大数据学习之Hadoop集群搭建(二)
目录
一、Hadoop集群规划
二、配置样板节点
1、虚拟机硬件信息
2、本地登录配置
(1)root用户登录
(2)关闭防火墙
(3)修改主机名和IP地址
(4)配置hosts
(5)创建用户设置密码
(6)添加sudo权限
(7)切换用户验证sudo命令
(8)创建软件安装目录
3、远程登录配置
(1)Xshell远程登录
(3)安装jdk和hadoop
(4)修改hadoop配置文件
(5)配置主机免密登录
三、克隆样板节点搭建集群
1、克隆样板节点修改配置
(1)克隆样板节点
(2)开启三台克隆虚拟机
(3)atguigu用户本地登录克隆机
(4)修改克隆机主机名、固定ip、虚拟网卡
2、Xshell远程连接启动集群
(1)Xshell同时连接三台虚拟机
(2)ssh登录三台主机实现免密登录
(3)同时切换到hadoop安装目录
(4)hadoop102启动hdfs测试
(5)hadoop103启动yarn测试
(6)hadoop104启动jobhistory测试
3、启动集群所有节点并通过浏览器查看
(1)hadoop102启动hdfs
(2)hadoop103启动yarn
(3)hadoop104启动jobhistory
(4)jps查看进程状态
(5)浏览器查看节点状态
四、集群功能测试
1、创建测试文件
2、上传文件到集群hdfs系统根目录/
3、web端查看是否上传成功
4、调用mapreduce函数wordcount
五、启动停止主机单节点
(1)启动/停止当前主机HDFS节点
(2)启动/停止当前主机YARN节点
一、Hadoop集群规划
集群使用192.168.1.102、192.168.1.103、192.168.1.104三台虚拟机,主机名对应为
hadoop102、hadoop103、hadoop104
集群配置方案:(9个节点搭配部署在3台服务器,生产环境中每个节点单独一台服务器)
|
