再破纪录!ECCV 2020 旷视研究院15篇成果总览


图:ECCV 2020 词云分析结果
8月23-28日,全球计算机视觉三大顶会之一,两年一度的 ECCV 2020(欧洲计算机视觉国际会议)即将召开。受到疫情影响,今年的 ECCV 将以线上形式举办。据官方统计,本次大会有效投稿5025篇,其中有1361篇被接收,录用率为27%,较上届31.8%有所下降。其中,Oral 论文104篇(占总投稿数2%),Spotlight 论文161篇(本届新增,占总投稿数5%),其余为 Poster。
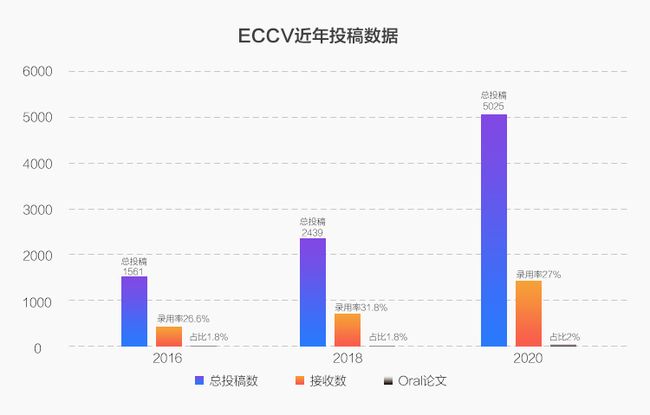
图:ECCV 近三届投稿数据
旷视研究院在本届大会共有 15 篇成果入选,Oral 论文 2 篇与 Spotlight 论文 1 篇,刷新上届入选 10 篇的记录!
旷视研究院本届被接收工作涉及图像检测、图像对齐、姿态估计、激活函数、CNN架构设计、动态网络、NAS、知识蒸馏、点云配准、细粒度图像检索、迁移学习、机器人等多个领域。为了能够及时与学界、业界同仁进行交流与分享,后文对全部工作进行了介绍,并附上目前已经放出的论文地址与开源地址。
这样的战绩不仅反映出旷视研究院在学术与产业前沿技术研究上的实力,也从侧面印证了旷视多年来构建的务实、高效的产学研体系所具备的价值:做源自产业的学术研究、解制约当前发展的关键技术、理论瓶颈。
另外,为了让读者对本届大会以及近年来CV领域关注的热点研究方向有一个直观把握,我们也对近三年来世界三大CV顶会入选论文的标题进行了热点词分析,通过对比ECCV 2020和CVPR 2020、ICCV 2019、CVPR 2019、ECCV 2018的结果,大家可以一窥领域内关注的重点在近年来发生的变化,以及大家持续深耕的热点问题。
需要说明的是,由于CVPR会议交稿截止日期是在大会举办前1年(即CVPR 2020的文章是2019年提交的),因此在对比中我们将ICCV 2019与CVPR 2020进行对比,将CVPR 2019与ECCV 2018进行对比,进一步再用ECCV 2020与2019年和2018年的数据进行综合对比。
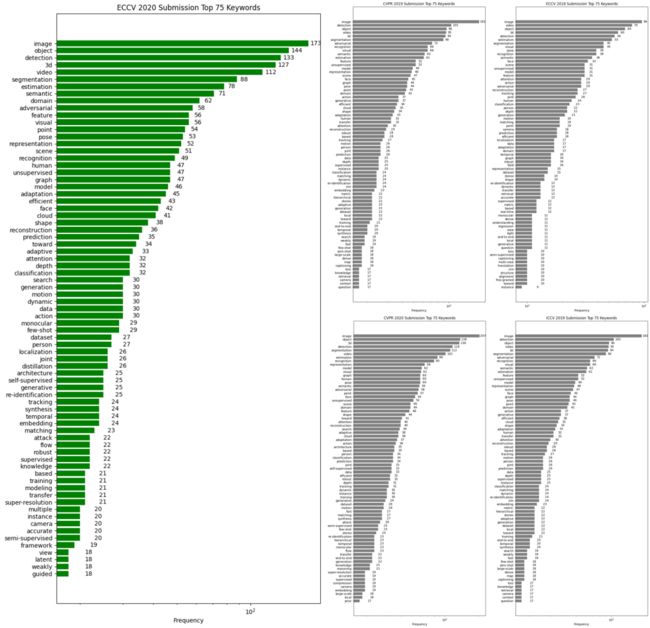
图:近三年世界三大CV顶会(CVPR、ECCV、ICCV)论文热点词对比,获取清晰图片请在公众号后台回复关键词“ECCV”
可以发现,近年来持续热门的领域包括3D视觉、分类/检测/分割、人脸识别/人体姿态/动作识别、视频理解、图像超分辨率等等。采用的热门方法有模型自动搜索、注意力机制、无/半/自监督表示学习、对抗学习、知识蒸馏等多种方法。
且自监督学习、动态网络、神经网络动力学等多个领域因其巨大的学术和产业价值,在近来获得了越来越多地突破与关注,CV研究在深度学习基础研究的加持之下,茁壮向前发展。
