浅谈ATSS
转载请注明出处
https://blog.csdn.net/weixin_45691429/article/details/107452436
文章链接
(https://github.com/sfzhang15/ATSS)
或者(https://paperswithcode.com/paper/bridging-the-gap-between-anchor-based-and)
Contributions

- 指出基于锚框和无锚检测器的本质区别在于如何定义正训练样本和负训练样本。
- 提出了一种自适应的训练样本选择方法,根据目标的统计特性自动选择正、负训练样本。
- 证明在图像上的每个位置平铺多个锚来检测对象是一个无用的操作。
- 在不引入任何额外开销的情况下,在MS COCO上实现最先进的性能。
切入点
在于基于anchor-based和anchor-free的目标检测算法之间的效果差异到底是由什么原因造成的?
——分别选了2个代表性算法:RetinaNet(anchor-based)和FCOS(anchor-free)。
回顾
RetinaNet
论文地址https://paperswithcode.com/method/retinanet
出发点:one-stage的准确率比不上two-stage,是样本的类别不均衡导致的。
RetinaNet算法是基于anchor-based,为了验证创新点focal loss的有效性提出RetinaNet网络。
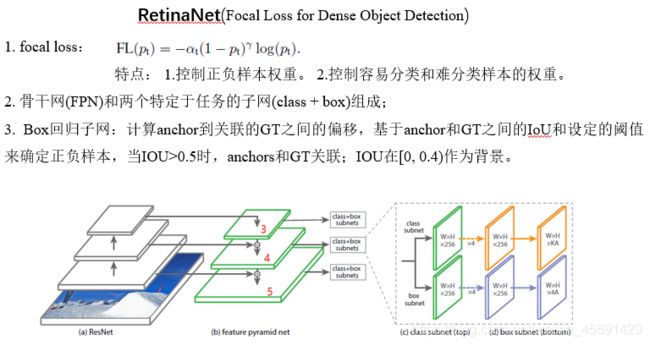
RetinaNet是一个统一的网络,由骨干网和两个特定于任务的子网组成。主干网使用特征金字塔(FPN)。FPN给标准的卷积神经网络增加一个自顶向下的路径和侧向连接,来构建一个丰富的、多尺度的特征金字塔。对于两个子网,第一个子网在主干的输出上执行对象分类;第二个子网执行边界框回归。对于Box回归子网,它在每个空间位置是4A线性输出,对于每个空间位置的每个A锚点,这4个输出预测 锚和ground-truth框之间的相对偏移。这个边框回归子网就是计算anchor到关联的GT之间的偏移,基于anchor和GT之间的IoU和设定的阈值来确定正负样本,当IOU大于0.5时,anchors和GT关联;IOU在[0, 0.4)作为背景;每个anchor最多关联一个GT; IOU在[0.4, 0.5)之间的anchors丢弃。
FCOS
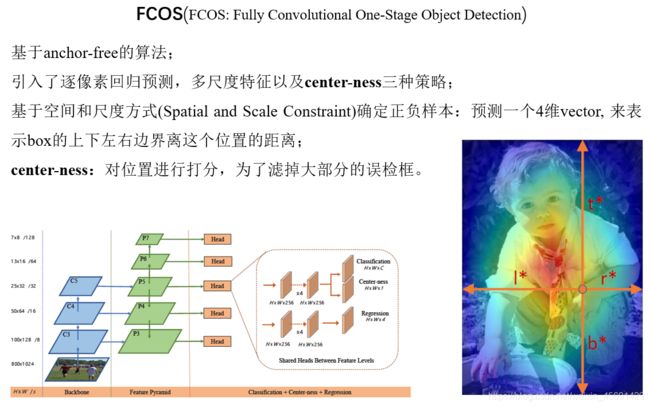
FCOS算法是基于anchor-free,引入了逐像素回归预测,多尺度特征以及center-ness三种策略。FCOS算法在对目标物体框中所有的点进行目标框回归时,是用的距离各个边的长度, 预测一个4维 vector, 用来表示box的上下左右边界离这个位置的距离。主干网络为FPN结构,利用多尺度策略得到不同的五个尺度层来处理不同的目标框,也就是对这五个尺度都做逐像素回归,输出包含三个分支,类别,边界框回归以及center-ness分支。center-ness分支就是为了滤掉大部分的误检框。它对位置进行打分, 这样远离需要检测的目标中心位置的位置, 分数会较低, 这样就把当前这个位置表示的box的分数降低, 在非极大值抑制的时候就可以把这个分值低的抑制掉,相反,分值高的会作为候选预测框。