|
hadoop102 |
hadoop103 |
hadoop104 |
| HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
ps:104主机还作为历史服务器
二、配置样板节点
1、虚拟机硬件信息
内存2G、硬盘20G
4处理器*2核=8线程
分区配置:
/ 15260M(15G)
/boot 200M
/swap 剩余所有
2、本地登录配置
(1)root用户登录
(2)关闭防火墙
service iptables stop
chkconfig iptables off ![]()
查看防火墙状态
service iptables status
chkconfig iptables --list
(3)修改主机名和IP地址
vim /etc/sysconfig/network
vim /etc/sysconfig/network-scripts/ifcfg-eth0参考如下配置:
DEVICE=eth0
TYPE=Ethernet
#开机联网
ONBOOT=yes
#静态ip
BOOTPROTO=static
#固定IP地址
IPADDR=192.168.1.100
PREFIX=24
#网关地址
GATEWAY=192.168.1.2
#域名解析器地址
DNS1=192.168.1.2
NAME=eth0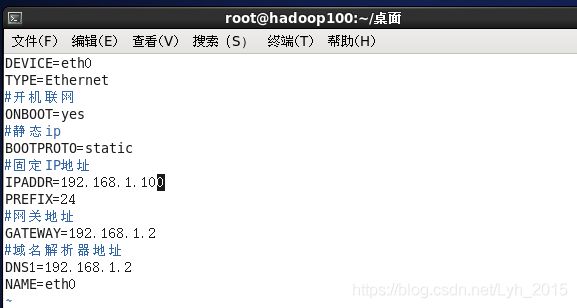
(4)配置hosts
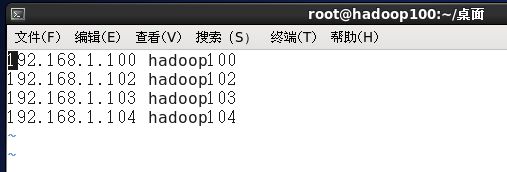
vim /etc/hosts
参考如下配置:
(前项是服务器IP地址,后项是服务器主机名)
192.168.1.100 hadoop100
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104清除默认后配置如下
(5)创建用户设置密码