后续我们也会启动“10分钟带你看ECCV”系列论文视频解读,邀请旷视研究院本次入选论文作者分别就其工作进行视频分享,欢迎感兴趣的同学持续关注旷视研究院后续内容。
值得一提的是,本次旷视研究院入选ECCV的部分工作使用旷视天元(MegEngine)深度学习框架进行开源。天元(MegEngine)是旷视自研,并在内部经过6年全员使用、打磨的工业级深度学习框架,其诞生之初的设计理念便直指从科研成果到大规模产品应用的高效转化。
作为一款训练推理一体化的框架,天元(MegEngine)能够帮助企业与开发者的产品从实验室原型到工业部署的时间成本大幅缩减,真正实现小时级的转化能力。
欢迎访问
MegEngine WebSite:
https://megengine.org.cnMegEngine GitHub(欢迎Star):
https://github.com/MegEngine
或加入「天元开发者交流QQ群」,一起看直播学理论、做作业动手实践、直接与框架设计师交流互动。

同时,群内还会不定期给大家发放各种福利:学习礼包、算力、周边等。
「点击文末阅读原文查看天元MegEngine相关技术进展」
旷视研究院 ECCV 2020 论文总览
01
Oral 论文:BorderDet: Border Feature for Dense Object Detection
论文链接:https://arxiv.org/pdf/2007.11056v1.pdf
论文代码:https://github.com/Megvii-BaseDetection/BorderDet
关键词:物体检测、边界特征
在物体检测领域,检测器一般会通过滑窗的方式来预测图像网格上的物体,并且还会使用网格中特征点的特征图来生成边界框的预测结果。其中的问题在于,虽然这些点的特征使用起来十分方便,但它们往往可能缺乏有用的边界信息,从而不利于进行精准地定位。因此,本文提出一个简单、高效的操作“BorderAlign”来提取物体边界极限点的特征。
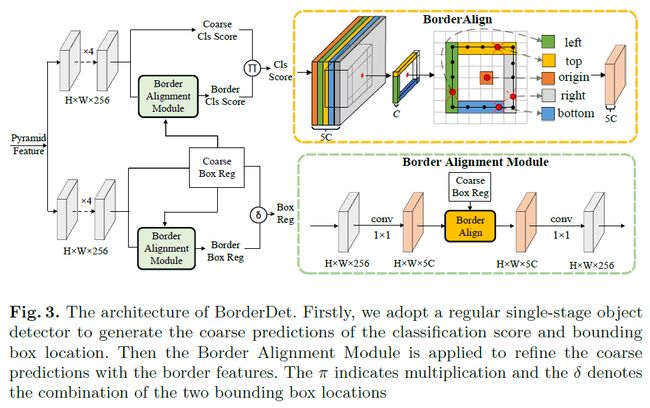
基于BorderAlign,旷视研究院还设计了一个全新的检测框架“BorderDet”。它可以很好地利用边界信息,实现更强大的分类与更精准的定位效果。在ResNet-50 backbone下,模型只增加很少的时间开销,就可以在单阶段检测器FCOS上实现 2.8 AP的性能提升(38.6 v.s. 41.4);在ResNeXt-101-DCN backbone下,本文提出的BorderDet获得50.3 AP,显著超越现有最佳方法。
02
Oral 论文:Content-Aware Unsupervised Deep Homography Estimation
论文链接:https://arxiv.org/pdf/1909.05983.pdf
论文代码:https://github.com/JirongZhang/DeepHomography
