【论文阅读记录】Focal Loss for Dense Object Detection
前言:
{
之前就见过几次Focal Loss(焦点损失),只是知道它可以用于解决样本不均衡[1],这次就来详细了解一下这种损失和对应的一种模型:RetinaNet。
论文地址:https://arxiv.org/pdf/1708.02002.pdf
}
正文:
{
在论文的第一节,作者提到,目前state-of-art的目标检测模型是双阶段的结构,即首先获取提议区域,之后再进行进一步检查。但是本论文给出了仅通过一个阶段就能达到接近state-of-art的效果。
和上次的论文[1]一样,这里也提到了类的不平衡。R-CNN这种网络结构使用第一阶段的手段来去除大部分的背景区域,之后在第二阶段使用固定的区域比例或在线困难样本挖掘(online hard example mining,OHEM)来进一步平衡区域类。虽然单阶段的结构也能使用先验知识来去除大部分区域尺度,但还是面临类不平衡的问题。
为此,本论文提出了Focal Loss 和其对于的模型RetinaNet。
第二节介绍了目前的相关研究。
之前有对鲁棒损失函数(robust loss function)的研究,其目的在于减少对离群样本的学习。我认为这种方法只是弱化比较困难的样本,是比较保守的(就像高中数学老师说不要把太多功夫用到大难题上,把一般的题目做好就很不错了)。但作者提出的Focal Loss 反而是增加了困难样本的对学习的影响。看到这里我也很好奇,Focal Loss会不会反而降低对简单样本的召回率?
第三节主要讲Focal Loss。
Focal Loss的表达式如式(4)。
![]()
其中y代表当前区域在标签中是前景还是背景,γ是聚焦(focusing)参数,pt的定义见式(2)。
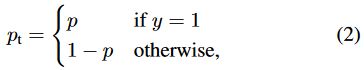
其中p代表模型预测y=1的概率
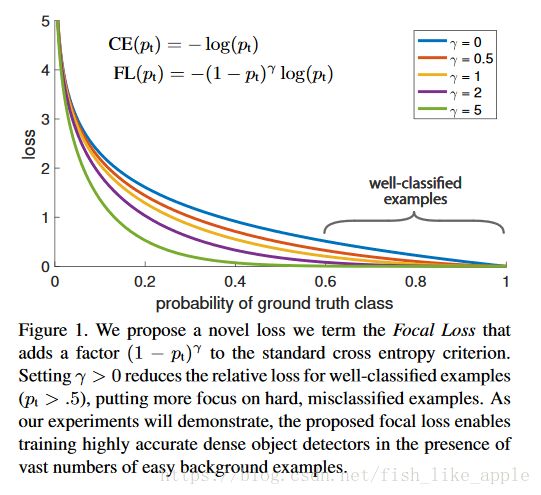
图1是γ不同时Focal Loss的曲线图。
在实践中,作者用到了另一个版本的Focal Loss,见式(5)。
![]()
其中αt为权衡(weighting)因子。
第四节介绍是新结构,RetinaNet。其结构如图3.

图中省略了一些层级。Resnet中的从第3残差阶(residual stage)到第5残差阶与特征金字塔网络(Feature Pyramid Network,FPN)连接。具体地,第3残差阶到第5残差阶与FPN的第3级到第5级连接(FPN没有第1第2级);第5残差阶后又接了一个3*3,步长为2的卷积层,之后此卷积层又接到FPN的第6级;FPN的第6级经过一个3*3,步长为2的卷积层和ReLU之后又接到了FPN的第7级;并且FPN中每一反卷积层的通道数都为256。
(c)和(d)部分为子网络,其输出为各个尺度的检测结果,并且都是类似的全卷积网络(FCN)。FCN中的卷积层全为3*3,前4层加了ReLU;在实验中,A=9代表9种框(原始大小为32*32到512*512(第7级到第3级),尺寸比分别为1:2 , 1:1 , 2:1,大小倍率分别为![]() ,
,![]() )。因此(c)得到所有空间点,预测类别和框种类的预测结果,(b)得到所有空间点,框种类和其偏移属性。各个尺度的(c)之间共享参数,各个尺度的(d)之间也共享参数,(c)和(d)之间不共享参数。
)。因此(c)得到所有空间点,预测类别和框种类的预测结果,(b)得到所有空间点,框种类和其偏移属性。各个尺度的(c)之间共享参数,各个尺度的(d)之间也共享参数,(c)和(d)之间不共享参数。
作者强调,相对于目标检测模型的其他部分,Feature Pyramid Network比较重要。只使用最后的瓶颈层输出会导致较差的结果。
总Focal Loss是所有子网络尺度的Focal Loss的总合。按照上述介绍,子网络尺度有5种,其中图中画出的那一级的Focal Loss有W*H*KA个(如果不过滤的话),即每个点的每种框的每个预测类别的置信度(输出)就是一个Focal Loss。但是,置信度的排名在1000以后或置信度小于0.05的预测不会参加进一步计算,这样就会节省一些时间。通过阈值为0.5的非极大值抑制得到最终的预测结果。
当进行训练时,使用的优化方法是随机梯度下降;一个minibatch中有16张图像;除非另有说明,否则共进行90000次迭代的训练,学习率初始为0.01,60000次迭代后变为0.001,并且80000次迭代后变为0.0001;样本扩增只使用了水平反转;权值衰减设为0.0001;momentum设为0.9;损失为Focal Loss和SmoothL1Loss[4]的总合。
第五节讲述了相关实验。
实验在COCO的样本(从COCO trainval35k中获得的样本,尺度统一为600像素)上进行。
表1给出了各种参数配置的效果。

(还是规模越大效果越好。)
后面很多都是有关上表的解释,最直观地方式还是直接看数据。
表2为与各种方法的横向对比结果。
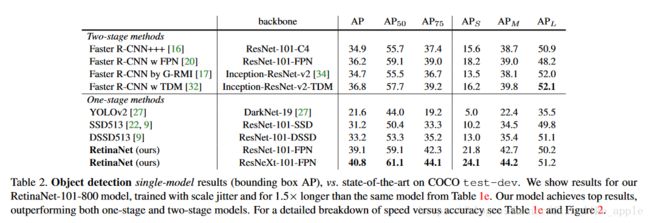 此网络结构确实是目标识别领域中新的突破。
此网络结构确实是目标识别领域中新的突破。
在最后,作者附加了关于损失的一些讨论。给出了Focal Loss的另一种形式(效果没有上述形式的好),并且进行了各种损失的比较,结果见表3。

其中CE为交叉熵,FL*为Focal Loss的新形式。
}
结语:
{
我没搞明白图4,不应该是分量越少作用越大吗?

此网络规模也算是比较大,而且运算也多,不过也提供了目标检测的一个方向,现在我要考虑考虑网络的横向发展了。
这篇论文内容比较多,而且图比较少,我跳过了不少地方。
全是自己的理解,如有不当欢迎指出。
[1]https://blog.csdn.net/fish_like_apple/article/details/82856012
[2]https://blog.csdn.net/fish_like_apple/article/details/82691746
[3]SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling (https://arxiv.org/pdf/1505.07293.pdf)
[4]SmoothL1Loss https://blog.csdn.net/wfei101/article/details/79252021
}