useradd atguigupasswd atguigu
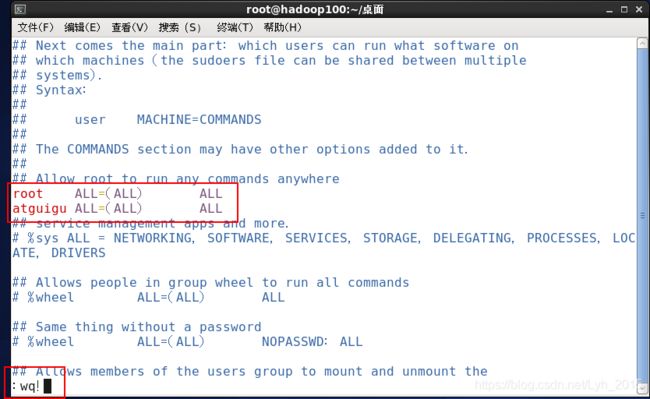
(6)添加sudo权限
vim /etc/sudoers复制第91行至92行,将root修改为atguigu
快捷操作命令:
91+G:直接跳到91行,先输入数字91,然后同时按下shift键和g键
yy:复制当前行
p:粘贴
i:进入编辑模式
wq!:退出并强制保存
(7)切换用户验证sudo命令
su atguigu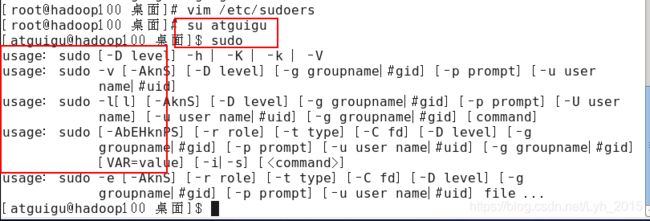
(8)创建软件安装目录
mkdir /opt/module /opt/softwarechown atguigu:atguigu /opt/module /opt/software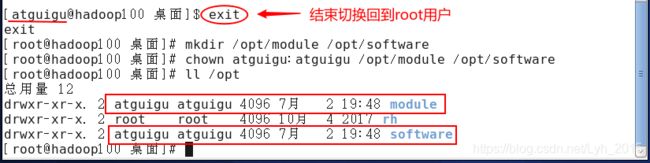
3、远程登录配置
(1)Xshell远程登录
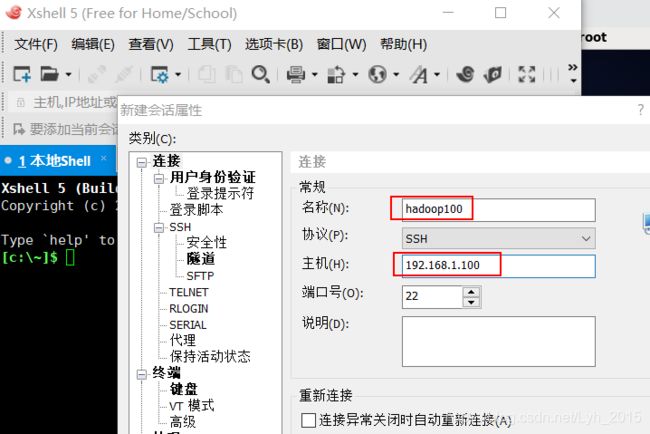
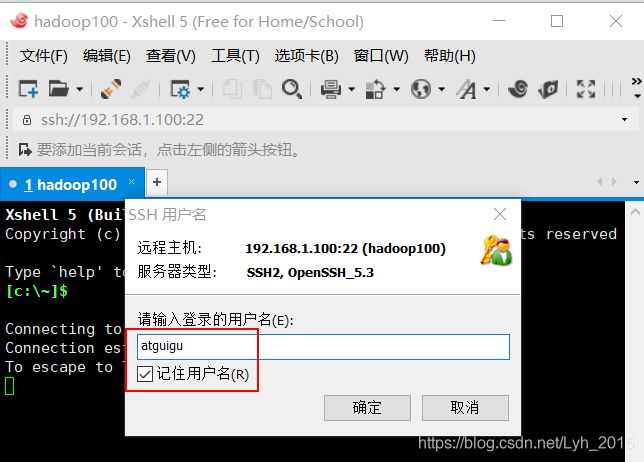
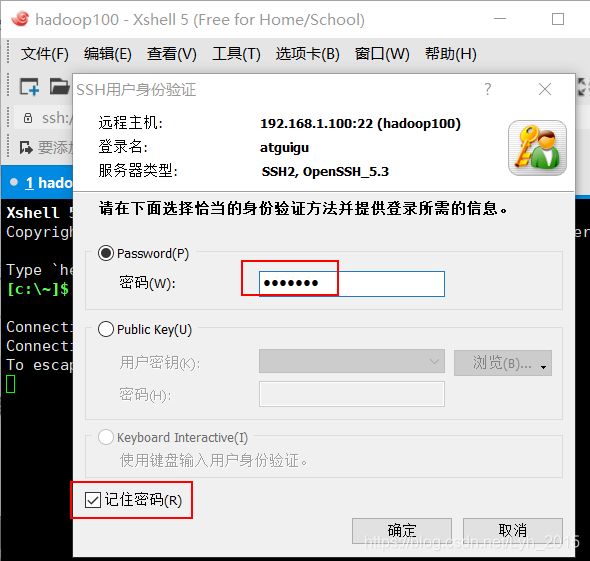
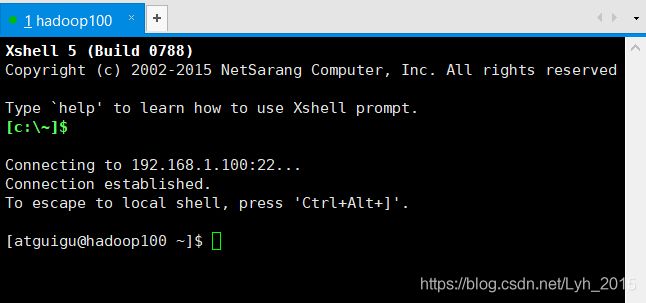
(3)安装jdk和hadoop
*查看系统是否已安装jdk,如果系统已安装jdk则需要卸载
rpm -qa |grep java
xftp上传压缩包到/opt/software目录
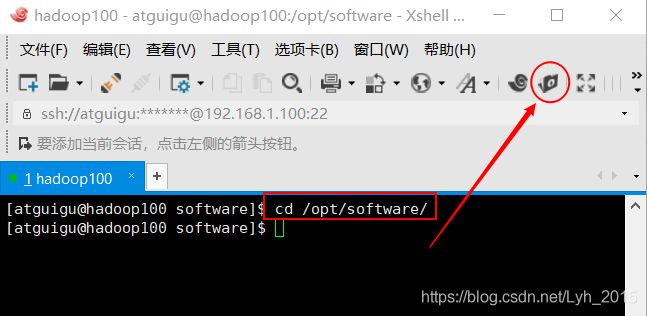

解压缩到/opt/module目录
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/moduletar -zxvf hadoop-2.7.2.tar.gz -C /opt/module修改系统配置文件