关键词:Homography变换、深度Homography、图像对齐、RANSAC
Homography估计是目前众多图像对齐应用中都会使用到的基本对齐方法。一般而言,它通过提取并匹配稀疏特征点来实现,不过这样的机制在面对暗光和缺少纹理的场景时效果不理想。另外,考虑到当前的深度Homography方法在监督学习下会用到合成数据,在无监督学习下会使用视差较小的航拍图并且全图计算损失,这两种方案都忽略了真实世界应用当中来自深度视差与移动物体的重要影响。

因此,在本文中旷视研究院提出一种新型架构的无监督深度homography方法以克服上述问题。具体而言,受到传统方法中RANSAC过程的启发,研究人员提出通过学习一个mask来专门选择可靠的区域以进行homography估计。在损失的计算上,文章根据深度特征而不是之前通过直接比较图像内容的方式来进行。为了实现无监督学习,研究人员还针对网络设计了一个全新的triplet损失。在不同场景数据的实验结果显示,本文方法较最先进的深度方法与基于特征的方法都更为优越。
03
Spotlight 论文:Learning Delicate Local Representations for Multi-Person Pose Estimation
论文链接:https://arxiv.org/abs/2003.04030
论文代码:https://github.com/caiyuanhao1998/RSN/
关键词:人体姿态估计、COCO、MPII、特征聚合、注意力机制
在利用特征融合进行人体关键点检测的现有工作中,人们多以inter-level的特征融合为基本策略,而没有考虑intra-level特征融合能带来的丰富空间信息。为此在本文中,旷视研究院提出一个全新方法,残差阶梯网络(Residual Steps Network, RSN)。RSN能聚合同一网络阶段输出的特征(inta-level 特征),以获得精准的局部特征表示,该表示保留了丰富的低层空间信息,能够助力网络实现精确的关键点定位。
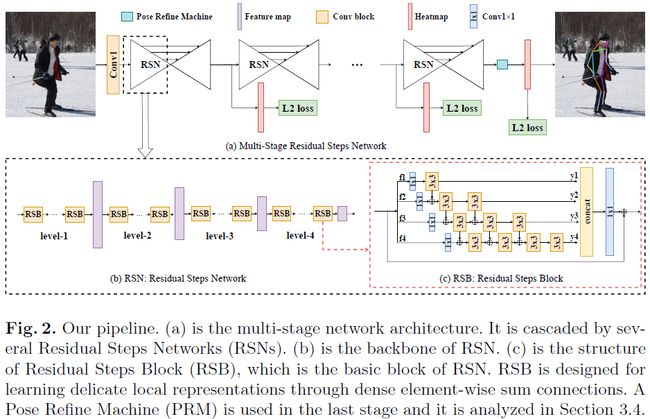
此外,研究人员还提出一个高效的注意力机制——姿态修正机(Pose Refine Machine),它能够在输出特征上平衡局部与全局表示,进一步修正关键点定位效果。本文方法在2019 COCO关键点检测任务上夺冠,在无额外数据与预训练模型的情况下,在COCO与MPII基准数据集上均取得了最佳效果。
04
论文题目:Funnel Activation for Visual Recognition
论文链接:https://arxiv.org/abs/2007.11824
MegEngine开源:https://github.com/megvii-model/FunnelAct
关键词:funnel 激活函数、视觉识别、CNN
