三级数据库(7)-数据库及数据库对象
1.每次启动SQL Server时都会重新创建tempdb数据库,因此若其损坏,没有必要恢复.
2.建有唯一聚集索引的视图称为索引视图.create unique clustered index 名字 on 视图名
3.一个数据库只允许有一个主要数据文件,多个次要文件.推荐扩展名分别为.mdf,.ndf.名字不必一定是这个.日志文件不包括在文件组中.定义数据文件时如果没有指定文件组则其属于默认文件组.数据库创建后数据文件和日志文件的空间都不能被手工缩小.
4.设要为某整数类型的列建立4个分区.分别是<=100,101-200,201-300,>300
Left for values(100,200,300).关键字left指定边界值间隔处于左侧分区.所以做题之前,先画一个ß----向左
5.主(PRIMARY)文件组是系统定义好的一个文件组,且只有一个.它包含主要数据文件和任何没有明确分配给其他文件组的其他数据文件。因此也有可能含有次要数据文件.主要文件必须存放在此文件组.
6.创建分区表的步骤:创建分区函数,创建分区方案,使用分区方案创建表.
创建分区方案时指定的文件组数不得少于分区函数生成的分区数,所以不用一定相等.
不同的分区可以映射到相同的数据库文件上.
分区表是从物理上将一个大表划分为几个小表.
7.索引结构中的记录是由索引列列值和它相对应的指针构成的.
8.聚集索引是指数据文件中数据记录的排列顺序与索引文件中索引项的排列顺序相一致,或者说索引文件按照其查找码指定的顺序与数据文件中数据记录的排列顺序相一致。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以对应的聚集索引只能有一个。除了聚集索引以外的索引都是非聚集索引,如果某索引不是聚集索引,则数据文件中数据记录的排列顺序与索引文件中索引项的排列顺序不一致。与非聚集索引相同,聚集索引的作用是加快数据的查询速度。
9.分离数据库是指将数据库从SQLServer数据库列表中删除,但不删除数据库的数据文件和日志文件。分离数据库时不仅要分离数据文件,也会分离日志文件.分离数据库会保持数据库的数据文件和日志文件的完整和一致。分离成功后,可以把该数据库文件(.MDF)和对应的日志文件(.LDF)拷贝到其它磁盘中作为备份保存。分离数据库需要对数据库具有独占访问权限。
10.数据库创建后可以手工缩小数据文件和日志文件的空间.
11.架构可以是显式的,也可以由DBMS提供默认名..所以用户不必在使用表时显式指明所属架构.
12.补全SQL语句
删除DB1数据库中的U1用户, DROP User U1
在Student表中的sname列上建一个非聚集索引. Create nonclustered index idx1 on Student(sname).
修改数据文件数据大小:alter database db modify file(name=db_data,size=200MB).加粗处没有data
13.建立索引:

14.SQLSEVER的四个系统数据库(1)Master数据库是SQL Server系统最重要的数据库,它记录了SQL Server系统的所有系统信息。因此,如果 master 数据库不可用,则 SQL Server 无法启动。(2)model 数据库用作在 SQL Server 实例上创建的所有数据库的模板。因为每次启动 SQL Server 时都会创建 tempdb,所以 model 数据库必须始终存在于 SQL Server 系统中。(3)Msdb数据库是代理服务数据库,为其报警、任务调度(与作业信息相关)和记录操作员的操作提供存储空间。(4)Tempdb是一个临时数据库,由整个系统的所有数据库使用,不管用户使用哪个数据库,他们所建立的所有临时表和存储过程都存储在tempdb上。SQL Server每次启动时,tempdb数据库被重新建立。当用户与SQL Server断开连接时,其临时表和存储过程自动被删除。若其损坏,不需备份恢复,因为SQLSEVER会重新创建tempdb.
15.复合索引
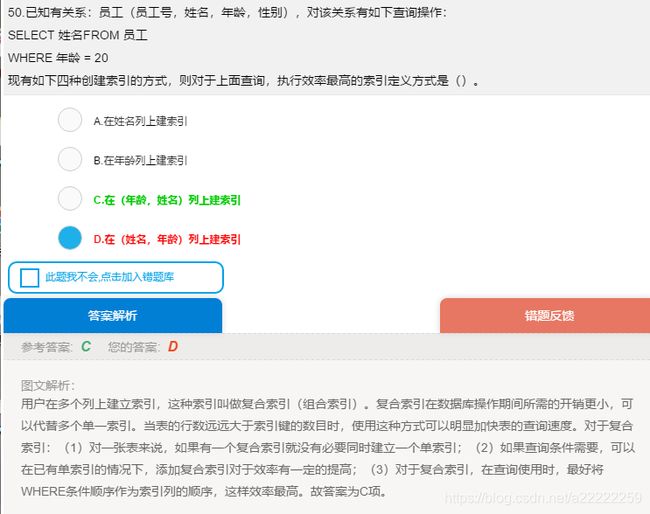
16.聚类算法与分类的区别:它强调同一个组中的对象具有较高的相似度,不同组中的对象之间差别很大.分类事先知道哪些类别可以分,聚类事先不知道,需要据类算法来自动确定