sudo vim /etc/profile在最后追加如下配置
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置文件立即生效
source /etc/profile验证配置是否已生效:java -version、hadoop version

(4)修改hadoop配置文件
切换到hadoop安装目录
cd /opt/module/hadoop-2.7.2修改hadoop-env.sh、mapred-env.sh 、yarn-env.sh 三个文件
vim etc/hadoop/hadoop-env.shvim etc/hadoop/mapred-env.shvim etc/hadoop/yarn-env.sh统一将JAVA_HOME变量值修改为jdk安装路径
export JAVA_HOME=/opt/module/jdk1.8.0_144修改core-site.xml
vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://hadoop102:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
修改hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop104:50090
修改yarn-site.xml
vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
mapred-site.xml.template重命名为mapred-site.xml再修改
mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop104:10020
mapreduce.jobhistory.webapp.address
hadoop104:19888
修改节点配置文件slaves
vim etc/hadoop/slaves清除原有信息改为如下配置:
hadoop102
hadoop103
hadoop104(5)配置主机免密登录
生产密钥对,出现提示直接回车三次即可
ssh-keygen -t rsa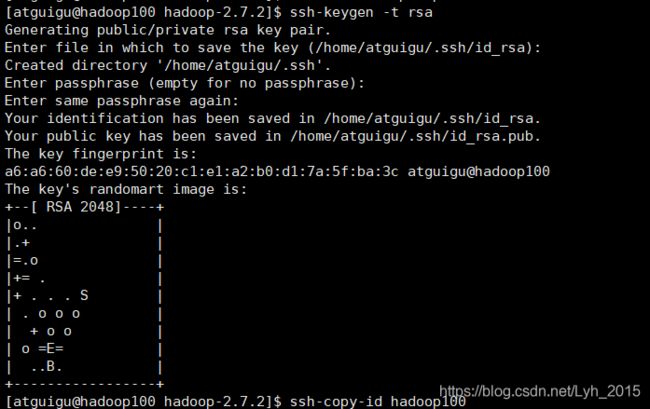
发送公钥到本机(输入yes后输入密码)
ssh-copy-id hadoop100
尝试免密登录

三、克隆样板节点搭建集群
1、克隆样板节点修改配置
(1)克隆样板节点
关闭样板节点虚拟机
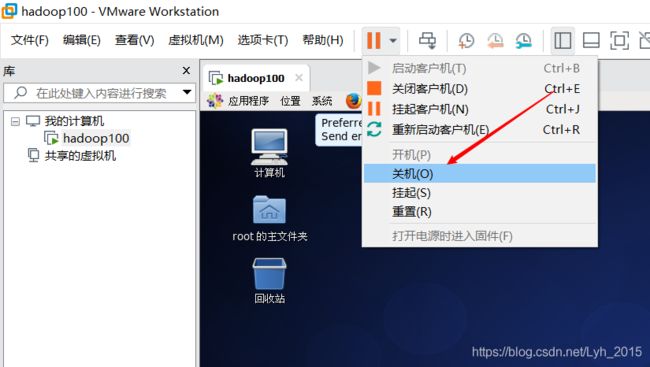
选中虚拟机右键-管理-克隆
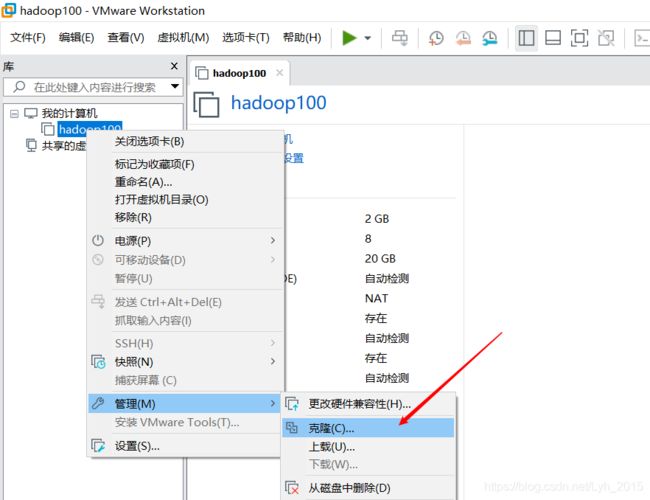

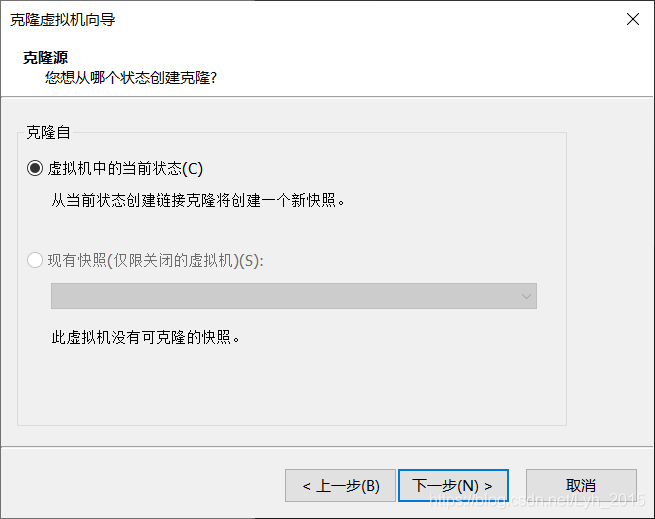

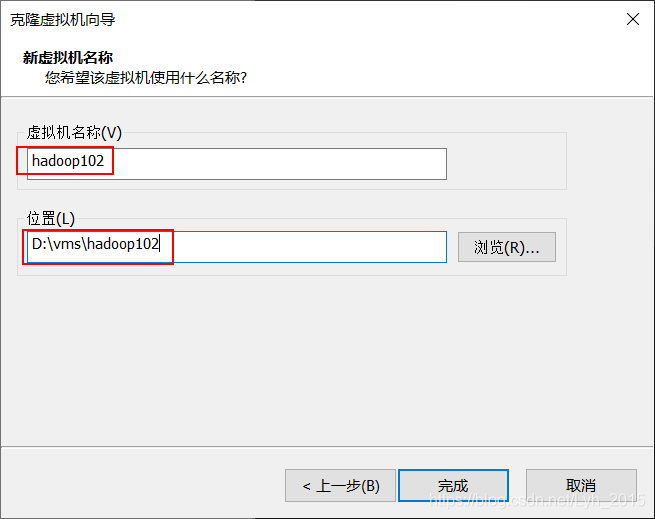


同样的操作步骤,克隆hadoop103、hadoop104
(2)开启三台克隆虚拟机

(3)atguigu用户本地登录克隆机

(4)修改克隆机主机名、固定ip、虚拟网卡
虚拟机名、主机名、ip地址三者最好对应,
hadoop102对应192.168.1.102
hadoop103对应192.168.1.103
hadoop104对应192.168.1.104
sudo vim /etc/sysconfig/network
sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 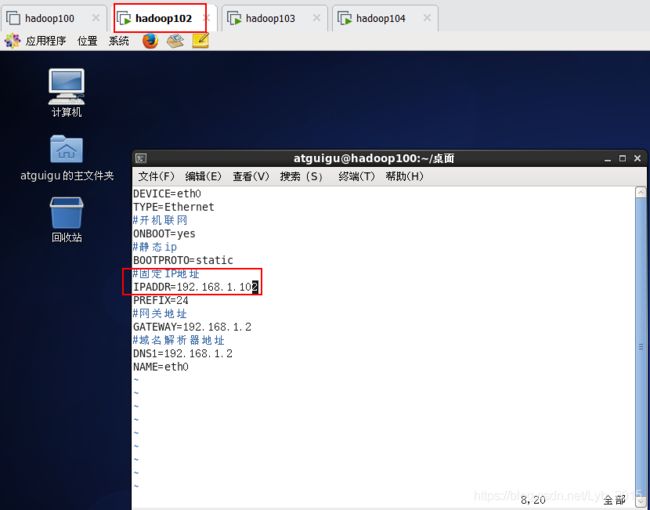
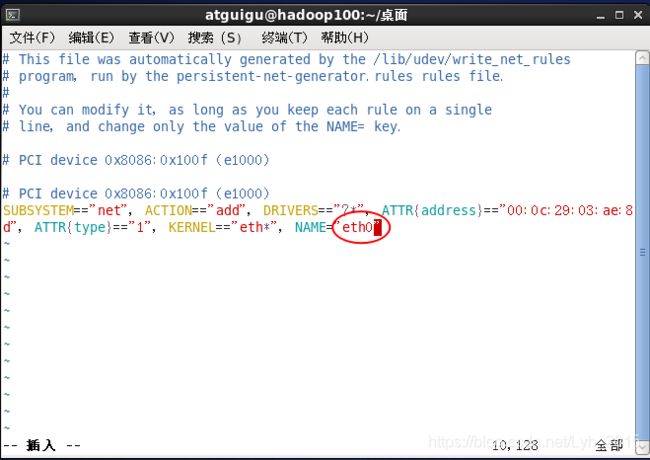
sudo vim /etc/udev/rules.d/70-persistent-net.rules删除第一行,将第二行的ech1改为ech0