回到本篇文章
这篇文章分析了RetinaNet和FCOS在算法上的差异,这是这篇文章工作点之一,主要有以下3点:
1、 数量上的差异:RetinaNet在特征图上每个地方铺设多个anchor,而FCOS在特征图上每个点只铺设一个中心点。
2、 正负样本确定方式:RetinaNet基于anchor和GT之间的IoU和设定的阈值来确定正负样本,而FCOS通过GT中心点和铺设点之间的距离和尺寸来确定正负样本。
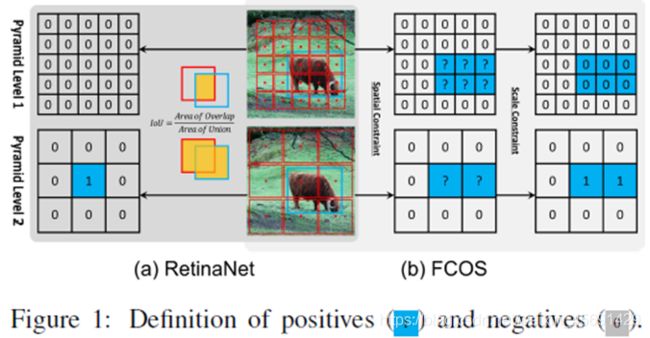 Figure1,0表示负样本,1表示正样本。牛这张图像中蓝色框表示GT,红色框表示RetinaNet铺设的anchor,红色点表示FCOS铺设的点,左右两边类似表格上的数值表示最终确定的正负样本。(b)FCOS首先使用空间约束来查找空间维度中的候选正样本,然后使用比例约束来选择比例维度中的最终正样本。相反的,(a)Retinanet网利用IoU在空间和尺度维度上同时直接选择最终的正样本。这两种不同的样本选择策略产生不同的正负样本。
Figure1,0表示负样本,1表示正样本。牛这张图像中蓝色框表示GT,红色框表示RetinaNet铺设的anchor,红色点表示FCOS铺设的点,左右两边类似表格上的数值表示最终确定的正负样本。(b)FCOS首先使用空间约束来查找空间维度中的候选正样本,然后使用比例约束来选择比例维度中的最终正样本。相反的,(a)Retinanet网利用IoU在空间和尺度维度上同时直接选择最终的正样本。这两种不同的样本选择策略产生不同的正负样本。
3、回归状态:RetinaNet通过回归矩形框的偏移量2个角点偏置进行预测 框位置和大小,而FCOS是基于中心点预测四条边和中心点的距离进行预测 框位置和大小。

Figure2:蓝色框和点表示GT,红色框表示RetinaNet的正样本,红色点表示FCOS的正样本。从(b)(c)可以看出,对于正样本,RetinaNet的回归起始状态是一个box,而FCOS是一个点。因为(b)所示RetinaNet从锚定框和对象框之间的偏移进行box的回归的,,而(c)所示,FCOS从锚定点到边界的四个距离进行回归的 。
对比实验
- 首先将RetinaNet在每个点铺设的anchor数量减少到1,也就是和FCOS保持一致,这样第1点差异就不存在了。另外,由于FCOS论文中用了一些训练的技巧,如Table1所示,比如Group Normalization、GIoU Loss等,所以为了公平对比2个算法,作者在RetinaNet上也加上了这些技巧,最后mAP达到37.0,基本上和FCOS的37.8很接近了。
