top N课程
大数据的到来
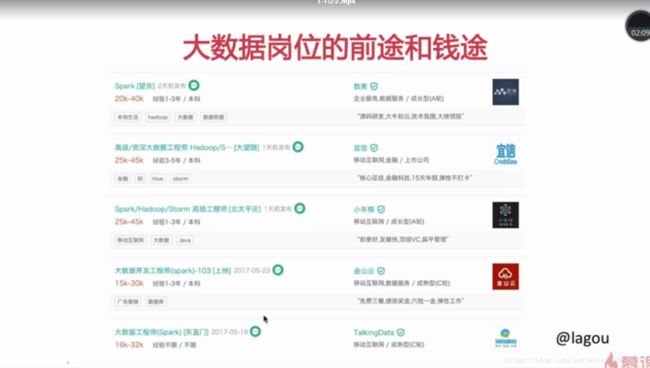
任职要求
.熟悉Linux操作系统,熟悉Linux shell 编程
.熟悉Java或者scala语言,具有一年以上实际开发经验
.熟悉spark sql 或 spark streaming 或spark core等编程,具有实际开发经验
.熟悉Hadoop生态环境或分布式存储与计算技术
.具有良好的开发习惯
.思维敏捷,学习能力强,具有良好的逻辑分析能力
技能:对Hadoop生态或者spark的掌握程度
快速突破口
掌握Hadoop,Hive的基本使用
重点突破Spark
明确DataFrame/Dataset在整个Spark框架中的核心地位
课程安排
Hadoop部分
1、大数据概述
2、零基础学习Hadoop框架三大核心组件的使用
3、Hive快速入门及使用
Spark SQL部分
1、认知Spark及生态圈
2、零基础搭建Spark环境(源码编译、Spark部署)
3、Spark SQL概述
4、如何从hive平滑的过渡到Spark SQL
5、DataFrame/Dataset操作详解
6、外部数据源详解
7、Spark SQL的愿景深度剖析
8、慕课网日志分析项目实战
前置基础知识要求
- 熟悉基本SQL的使用
- 熟悉常用的Liunx的命令’
- 熟悉一门编程语言(Java/Scala/Python)均可
选择Scala作为开发语言的原因
- Spark内核源码采用Scala开发的
- Spark相对Java开发更加优雅和方便
- 主站有Scala基础课程的视频
- http://www.imooc.com/learn/613
环境参数
- Liunx版本:CentOS(6.4)
- Hadoop版本:CDH(hadoop-2.6.0-cdh5.7.0)
- Hive版本:CDH(hive-1.1.0-cdh5.7.0)
- Scala版本:2.11.8
- Spark版本:spark-2.1.0
- 开发工具:IDEA
1、2如何学好大数据
- 官网、官网、官网
- 英文、英文、英文
- 项目实战对知识点进行巩固和融会贯通
- 社区活动:Meetup、开源社区大会、线下沙龙等
- 切记:多动手、多练习、贵在坚持
1、3开发环境
liunx版本对应
- CentOS(本课程选择的是6.4)
- Ubuntu
- Redhat
- 会提供纯净版的安装镜像文件
Hadoop版本对比及选择
- Apache社区
- CDH版本(本课程选择是cdh5.7.0系列)
- HDP版本
- 会提供OOTB的整套课程的开发环境
课程整套CDH相关软件下载地址:http://archive.cloudera.com/cdh5/cdh/5/
在生产或者测试环境选择对应的CDH版本时,一定要采用相同尾号的版本
开发工具对比选择
- IDEA(本课程的选择)
- Eclipse
1、4 ooptb镜像文件使用介绍
1、软件包
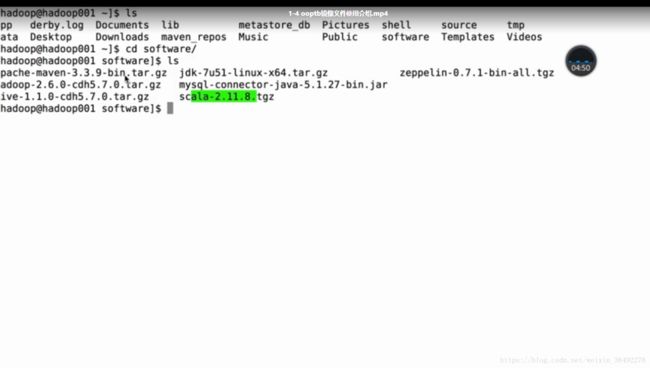
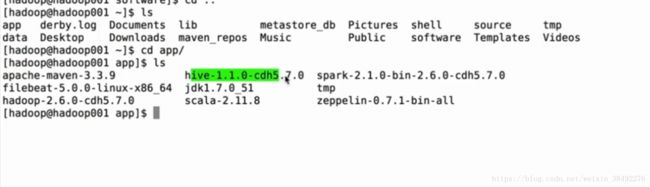
2、安装路径
3、spark源码编译

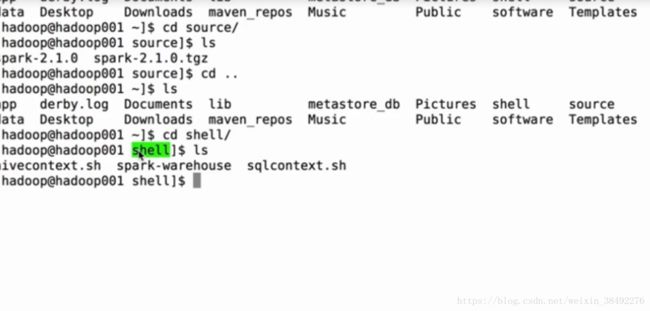
4、课程脚本文件
1、5大数据概述
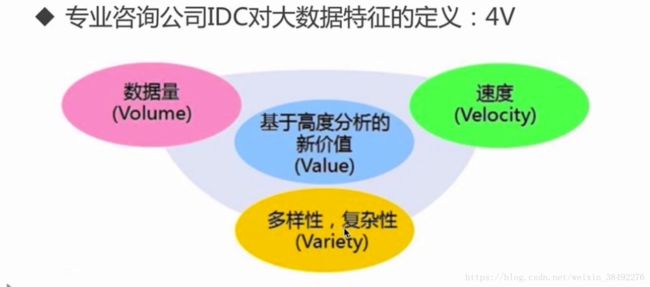
