Kaggle数据竞赛记录 - IEEE-CIS Fraud Detection
最近准备春招,之前打的kaggle竞赛过了很久回顾一下:IEEE-CIS Fraud Detection
排名:铜牌 Top9%,在公榜100多,后期没有什么时间,私榜直接掉400多,所以看了很多大神的笔记,来回顾一下。IEEE比赛链接
附另一个kaggle竞赛:Steel Defect Detection
赛题理解
反欺诈(Fraud Detection)通常是一个二类分类问题,即通过对已标签的交易(Transaction)信息建模,来预测未来的交易。
本次比赛参加人数有6000多人,由IEEE和Vesta主办的二分类预测比赛,提供了大量的加密后的信用卡交易数据, 用这些数据进行机器学习建模,并对测试数据(test data)进行概率预测。提交测试数据预测的(概率)结果,由系统打分,最终得到比赛成绩。该赛题的主要目标是识别出每笔交易是否是欺诈的。
-
工具:Jupyter Notebook或者kaggle本身的kernal,用LightGBM建立模型进行预测,比赛提分的关键在于对于数据的挖掘以及数据处理生成特征的策略选取。
参考第一名笔记 -
欺诈定义(打标签的逻辑)
- 交易与欺诈交易相关的用户的账户,email和账单地址有直接联系,定义为欺诈(isFraud=1)
- 欺诈用户的交易极少数有非欺诈交易
- 若该次交易发生120天后还没有被定义为欺诈,那么该次交易就是正常交易(isFraud=0)。
-
结果
- 有73838位用户是有2次或2次以上的交易,其中71575位 (96.9%)是没有欺诈标签的(isFraud=0),2134位 (2.9%)是全部都是欺诈标签(isFraud=1),只有129 位(0.2%)是既有欺诈标签也有非欺诈标签的。
数据介绍
数据主要分为2类:transaction交易数据,identity数据,train,test都有一共四个表。
train data已有isfraud标签,即isfraud = 0 or 1,train data约59万(欺诈占3.5%),测试集样本约50万。总共的特征维度有393 + 41 = 434维
transaction字段:isfraud,TransactionID, ProductCD,card1-6,addr1-2,d1-2 , P,R,c1-c14, D1-15, M1 - M9,V1-339
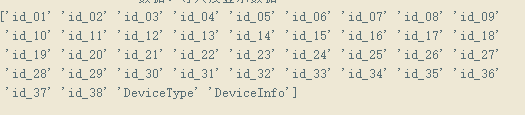
identity字段:DeviceType,DeviceInfo,id_1 - id_38
TransactionDT: 时间戳。第一个值是86400,它对应于一天中的秒数(60 * 60 * 24 = 86400),所以单位是秒。 因为最大值为15811131,我们知道数据跨度为6个月,相当于183天。
TransactionAMT: 美元为单位的交易金额。同时,有的数据有3位小数,并且对应的地址为空,猜测可能是外币交易。
ProductCD: 每条交易的产品编码
card1 - card6: 付款卡的信息,比如卡片种类,发行银行和国家等。
addr: 地址信息。地址的两列均是购买者的地址信息,addr1是地区,addr2是国家。
dist: 某种距离。包括但不限于帐单地址,邮寄地址,邮政编码,IP地址,电话区域等之间的距离。
P_ and (R__) emaildomain: 购买者和收款人的邮箱域名,一些交易不需要收款人,所以R__emaildomain为空。
C1-C14: 加密后的某计数项,例如发现与支付卡关联的地址数等。
D1-D15: t时间戳,例如和前一次交易之间的天数等。
M1-M9: 匹配信息,例如卡上的姓名和地址等。
Vxxx: Vesta生成的丰富的特征,包括排名,计数和其他实体关系。例如,与IP和电子邮件或地址相关联的支付卡在24小时内出现了多少次,等等。所有Vesta这些特征都是以数字形式给出的,里面的一些特征可能是分类特征编码后给出的值。
过程总结
- EDA
- 特征工程
- 模型选择
- 调参
- 模型融合
探索性数据分析 EDA
分析各个特征字段们与结果的关系
| 用户的唯一标识 原始数据中是没有uid这类的字段的,那么如何唯一标识用户?经过讨论区大神们的分析,结合三个字段:card1(银行卡的前多少位),addr1和D1 (用户开卡天数)。 确定了用户的唯一标识之后,我们并不能直接把它当作一个特征直接加入到模型中去,因为通过分析发现,测试集中有68.2%的用户是新用户,并不在训练集中。我们需要间接的使用uid,用uid构造一些聚合特征。 |
- 要用到的python包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBClassifier
from xgboost import XGBRegressor
import sklearn.metrics as metrics
from sklearn.model_selection import train_test_split, GridSearchCV, learning_curve
import lightgbm as lgbm
- 导入数据
def input_dataset(train_data_path):
print('====================数据:导入及显示数据====================')
train_transaction = pd.read_csv(train_data_path, index_col=0)
#train_identity = pd.read_csv('dataset/train_identity.csv', index_col=0)
# 显示所有列,pd.set_option 样式
pd.set_option('display.max_columns', None)
pd.set_option('display.max_columns', 5) # 最多显示五列
# 显示所有行
pd.set_option('display.max_rows', None)
pd.set_option('expand_frame_repr', False) # 不可换行
train_transaction_fraud = train_transaction[train_transaction['isFraud'] == 1]
print('总样本与欺诈样本数: ', len(train_transaction), ' ', len(train_transaction_fraud), )
return train_transaction
总样本与欺诈样本数: 590540 20663
- 分析数据,判断字段与结果的联系
def anaysis_data(train_transaction, col_name):
print('====================分析:该字段是否与欺诈有关系?====================')
print(train_transaction.groupby([col_name, 'isFraud'])['isFraud'].count())
print(train_transaction[[col_name, 'isFraud']].groupby([col_name]).mean())
train_transaction[[col_name, 'isFraud']].groupby([col_name]).mean().plot.bar()
plt.show()
特征工程
基础预处理、缺失值处理、降维等
- 数据预处理:对分类特征的数据进行单热编码:sklearn中使用 OneHotEncoder,LabelEncoder,pd.factorize