 2. 接下来作者对剩余的0.8mAP差异进行了分析,做了Table2这个实验。在第一个差异锁定的基础上分析第2、3点差异。
2. 接下来作者对剩余的0.8mAP差异进行了分析,做了Table2这个实验。在第一个差异锁定的基础上分析第2、3点差异。
 按行看,Intersection over Union这一行,表示RetinaNet和FCOS都采用相同的样本选择策略即基于IoU方式来获得正负样本,无论是从一个点还是一个box开始回归,最终表现都没有明显差异37.0vs36.9;同样第二行表示RetinaNet和FCOS都采用基于距离和尺度方式确定正负样本,无论是从一个box还是一个点回归,二者的mAP也是一样。所以结论就是:回归方式的不同并不是造成FCOS和RetinaNet效果差异的原因,也就是前面说的第3点差异是不影响的。
按行看,Intersection over Union这一行,表示RetinaNet和FCOS都采用相同的样本选择策略即基于IoU方式来获得正负样本,无论是从一个点还是一个box开始回归,最终表现都没有明显差异37.0vs36.9;同样第二行表示RetinaNet和FCOS都采用基于距离和尺度方式确定正负样本,无论是从一个box还是一个点回归,二者的mAP也是一样。所以结论就是:回归方式的不同并不是造成FCOS和RetinaNet效果差异的原因,也就是前面说的第3点差异是不影响的。
按列看,Box这一列的两个数值表示将RetinaNet的正负样本确定方式从IoU换成和FCOS一样的基于距离和尺度,回归方式相同时, mAP就从37.0上升到37.8;同样Point这一列的两个数值表示将FCOS的正负样本确定方式从基于距离和尺寸换成和RetinaNet一样的基于IoU,那么mAP就从37.8降为36.9。所以结论就是:如何确定正负样本才是造成FCOS和RetinaNet效果差异的原因,也就是前面说的第2点差异才是根源。
ATSS
根据在如何定义正负样本上的差异,这篇文章提出了自适应训练样本选择ATSS来确定正负样本。

 第3至6行
第3至6行
对于GT集合中每一个GT g,首先为g中的候选正样本 建立一个空集,记为Cg。在每个特征层上,根据L2距离选择那些中心点 距g中心 最近的k个候选anchor boxes,就是说每层会选出9个box,把他们放在Si中,并更新Cg。假设有L个特征金字塔层,则GT框g将有k×L个可检出的正样本。
第7至9行
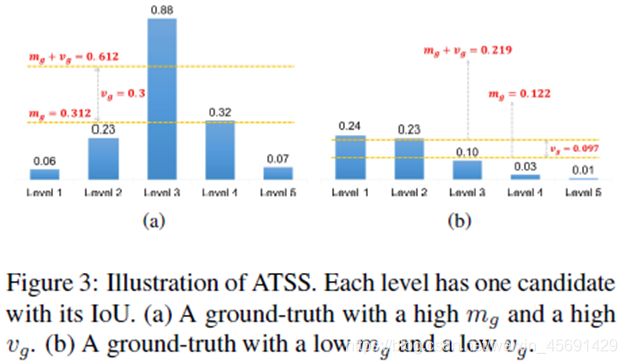
计算出这些候选正样本Cg与g之间的IoU记为(Dg),它的平均值和标准差分别计算为mg和vg。Mg是对目标对象的预设锚点适用性的度量;vg是衡量哪些层适合检测这个目标对象的度量。这在后面会详细介绍。
利用这些统计数据,在第10行中,以tg=mg+vg的形式获得GT g的IoU阈值。