大数据带来的技术变革
- 技术瓶颈
- 存储瓶颈
- 数据库瓶颈
大数据公司现存的模式
- 手握大数据,但是没有利用好
- 没有大数据,但是知道如何帮助有数据的人利用它
- 既有数据,又有大数据思维
1、6 Hadoop概述
Hadoop的由来
是一个虚构名称
Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名
对于Apache的顶级项目来说,projectname.apache.org
Hadoop:hadoop.apache.org
Hive:hive.apache.org
Spark:spark.apache.org
HBase:hbase.apache.org
什么是Hadoop
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运行和存储。
- Distributed File System(HDFS)
- YARN
- MapReduce
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
狭义Hapdoop VS 广义Hapdoop
狭义的Hapdoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapRuduce)和资源调度(YARN)的平台 ;
广义的Hadoop:指的就是Hapdoop生态系统,Hapdoop生态系统是一个庞大的概念,Hadoop是最重要最基础的一个部分;生态系统中的每一个系统只解决某一个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统;
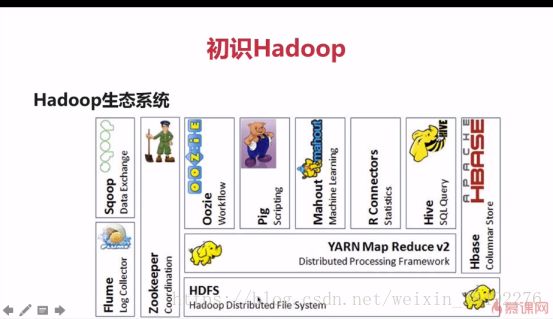
为什么很多公司选择Hadoop作为大数据平台的解决方案?
1)、源码开源
2)、社区活跃、参与者很多 Speak
3)、涉及到分布式存储和计算的方方面面:
flume 进行数据采集
Speak/MR/Hive等进行数据处理
HDFS/HBASE进行数据存储
4)、已得到企业界的验证
1、7 HDFS概述及设计目标
分布式文件系统(HDFS)
什么是HDFS
Hadoop实现了一个分布式文件系统(Hadoop DIstributed File System),简称HDFS
源来于Google的GFS论文
发表于2003年,HDFS是GFS克隆版
HDFS的设计目标
- 非常巨大的分布式文件系统
- 运行在普通廉价的硬件上
- 易扩展,为用户提供性能不错的文件存储服务
1、8HDFS架构
1 Master(NameNode/NN) 带 N个Slaves(DataNode/DN)
包括:HDFS,YARS/HBase都是这种架构
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html

1个文件会被拆分成多个Block
blocksize:128M
130M ==> 2个Block: 128M 和 2M
NN:
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
A typical deployment has a dedicated machine that runs only the NameNode software.