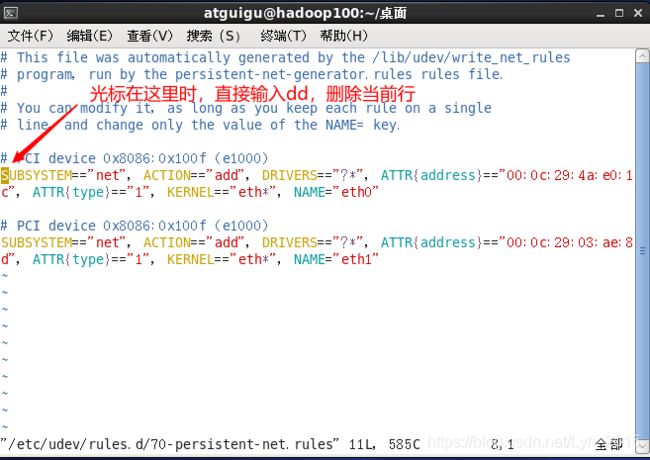
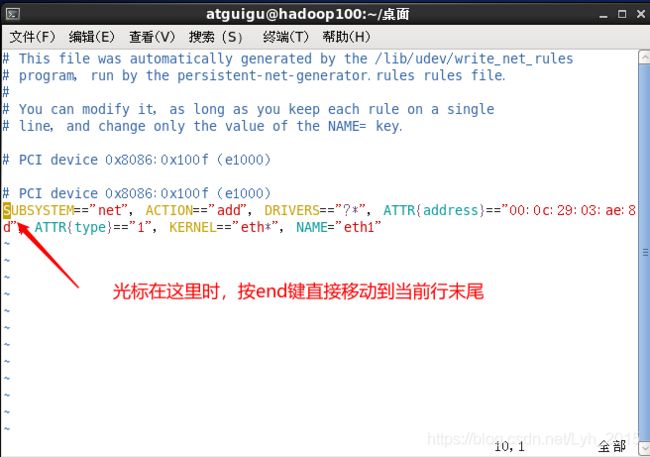
按i进入编辑模式将数字1改为0,esc退出编辑模式,:wq保存并退出
重启虚拟机
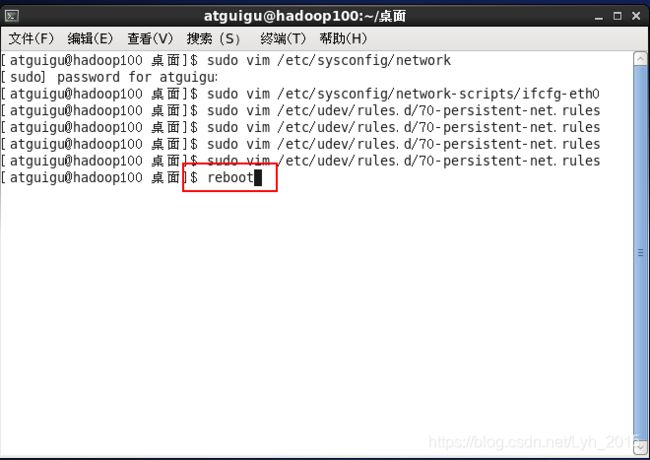
PS:相同步骤修改克隆机hadoop103和hadoop104
2、Xshell远程连接启动集群
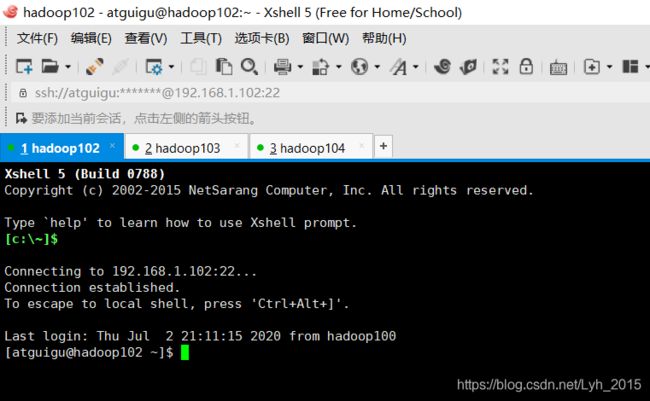
(1)Xshell同时连接三台虚拟机
(2)ssh登录三台主机实现免密登录
ssh登录三台主机
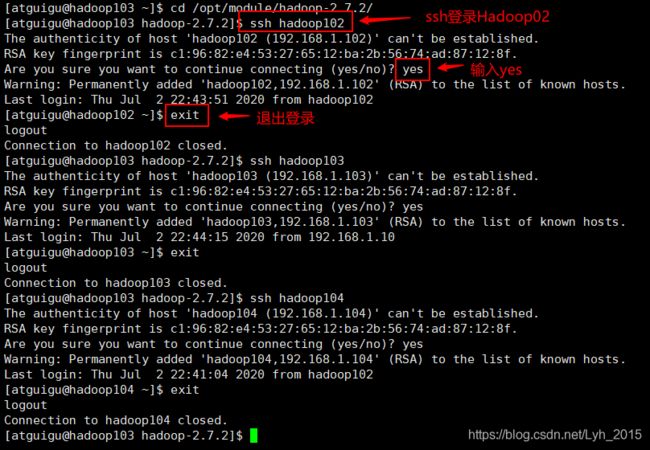
每台虚拟机上都执行一遍

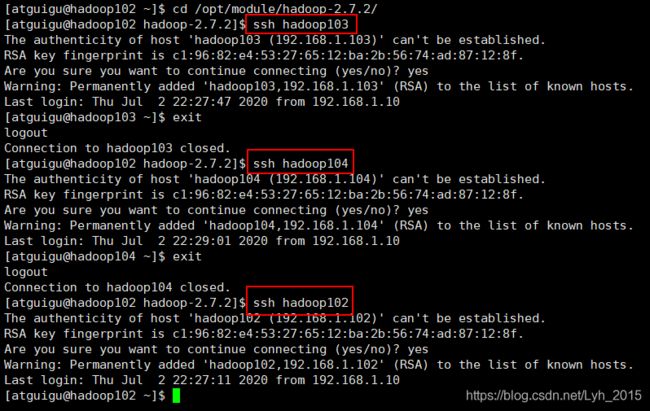
(3)同时切换到hadoop安装目录
cd /opt/module/hadoop-2.7.2/(4)hadoop102启动hdfs测试
namenode节点部署在hadoop102
***第一次运行需要格式化namenode,后续不再需要
hdfs namenode -format
启动hdfs集群
start-dfs.shnamenode节点和三个datanode节点都启动成功
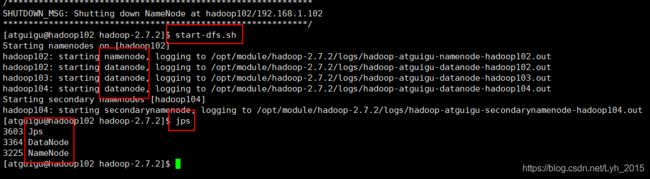
关闭hdfs集群
stop-dfs.sh 
(5)hadoop103启动yarn测试
ResourceManager节点部署在hadoop103
启动yarn集群
start-yarn.sh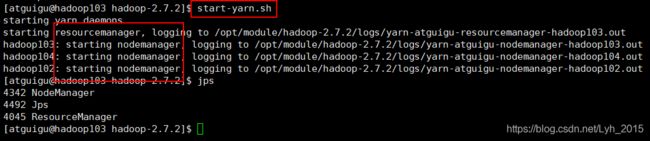
关闭yarn集群
stop-yarn.sh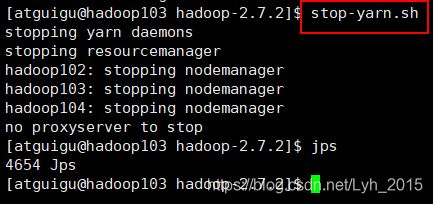