本文在激活函数领域进行了创新,提出一种在视觉任务上大幅超越ReLU的新型激活函数Funnel actication(FReLU),简单又高效。
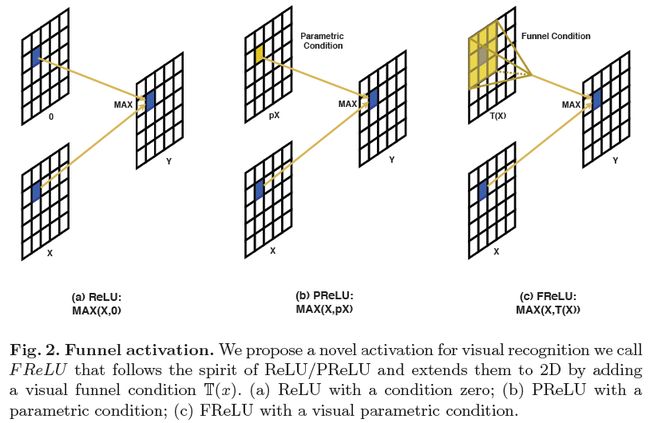
具体而言,旷视研究院通过增加可忽略的空间条件开销将ReLU和PReLU扩展为2D激活函数。ReLU和PReLU分别表示为y = max(x,0)和y = max(x,px)的形式,而FReLU的形式为y = max(x,T(x)),其中T(·)是二维空间条件(2D spatial condition)。
此外,空间条件以简单的方式实现了像素级建模能力,并通过常规卷积捕获了复杂的视觉layouts。最后,对ImageNet数据集、COCO数据集检测任务和语义分割任务进行了实验,展示了FReLU激活函数在视觉识别任务中的巨大改进和鲁棒性。
05
论文题目:WeightNet: Revisiting the Design Space of Weight Networks
论文链接:https://arxiv.org/abs/2007.11823
MegEngine开源:https://github.com/megvii-model/WeightNet
关键词:CNN架构设计、权重生成网络、动态滤波器
本文提出一个灵活高效的权重生成网络框架,称为WeightNet。将SENet与CondConv这两种独立且非常有效的方法纳入到同一框架中,是一种通用方法。WeightNet通过在注意力激活层上添加一层分组全连接层(group fully-connected layer)从而实现了对这两种方案的统一。
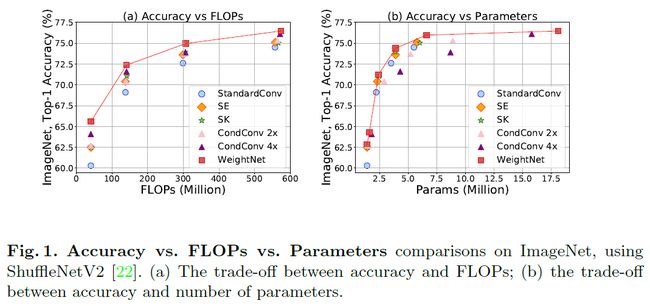
WeightNet可以直接输出卷积权重,同时在kernel空间(而非特征空间)上训练起来既简单内存消耗又少。凭借其灵活性,该方法在ImageNet和COCO的检测任务上均超越了现有方法,取得了更好的准确率-FLOPs和准确率-参数平衡。
06
论文题目:Angle-based Search Space Shrinking for Neural Architecture Search
论文链接:https://arxiv.org/abs/2004.13431
论文代码:https://github.com/megvii-model/AngleNAS
关键词:NAS、angle、搜索空间裁剪
在本文中,旷视研究院提出了一个简单且通用的搜索空间裁剪方法,angle-based 搜索空间裁剪方法(ABS)。ABS通过删除潜力差的结构来逐步裁剪原始搜索空间。现有NAS方法使用裁剪后的搜索空间能够降低搜索难度和资源消耗,同时找到更优的结构。
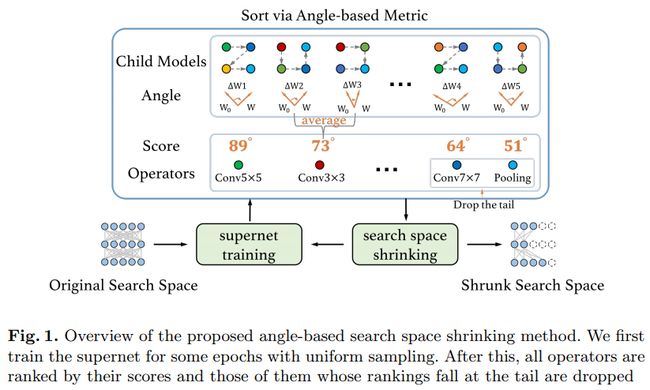