Each of the other machines in the cluster runs one instance of the DataNode software.
The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
建议:NN和DN是部署在不同的节点上
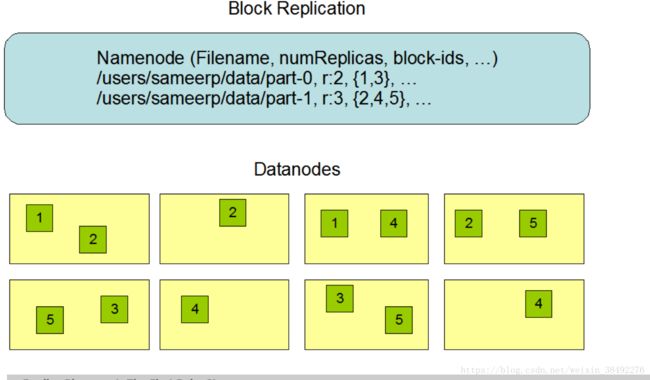
1、9HDFS副本机制
The File System Namespace
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file. HDFS supports user quotas and access permissions. HDFS does not support hard links or soft links. However, the HDFS architecture does not preclude implementing these features.
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.
Data Replication
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file.
All blocks in a file except the last block are the same size, while users can start a new block without filling out the last block to the configured block size after the support for variable length block was added to append and hsync.
An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.
The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.
replication factor:副本系数、副本因子
All blocks in a file except the last block are the same size
1、10 Hadoop下载jdk
Hadoop环境搭建
使用版本:hadoop-2.6.0-cdh5.7.0
- 1)jdk 环境搭建
- 2)liunx机器常用参数设置
- 3)hadoop-env.sh
- 4)core-site.xml hdfs-site.xml
- 5-7)格式化HDFS 启停HDFS
1) 下载Hadoop
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
本课程软件存放目录
hadoop
/home/hadoop
/software:存放的是安装的软件包
安装到 /app:存放的是所以软件安装目录
/data:存放的是课程所有使用的测试数据目录
/source:存放都的是软件源码目录 比如spark
2)、JDK安装
解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app
建议把bin目录配置到系统环境变量
添加到系统环境变量: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
export JAVA_HOME=$JAVA_HOME/bin:$PATH
使得环境变量生效 source ~/.bash_profile
验证java是否配置成功: java -version
1、11 机器参数的设置
Hadoop环境搭建
使用版本:Hadoop-2.6.0-cdh5.7.0
jdk环境搭建
linux机器常用参数设置
3)机器参数设置
hostname:hadoop001
修改机器名 vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop001
设置ip和hostname的映射关系:/etc/hosts
192.169.199.200 hadoop001
127.0.0.1 localhost
ssh 免密码登录(本步骤可以省略,但是后面重启hadoop进程时需要手工输入密码才行)