在上述的基础上,对于R_emaildomain和P_emaildomain特征,由于他们类别太多,这里用pd.factories处理成索引表示特征,而不会像get_dummies一样把该列铺开。
- 特征编码:主要有以下五种特征编码方式
# encoding function
# frequency encode频率编码
def encode_FE(df1, df2, cols):
for col in cols:
df = pd.concat([df1[col], df2[col]])
vc = df.value_counts(dropna=True, normalize=True).to_dict()
vc[-1] = -1
nm = col + "FE"
df1[nm] = df1[col].map(vc)
df1[nm] = df1[nm].astype("float32")
df2[nm] = df2[col].map(vc)
df2[nm] = df2[nm].astype("float32")
print(col)
# label encode
def encode_LE(col, train=X_train, test=X_test, verbose=True):
df_comb = pd.concat([train[col], test[col]], axis=0)
df_comb, _ = pd.factorize(df_comb[col])
nm = col
if df_comb.max() > 32000:
train[nm] = df_comb[0: len(train)].astype("float32")
test[nm] = df_comb[len(train):].astype("float32")
else:
train[nm] = df_comb[0: len(train)].astype("float16")
test[nm] = df_comb[len(train):].astype("float16")
del df_comb
gc.collect()
if verbose:
print(col)
def encode_AG(main_columns, uids, aggregations=["mean"], df_train=X_train, df_test=X_test, fillna=True, usena=False):
for main_column in main_columns:
for col in uids:
for agg_type in aggregations:
new_column = main_column + "_" + col + "_" + agg_type
temp_df = pd.concat([df_train[[col, main_column]], df_test[[col, main_column]]])
if usena:
temp_df.loc[temp_df[main_column] == -1, main_column] = np.nan
#求每个uid下,该col的均值或标准差
temp_df = temp_df.groupby([col])[main_column].agg([agg_type]).reset_index().rename(
columns={agg_type: new_column})
#将uid设成index
temp_df.index = list(temp_df[col])
temp_df = temp_df[new_column].to_dict()
#temp_df是一个映射字典
df_train[new_column] = df_train[col].map(temp_df).astype("float32")
df_test[new_column] = df_test[col].map(temp_df).astype("float32")
if fillna:
df_train[new_column].fillna(-1, inplace=True)
df_test[new_column].fillna(-1, inplace=True)
print(new_column)
# COMBINE FEATURES交叉特征
def encode_CB(col1, col2, df1=X_train, df2=X_test):
nm = col1 + '_' + col2
df1[nm] = df1[col1].astype(str) + '_' + df1[col2].astype(str)
df2[nm] = df2[col1].astype(str) + '_' + df2[col2].astype(str)
encode_LE(nm, verbose=False)
print(nm, ', ', end='')
# GROUP AGGREGATION NUNIQUE
def encode_AG2(main_columns, uids, train_df=X_train, test_df=X_test):
for main_column in main_columns:
for col in uids:
comb = pd.concat([train_df[[col] + [main_column]], test_df[[col] + [main_column]]], axis=0)
mp = comb.groupby(col)[main_column].agg(['nunique'])['nunique'].to_dict()
train_df[col + '_' + main_column + '_ct'] = train_df[col].map(mp).astype('float32')
test_df[col + '_' + main_column + '_ct'] = test_df[col].map(mp).astype('float32')
print(col + '_' + main_column + '_ct, ', end='')
- 缺失值处理:根据之前可视化了这些特征的分布,并分析了它们可能代表什么,删除无用的列
- 对于有用的列的缺少值,使用平均值或众数填充
- 对于 TransactionAmt 列 ,可以进行日志转换以使数据分布更接近正态分布。
模型
三个经典的GBDT模型
- Catboost
- LGBM
- XGB
其中LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的。
使用GOSS算法和EFB算法的梯度提升树(GBDT)称之为LightGBM。
相比于传统的boosting算法,Lightgbm使用了如下两种解决办法:
(1)一是GOSS(Gradient-based One-Side Sampling, 基于梯度的单边采样),不是使用所用的样本点来计算梯度,而是对样本进行采样来计算梯度
(2)二是EFB(Exclusive Feature Bundling, 互斥特征捆绑) ,这里不是使用所有的特征来进行扫描获得最佳的切分点,而是将某些特征进行捆绑在一起来降低特征的维度,是寻找最佳切分点的消耗减少。这样大大的降低的处理样本的时间复杂度。
参考
调参
参数太多了,主要是以下几个:
num_leaves: 叶子节点的个数
max_depth:最大深度,控制分裂的深度
learning_rate: 学习率
objective: 损失函数(mse, huber loss, fair loss等)
min_data_in_leaf: 叶子节点必须包含的最少样本数
feature_fraction: 训练时使用feature的比例
bagging_fraction: 训练时使用样本的比例
模型融合
模型融合是使用,Averaging方式就是加权平均,比如看单个模型表现好坏,score等等