(6)hadoop104启动jobhistory测试
启动历史服务器jobhistory
sbin/mr-jobhistory-daemon.sh start historyserver停止历史服务器jobhistory
sbin/mr-jobhistory-daemon.sh stop historyserver 
3、启动集群所有节点并通过浏览器查看
(1)hadoop102启动hdfs
start-dfs.sh(2)hadoop103启动yarn
start-yarn.sh(3)hadoop104启动jobhistory
sbin/mr-jobhistory-daemon.sh start historyserver(4)jps查看进程状态
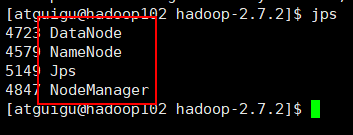
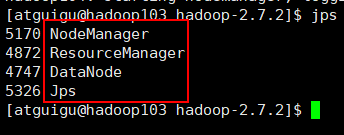
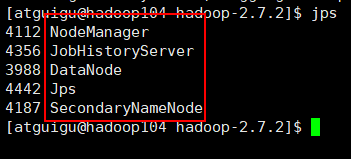
(5)浏览器查看节点状态
查看HDFS数据节点
http://192.168.1.102:50070/dfshealth.html#tab-datanode
查看整个集群节点
http://192.168.1.103:8088/cluster/nodes
查看SecondaryNameNode节点状态
http://192.168.1.104:50090/status.html
ps:若想使用域名访问相关节点,可以配置本地hosts
编辑windows本地hosts文件添加域名对应ip映射即可,文件路径——C:\Windows\System32\drivers\etc

配置后本地可使用域名访问
查看HDFS数据节点
http://hadoop102:50070/dfshealth.html#tab-datanode
查看整个集群节点