ssh-keygen -t rsa
执行后查看ssh : cd ~/.ssh/
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
1-12 hdfs核心配置文件内容配置
1、安装hadoop的步骤
1) 安装完jdk以后开始按照Hadoop
2)先下载hadoop
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
3)解压
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /home/hadoop/app/
2、hadoop配置文件修改
~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
1) hadoop -env.sh
查看JAVE_HOME : echo $JAVA_HOME
加上配置JDK环境
export JAVA_HOME=/root/java/jdk1.8.0_161
2)core-site.xml
fs.defaultFS
hafs://localhost:8020
hadoop.tmp.dir
/home/hadoop/app/tmp
3)hdfs-site.xml
具体可以参照官方:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
1-13 hdfs格式化及启停
4)格式化HDFS
注意:这一步操作,只是在一次使用时格式化
1)Format the filesystem:
$ bin/ hdfs namenode -format
在bin 目录下执行 ./hdfs namenode -format
5)启动HDFS
Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
验证是否启动成功
jps
DataNode
SecondaryNameNode
NameNode
浏览器
http://hadoop001:50070
6)停止HDFS
When you’re done, stop the daemons with:
$ sbin/stop-dfs.sh
1-14 hdfs shell常用操作
详情可参考
http://hadoop.apache.org/docs/r3.0.3/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#dfs
hdfs的命令和liunx命令很相似
Is get mkdir rm put
1-15 HDFS优缺点
HDFS优点
数据余,硬件容错 适合存储大文件
处理流式的数据访问 可构建在廉价机器上
HDFS缺点
低延迟的数据访问
小文件存储
1-16MapReduce概述
(了解即可,重点是spark)
什么是MapReduce
源于Google的MapReduce论文,论文发表于2014年12月
Hadoop MapReduce是 Google MapReduce的克隆版
MapReduce优点:
- 易于编程
- 良好的扩展性
- 高容错性
- 海量数据离
- 线处理&易开发&易运行
MapReduce缺点:实时流式计算 DAG计算
1-17 mapreduce编程模型及wordcount
MapReduce编程模型
input
map&reduce
output
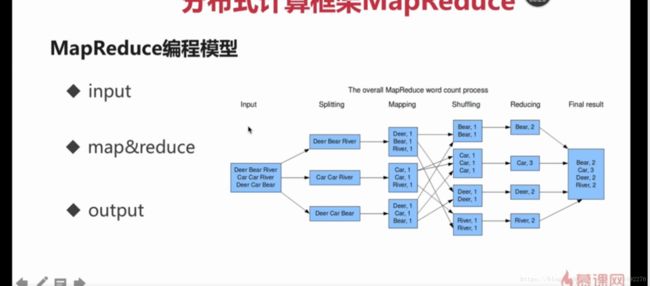
代码查看官网
http://hadoop.apache.org/docs/r3.0.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
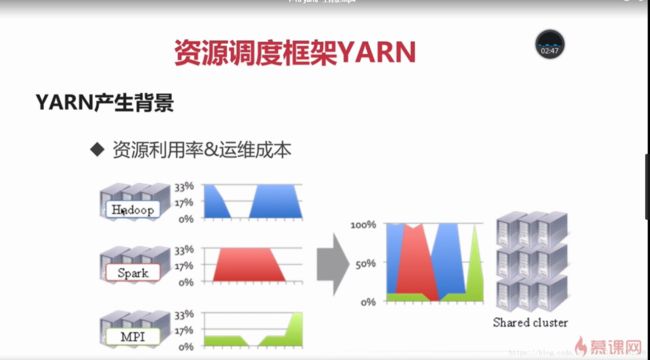
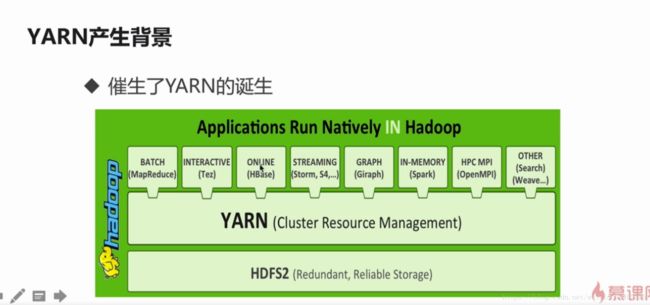
1-18 yarn产生背景
yarn是资源调度框架
YARN产生的背景
mapreduce1.x存在的问题

1-19 yarn架构和执行流程
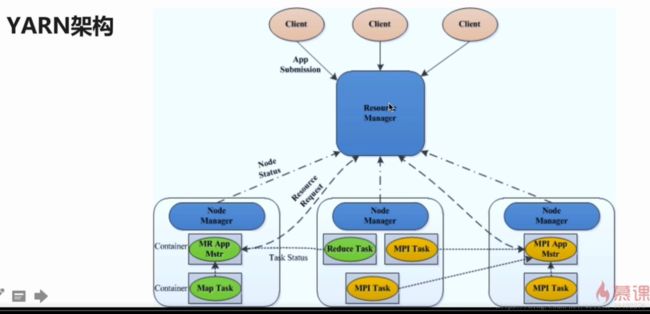
1RM(ResourceManager)+n NM(NodeManager)
ResourceManager的职责:一个集群active状态的RM只有一个,负责整个集群的资源管理和调度