具体而言,研究人员提出了一种基于角度的新性能衡量指标来指导搜索空间裁剪。一系列详尽的实验显示,在共享权重的超网络中对子模型进行性能排序时,该指标比使用accuracy-based 和magnitude-based的指标更加稳定且一致性更高。此外,angle-based指标在训练超网络时收敛也更快,能够帮助研究人员高效地得到缩小的搜索空间。ABS可以十分方便地应用于大多数NAS方法,且提升效果显著。
07
论文题目:LabelEnc: A New Intermediate Supervision Method for Object Detection
论文链接:https://arxiv.org/abs/2007.03282
论文代码:https://github.com/megvii-model/LabelEnc
关键词:物体检测、辅助监督、自编码器
旷视研究院在本文中提出一种新型的中间监督方法,LableEnc,以提升物体检测系统的训练效果。该方案的关键创新点是引入了一个全新的标签编码函数,将ground-truth标签映射到潜在嵌入空间上,作为辅助backbone进行训练的中间监督信息。
本文方法主要涉及2阶段训练步骤。首先,通过一个在标签空间上定义的自编码器来优化标签编码函数,以达到获得关于物体检测器的理想中间表示的目的。然后,利用习得标签编码函数,研究人员引入了一个新设计的辅助损失,连接在检测backbone上,可以提升后面检测器的性能。
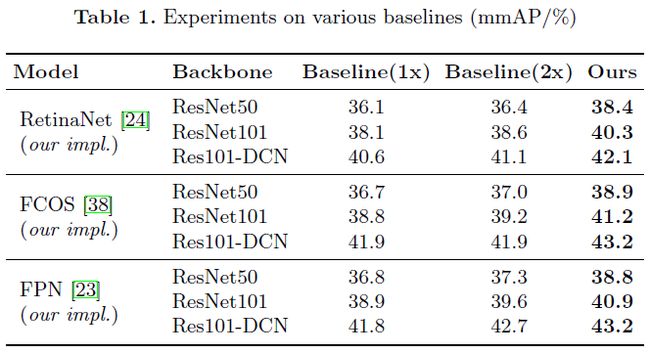
在COCO的实验结果显示,本文方法具有很强的通用性,它在多种检测系统上都实现了约2%的性能提升,无论该系统是单阶段还是双阶段架构。另外,本文的辅助结构仅仅在训练过程中存在,这也即是说,它完全不会影响推理时候的开销。
08
论文题目:Single Path One-Shot Neural Architecture Search with Uniform Sampling
论文链接:https://arxiv.org/abs/1904.00420
论文代码:https://github.com/megvii-model/ShuffleNet-Series
关键词:NAS、一步法、超网络
一步法(One-Shot)是一个强大的神经网络模型搜索(Neural Architecture Search/NAS)框架,但是它的训练相对复杂,并且很难在大型数据集(比如 ImageNet)上取得较有竞争力的结果。在本文中,旷视研究院提出一个单路径 One-Shot 模型,以解决训练过程中面对的主要挑战,其核心思想是构建一个简化的超网络——单路径超网络(Single Path Supernet),这个网络按照均匀的路径采样方法进行训练。
所有子结构(及其权重)获得充分而平等的训练。基于这个已训练的超网络,可以通过进化算法快速地搜索最优子结构,其中无需对任何子结构进行微调。