http://hadoop103:8088/cluster/nodes
查看SecondaryNameNode节点
http://hadoop104:50090/status.html
四、集群功能测试
1、创建测试文件
cd /opt/module/hadoop-2.7.2
mkdir wcinput
cd wcinput/
vim wc.input测试文件wc.input输入以下内容,:wq保存并推出
hadoop yarn
hadoop mapreduce
atguigu
atguigu2、上传文件到集群hdfs系统根目录/
cd /opt/module/hadoop-2.7.2
hadoop fs -put wcinput /
3、浏览器查看是否上传成功
http://hadoop102:50070/explorer.html#/


4、执行测试程序
(1)调用mapreduce的wordcount函数
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcoutput显示任务执行成功
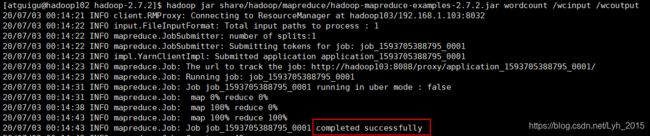
(2)查看执行结果
http://hadoop102:50070/explorer.html#/


下载到本机查看结果
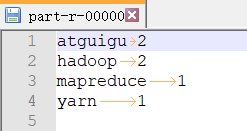
(3)浏览器访问Yarn节点查看任务执行情况
http://hadoop103:8088/cluster

点击History可查看详情

五、启动停止单节点
(1)启动/停止当前主机HDFS节点
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止当前主机YARN节点
yarn-daemon.sh start / stop resourcemanager / nodemanager