1)处理客户端的请求(启动/杀死)
2) 启动/监控ApplicationMaster(一个作业对应一个AM)
3)监控NM
4)系统的资源分配和调度
NodeManager:整个集群有N个,负责单个节点的资源和使用以及task的运行情况
1)定期向RM汇报本节点的资源使用请求和各个Container的运行情况
2)接收并处理RM的container启停的各种命令
3)单个节点的资源管理和任务管理
ApplicationMaster:每个应用/作业对应一个,负责应用程序的管理
1)数据拆分
2)为应用程序向RM申请资源(container),并分给内部任务
3)与NM通讯以启停task,task是运行在container中的
4)task的监控和容错
Container
对任务运行情况的描述:CPU、memory、环境变量
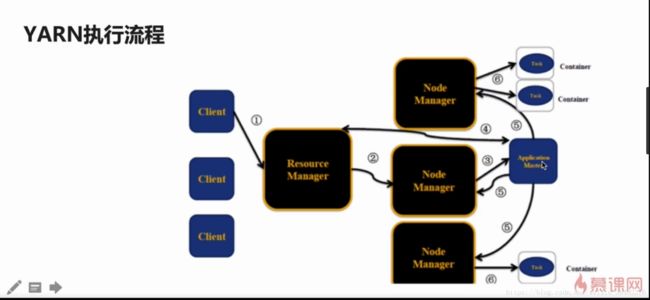
YARN执行流程
1)用户项YARN提交作业
2)RM为该作业分配第一个container(AM)
3)RM会与对应的NM通信,要求NM在这个container上启动应用程序的AM
4)AM首先向RM注册,然后AM将各个任务申请资源,并监控运行情况
5)AM采用轮转方式通过RPC协议向RM申请和领取资源
6)AM申请资源以后,便和相应的NM通信,要求NM启动任务
7)NM启动我们作业对应的task
1-20 -YARN环境搭建及提交作业到YARN上运行
YARN环境搭建
参看文档:
http://hadoop.apache.org/docs/r3.0.3/hadoop-project-dist/hadoop-common/SingleCluster.html
YARN on a Single Node
1、Configure parameters as follows:
etc/hadoop/mapred-site.xml:
etc/hadoop/yarn-site.xml:
2、Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
3、验证是否启动成功
jps
ResourceManager
NodeManager
web:
Browse the web interface for the ResourceManager; by default it is available at:
- ResourceManager - http://localhost:8088/
停止YARN:
$ sbin/stop-yarn.sh
TODO
运行作业等的搭建完环境再写
1-21 -Hive产生背景及Hive是什么
官网:https://hive.apache.org/index.html
大数据数据仓库Hive
Hive产生背景
MapReduce编程不方便
HDFS上缺少Schema
(指的是一组DDL语句集,该语句集完整地描述了数据库的结构。还有一种是物理上的Schema,指的是数据库中的一个名字空间,它包含一组表、视图和存储过程等命名对象。物理Schema可以通过标准SQL语句来创建、更新和修改。)
Hive是什么
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
1、由Facebook开源,最初用于解决海量结构化的日志数据统计问题
2、构建在Hadoop之上的数据仓库
3、Hive定义一种类SQL查询语言:HQL(类似SQL但不是完全相同)
4、通常用于离线数据处理(采用MapReduce)
5、底层支持多种不同的执行引擎
Hive底层执行引擎有MapReduce、Tez、Speak
Hive on MapReduce
Hive on Tez
Hive on Speak
6、支持多种不同的压缩格式,存储格式以及自定义函数
压缩:GZIP/LZO、Snappy、BZIP2
存储:TextFile、SequenceFile、RCFile,、ORC 、Parquet
UDF:自定义函数
1-22 -为什么要使用Hive及Hive发展历程
为什么要使用Hive
- 简单、容易上手(提供了类似SQL查询语言HQL)
- 为超大数据集设计的计算、存储扩展能力(MR计算,HDFS存储)
- 统一的元数据管理(可用Presto/Impala/SparkSQL等共享数据)
Hive发展历程


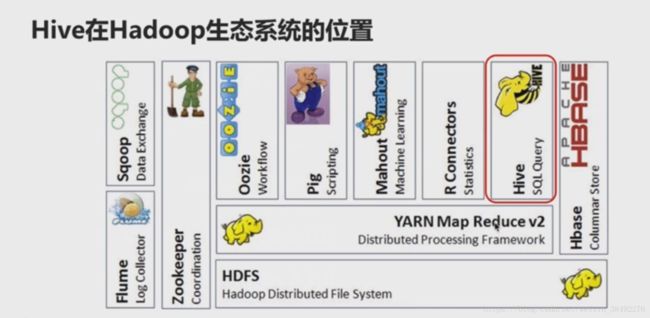