对比实验证明了这一方法的灵活性和有效性,不仅易于训练和快速搜索,并且可以轻松支持不同的复杂搜索空间(比如构造单元,通道数,混合精度量化)和搜索约束(比如 FLOPs,速度),从而便于满足多种需求。这一方法在大型数据集 ImageNet 上取得了当前最优结果。
09
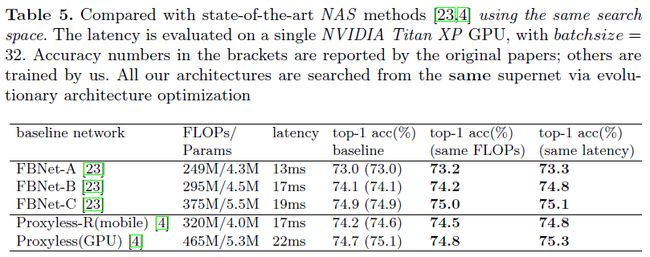
论文题目:Iterative Distance-Aware Similarity Matrix Convolution with Mutual-Supervised Point Elimination for Efficient Point Cloud Registration
论文链接:https://arxiv.org/abs/1910.10328
论文代码:https://github.com/jiahaowork/idam
关键词:点云配准
本文提出了一种基于学习的全局点云匹配算法IDAM。该算法的输入是一组点云对,在提取几何特征与距离特征后送入迭代相似性矩阵卷积模块(similarity matrix convolution),可以获取点云对之间的3d刚体变换矩阵完成匹配。
为了降低计算成本和减少点对误匹配,提出了hard point elimination和hybrid point elimination两种可学习的点云下采样方式来选取重要点,它们通过互监督损失(mutual-supervision loss)进行训练,不需要人为对点进行任何标注。
该算法可以很方便的和传统或者基于学习的点云特征进行结合。在ModelNet40数据集上,本文将IDAM与多种传统点云匹配算法和其他基于学习的点云匹配算法进行了实验对比。结果表明,IDAM在匹配的精度和速度上,都有很大的优势,且对于部分重叠或受噪声影响点云对的匹配鲁棒性和未见过点云模型的泛化能力都很强大。
10
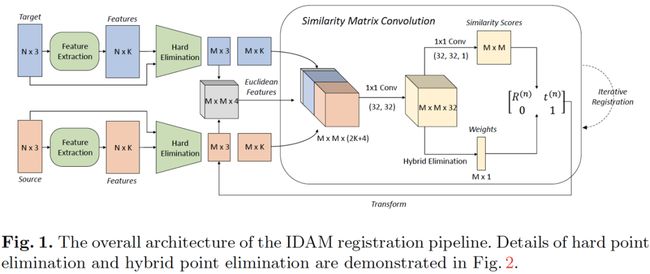
论文题目:Prime-Aware Adaptive Distillation
论文链接:https://arxiv.org/abs/2008.01458
关键词:知识蒸馏、自适应样本加权、不确定性学习
本文在知识蒸馏中探究了“哪一个样本更重要”问题,即蒸馏中的自适应样本加权。以往蒸馏方法对所有样本一视同仁,我们发现蒸馏中对简单样本赋予更大权重会提升学生模型的性能。
进一步,旷视研究院团队结合不确定性学习理论,提出一种能自动感知最优样本并自适应对其加大权重的方法:PAD。PAD不引入额外超参,可轻松与现有蒸馏方法相结合。在分类,度量学习和检测三大任务,总共六个数据集上,PAD进一步提升了知识蒸馏的性能,取得了SOTA的结果。
11
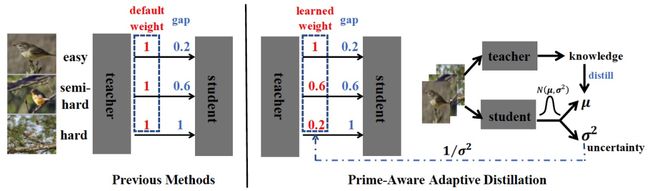
论文题目:Hierarchical context embedding for region-based object detection