第11至15行
最后选择IoU大于或等于阈值tg的候选样本作为最终正样本。值得注意的是在第12行,将正样本的中心限制GT框内,中心外目标的box是较差的候选对象,这不利于训练,所以应排除在外。此外,如果一个锚定框被分配给多个GT box,那么将选择IoU最高的一个。其余为负样品。
ATSS方法动机

ATSS算法有效性实验分析
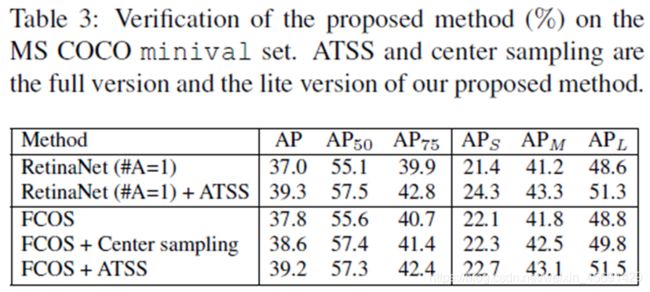 对于RetinaNet带ATSS比不带ATSS会提高2.3点的AP,对于FCOS来说,带ATSS比不带ATSS会提高1.4个点的AP。(Center sampling:简化版,只将ATSS中一些思想运用到FCOS中,比如改变选择候选正样本的方法,这点不是很明白)这些改进主要是由于根据每个GT的统计特征自适应地选择正样本。方法只是重新定义正负样本,而不会产生任何额外的开销,因此这些改进可以被认为是无成本的。
对于RetinaNet带ATSS比不带ATSS会提高2.3点的AP,对于FCOS来说,带ATSS比不带ATSS会提高1.4个点的AP。(Center sampling:简化版,只将ATSS中一些思想运用到FCOS中,比如改变选择候选正样本的方法,这点不是很明白)这些改进主要是由于根据每个GT的统计特征自适应地选择正样本。方法只是重新定义正负样本,而不会产生任何额外的开销,因此这些改进可以被认为是无成本的。
算法鲁棒性分析
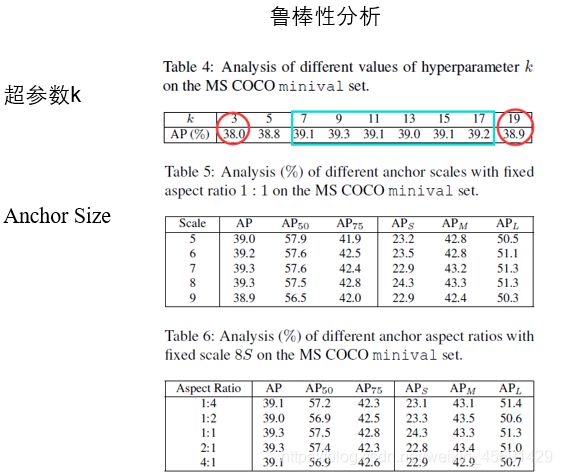
这个算法只需要一个超参数k和一个相关的锚框设置。
超参数K,用它来从每个金字塔级别中选择候选的正样本。如表4所示,将k值设为3,5,7,9,11,13,15,17,19来训练检测器。发现ATSS这个算法对k从7到17的变化一点儿都不敏感。过大的k(如19)会导致太多低质量的候选框,从而略微降低性能。k太小(如3)会导致准确度明显下降,因为候选正样本太少会导致统计不稳定性。
我的理解是将原本retinanet中设置的这个超参数K=9迁移到这篇文章提出的方法中仍然是良好的,说明了它具有很强的鲁棒性,那对于ATSS可以说是没有超参数的。
Anchor Size。方法利用锚盒来定义正样本,并研究了锚定尺寸的影响。在实验中,每个位置都会平铺一个带有8S(S表示金字塔级别的总步幅大小)的方形锚。如表5所示,在文中对不同尺度的方形锚[5,6,7,8,9]进行了实验,性能相当稳定。此外,还对8S锚框进行了几种不同纵横比的试验,如表6所示。性能对这种变化也不敏感。结果表明,该方法对不同的锚定设置具有较强的鲁棒性。
2.锚框数量及尺度纵横比分析