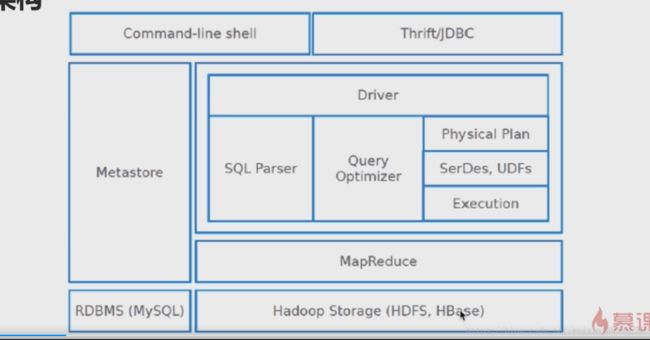
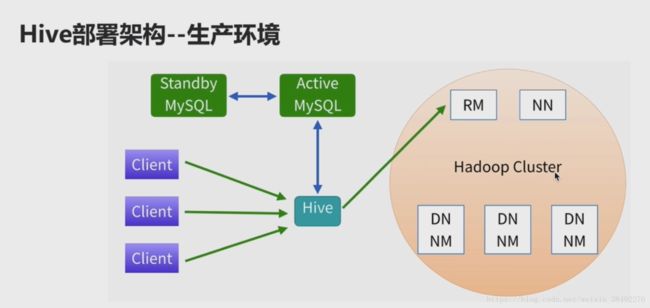
1-23 -Hive体系架构及部署架构
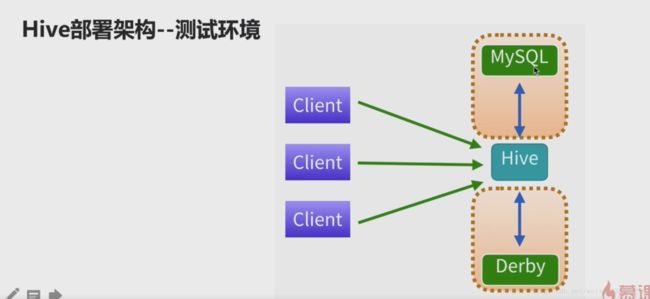
部署架构
1-24 -Hive环境搭建
Hive 环境搭建
使用版本:hive-1.1.0-cdh5.7.0
1)Hive下载:http://archive.cloudera.com/cdh5/cdh/5/
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
2 )解压
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C /home/hadoop/app/
3)配置
参考文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
1) $ export HIVE_HOME={{pwd}}
系统变量
系统环境变量(~/hahs_profile)
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
连接一个mysql yun install XXX
1) 配置hadoop目录
vi hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
2)配置mysql源信息
配置连接mysql信息
javax.jdo.option.ConnectionURL
jdbc:mysql://59818a0fa1d8a.bj.cdb.myqcloud.com:5169/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
sag18747231218
3)拷贝mysql驱动到&HIVE_HOME/lib
cp ~/software/mysql-connector-java-5.1.27-bin.jar
4)启动hive
/home/hadoop/app/hive-1.1.0-cdh5.7.0/bin
./hive
1-25 -Hive基本使用
可参考:
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
Hive基本操作
创建表
使用hive完成wordcount统计(对比MapReduce实现的易用性)
create table hive_wordcount(context string);
加载数据到hive表
LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
load data local inpat '/home/hadoop/data/hello.txt' into table hive_wordcount
select word,count(1) from hive_wordcount lateral view explode(split(context,'\t')) wc as word group by word
explode(split(context,'\t')):是把每行记录按照制表符进行拆解
hive sql 提交执行以后会生成mr作业,并在yarn上运行
案例:员工表(emp.txt)和部门表()操作
原数据在/home/hadoop/data
创建员工表
create table emp (
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
创建部门表 dept
create table dept(
deptno int,
dname string,
location string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';\
加载
load data local inpat '/home/hadoop/data/emp.txt' into table emp
load data local inpat '/home/hadoop/data/dept.txt' into table dept
求每个部门的人数
select depton,count(1) from emp group by deptno;