论文链接:https://arxiv.org/abs/2008.01338
关键词:物体检测、语境嵌入、Region-based CNN
在这项工作中,旷视南京研究院对目前两阶段检测网络进行了创新,提出利用context信息来提高检测网络的分类能力。
具体而言,旷视南京研究院提出的方法包含了三个模块:
Image-Level Categorical Embedding
Hierarchical Contextual RoI Feature Generation
Early-and-Late Fusion
Image-Level Categorical Embedding模块通过Multi-Label Loss来学习出带有context信息的特征;Hierarchical Contextual RoI Feature Generation利用上述带有context信息的特征和RoI Align操作来产生带有context信息的RoI特征;Early-and-Late Fusion模块把带有context信息的RoI特征和原本检测网络的RoI特征进行融合,最终提高检测器的分类能力。
在FPN、Mask R-CNN和Cascade R-CNN上的实验结果表明,这个方法能有效提高上述主流检测器框架的性能。
12
论文题目:ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
论文链接:https://arxiv.org/abs/2008.01369
关键词:细粒度图像检索; Learning to Hash; 特征对齐; 大规模图像搜索.
本文尝试解决的是细粒度哈希问题,通过为细粒度图片生成二值码,进而加速细粒度图片的检索过程。在文章中,旷视研究院提出了一种名为ExchNet的网络,它首先基于注意力机制捕捉图片的全局和局部特征,接着使用本文提出的一种基于特征交换的方法对局部特征进行对齐,最后融合全局和局部特征生成二值码。
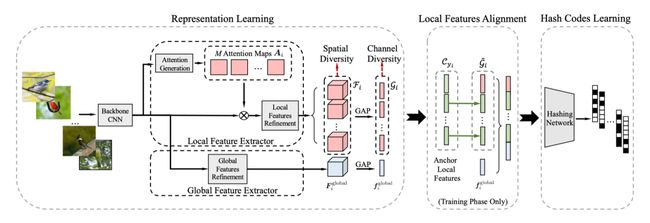
文章最大的创新点在于特征对齐方法,基于如下的假设「对于两张同类鸟的图片,交换对应part的局部特征(如图1的翅膀和图2的翅膀),不影响这两张图片二值码的生成以及他们的相似性」,我们在训练过程中会交换同类样本的局部特征,同时保证同类样本二值码的相似性,进而达到隐式的特征对齐目的。
13
论文题目:Spherical Feature Transform for Deep Metric Learning
论文链接:https://arxiv.org/abs/2008.01469
关键词:数据增强、迁移学习
本文在迁移学习领域进行了创新。提出一种在归一化后的特征空间通过迁移进行数据增强的方法,简单且有效。
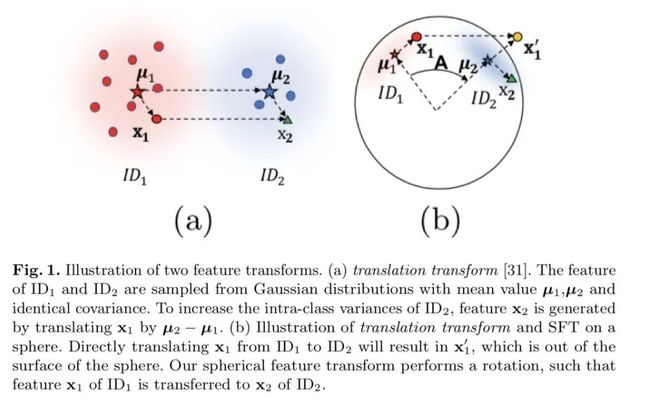