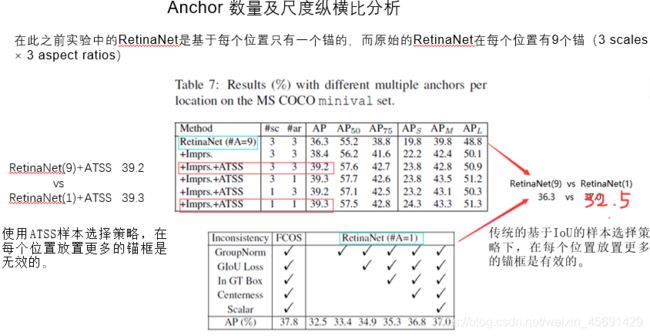 之前实验是基于每个位置只有一个锚的RetinaNet。而原始的RetinaNet在每个位置有9个锚(3 scales × 3 aspect ratios纵横比)(标记为RetinaNet(#A=9)),如表7第一行所示,达到36.3%的AP。此外,将表1中的这些普遍改进也可用于RetinaNet(#A=9),改进的叫为Imprs,那么AP性能从36.3%提高到38.4%。在没有使用ATSS的情况下,RetinaNet(#A=9)比RetinaNet(#A=1)性能有所提高,38.4 vs37.0。这说明表明,在传统的基于IoU的样本选择策略下,在每个位置放置更多的锚盒是有效的。
之前实验是基于每个位置只有一个锚的RetinaNet。而原始的RetinaNet在每个位置有9个锚(3 scales × 3 aspect ratios纵横比)(标记为RetinaNet(#A=9)),如表7第一行所示,达到36.3%的AP。此外,将表1中的这些普遍改进也可用于RetinaNet(#A=9),改进的叫为Imprs,那么AP性能从36.3%提高到38.4%。在没有使用ATSS的情况下,RetinaNet(#A=9)比RetinaNet(#A=1)性能有所提高,38.4 vs37.0。这说明表明,在传统的基于IoU的样本选择策略下,在每个位置放置更多的锚盒是有效的。
但是,使用ATSS后,会得出相反的结论,也就是说放置更多的锚盒是无效的。具体地说, RetinaNet(9)+ATSS 39.2 vs RetinaNet(1)+ATSS 39.3达到了类似性能,表7第三和第六行所列。此外,当我们将锚框尺度或纵横比的数量从3改为1时,结果几乎不变,如表7第四和第五行所示。换言之,只要正确选择正样本,无论在每个位置平铺多少锚,结果都是相同的。所以,在ATSS方法下,在每个位置贴多个锚是一个无用的操作,关键在于选择合适的正样本。
检测器对比实验
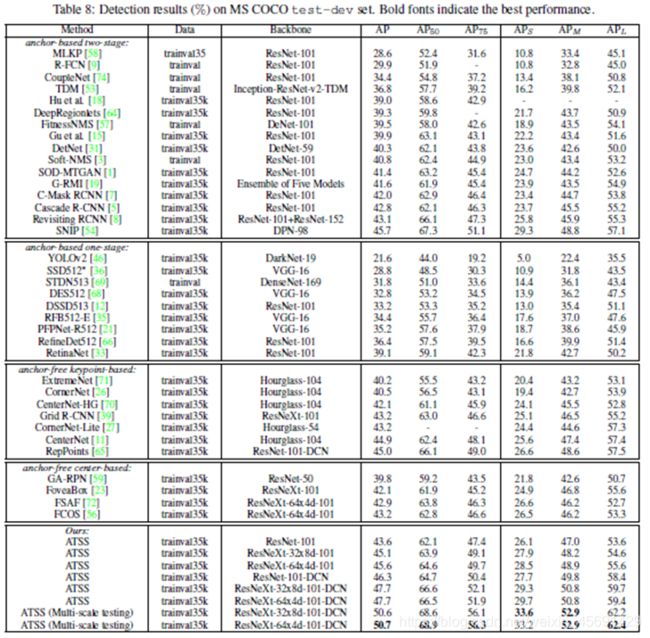
将最终模型与其他最新对象检测器进行了比较如表8中所示。如表8所示,使用ResNet-101的方法获得43.6%的AP,这比所有具有相同主干的方法都好,包括级联R-CNN(42.8%AP)、C-掩码RCNN(42.0%AP)、RetinaNet(39.1%AP)和RefineDet(36.4%AP)。通过使用更大的骨干网ResNeXt-32x8d-101和ResNeXt-64x4d-101,AP准确率进一步提高到45.1%和45.6%。45.6%的AP结果优于所有的无锚和基于锚的检测器,只比SNIP低0.1%(45.7%的AP),后者引入了改进的多尺度训练和测试策略。
由于这个方法是关于正样本和负样本的定义,所以它与当前的大多数技术兼容和互补。因此,结合使用可变形卷积网络(DCN)与ResNet系列。DCN使ResNet-101、ResNeXt-32x8d-101和ResNeXt-64x4d-101的AP性能分别提高到46.3%、47.7%和47.7%。单模型和单尺度试验的最佳结果为47.7%,大大优于以往所有检测器。最后,在多尺度测试策略下,最佳模型达到了50.7%的AP。