具体而言,传统的在特征空间内做迁移学习的方法假设不同类别的特征服从方差相同的高斯分布。如果定义特征的“偏移量”为特征向量与类别均值向量的差值,传统迁移的方法简单地把“偏移量”叠加到另一个类别的均值上。
本文发现,当特征被归一化后,即被约束到超球面上后,传统的迁移方法无论是基本假设还是迁移的方法都已经不成立。基于directional statistics,本文改进原有的“相同方差”假设为更符合球面分布特性的“相似方差”,进而提出了更general的spherical feature transform用于超球面上的特征迁移学习,并且本文还证明了传统的方法是本文提出方法的一种特例。最后,本文对所提出的迁移方法在人脸识别,度量学习等数据集上进行了大量的实验和分析,展现了所提出方法的有效性。
14
论文题目:Differentiable Feature Aggregation Search for Knowledge Distillation
论文链接:https://arxiv.org/abs/2008.00506
关键词:知识蒸馏、特征聚合、可微分架构搜索
在模型压缩领域,知识蒸馏技术近年来扮演者愈发重要的角色。它能够在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识”蒸馏出来,传递给参数量小、学习能力弱的网络,从而极大提升学生网络的性能,经济又高效。近期主流的工作为了提升学生网络的性能,多采用多教师监督的蒸馏技术,导致需要消耗大量计算资源。
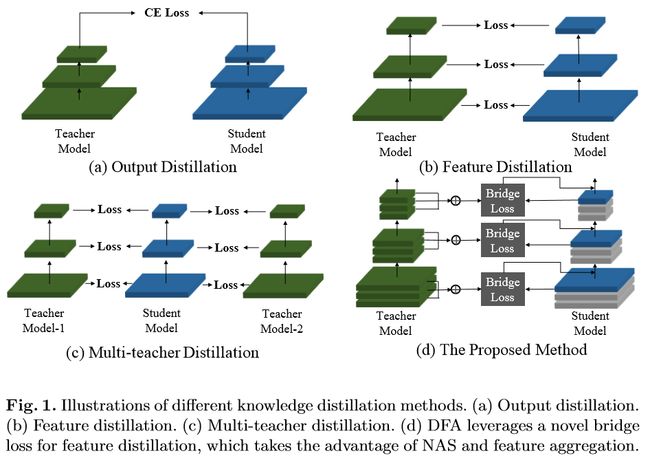
为了平衡效率与性能,旷视研究院在本工作中提出DFA,一个2阶段可微特征聚合搜索方法,来在单教师知识蒸馏框架下模拟多教师蒸馏。在CIFAR-100和CINIC-10上的实验结果显示,DFA显著超越了现有蒸馏方法。
15
论文题目:TP-LSD: Tri-Points Based Line Segment Detector
关键词:直线段检测、一阶段、Tri-Points表示法
对复杂环境进行高效描述是计算机视觉感知的一个重要问题。考虑到人工环境里存在很多平面,因此其相关直线段(line segment)的表示就能够很好地助力系统对环境结构的编码,从而为上游计算机视觉应用提供重要信息,如消失关键点检测、3D结构重建、姿态检测等。
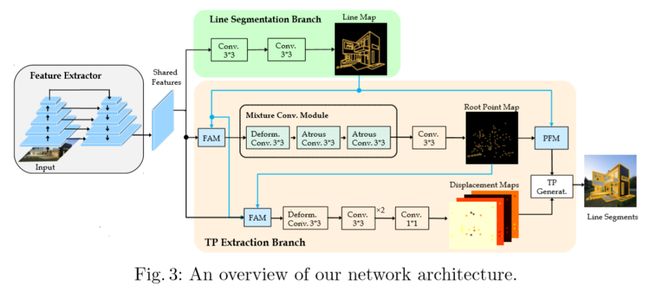
在本工作中,相对于业内大多数使用的二阶段检测器,旷视研究院提出一个更快、更小的一阶段直线段检测器,它基于Tri-Points(TP)表示来编码直线段,能够在准确率与当前领先方法匹敌的情况下,实现对图像的实时检测,在320×320的输入上FPS可达到78。
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
