NLP论文阅读记录 - 01 | 2021 神经抽象摘要方法及摘要事实一致性综述
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 二.背景
-
- 2.1自动总结任务
- 2.2 数据集
-
- DUC-2004
- Gigaword [Graff et al., 2003, Napoles et al., 2012]
- CNN/DailyMail [Nallapati 等人,2016]
- XSum [Narayan 等人,2018]
- 2.3 摘要系统的评估
-
- 2.3.1 Rouge [Lin, 2004]
- 三.抽象概括技术
-
- 3.1 前神经网络时代
-
- 3.1.1 统计方法 [Banko et al., 2000]
- 3.1.2 基于删除的方法 [Knight 和 Marcu,2002]
- 3.2基于 CNN/RNN 的方法
-
- 3.2.1 ABS [Rush et al., 2015]
- 3.2.2 RAS-LSTM & RAS-Elman [Chopra et al., 2016]
- 3.2.3 分层注意力 RNN [Nallapati 等人,2016]
- 3.2.4 指针生成器网络 [参见 et al., 2017]
- 3.2.5 自下而上的总结 [Gehrmann et al., 2018]
- 3.3 基于变压器的方法
-
- 3.3.1 BertSum [Liu and Lapata, 2019]
- 3.3.2 BART [Lewis et al., 2020]
- 3.3.3 PEGASUS [Zhang et al., 2020]
- 3.4 使用 RL 进行文本摘要
-
- 3.4.1 深度强化模型 [Paulus et al., 2018]
- 3.4.2 从人类反馈中总结 [Stiennon 等人,2020]
- 四 抽象摘要系统的事实一致性
-
- 4.1事实一致性与正确性
- 4.2 最近的方法
-
- 4.2.1事实条件生成 [Cao et al., 2018]
- 4.2.2 基于 QA 的评估方法 [Durmus 等人,2020,Wang 等人,2020]
- 4.2.3 FactCC [Kryscinski 等人,2020]
- 五 讨论
- 六 结论
前言

A Survey on Neural Abstractive Summarization Methods and Factual Consistency of Summarization(2111)
0、论文摘要
一、Introduction
自动摘要是通过计算缩短一组文本数据的过程,以创建代表原始文本中最重要信息的子集(摘要)。
现有的摘要方法大致可以分为两种:抽取式和抽象式。
提取摘要器显式地从源文档中选择文本片段(单词、短语、句子等),而抽象摘要器则生成新颖的文本片段以传达源文档中最常见的最显着的概念。
本次综述的目的是对最先进的抽象概括方法进行彻底的调查,并讨论这些方法面临的一些挑战。我们专注于抽象摘要任务,因为它在计算上比提取方法更具挑战性,并且更接近人类编写摘要的方式。
本次调查分为两个部分。
在第一部分中,我们将探讨一些经典和最新的总结方法。重点将是基于神经网络的抽象概括方法。
首先,我们将简要回顾一下前神经网络时代的一些非神经抽象概括方法。大多数这些方法使用基于删除的 [Knight and Marcu, 2002] 或统计模型 [Banko et al., 2000]。
其次,我们详细研究了五种基于神经的抽象文本摘要模型 [Rush et al., 2015, Chopra et al., 2016, Nallapati et al., 2016, See et al., 2017, Gehrmann et al., 2018,保卢斯等人,2018]。这些方法都采用循环神经网络(RNN)或卷积神经网络(CNN)架构来表示句子。借助神经网络的表示能力和大型训练数据集,这些模型在很大程度上优于以前的非神经摘要方法。
然后,我们将继续使用大型预训练语言模型进行抽象摘要的最新工作[Liu and Lapata, 2019, Lewis et al., 2020, Zhuang et al., 2020, Stiennon et al., 2020]。与之前基于 RNN 的方法不同,这些模型基于 Transformer 架构 [Vaswani et al., 2017],并在摘要任务上进行微调之前对大量原始文本进行预训练。
在第二部分中,我们将讨论抽象摘要系统的事实一致性评估方面的一些最新工作。摘要的事实一致性取决于其与输入文档中事实的一致性。对于抽取系统来说,由于所有句子都是从源中抽取的,因此其事实一致性基本上得到了保证。用于抽象概括然而,模型很容易生成统计上可能但实际上不一致的摘要。常见的事实错误包括操纵源文档中的信息以及添加无法直接从源中推断出的信息。事实错误在基于大量在线文本预训练的大规模基于 Transformer 的抽象摘要模型中尤其常见。
二.背景
2.1自动总结任务
摘要系统旨在将单个文档、一组新闻文章、对话或电子邮件线程作为输入,并对原始内容中最重要的信息生成简洁的摘要 [Nenkova 和 McKeown,2011]。
大多数摘要系统可以大致分为两类:抽取式和抽象式。
提取式摘要方法通过从原始文档中选择重要片段并将它们组合在一起形成连贯的摘要来生成摘要。抽象方法首先构建原始文本的内部语义表示,然后使用该表示创建一个简洁的摘要,以捕获文本的核心信息。
与提取摘要方法相比,抽象摘要方法可以生成更简洁的摘要。例如,比源文档中的任何句子都短的摘要。然而,抽象摘要在计算上比提取摘要更具挑战性,并且需要对原始内容有深入的理解。
2.2 数据集
在本节中,我们将讨论四种常用的摘要数据集。这些数据集都是英文的,用于单文档摘要任务。请注意,还有许多其他不同的摘要数据集是为不同的任务设计的(例如医学摘要、网络摘要)。我们选择这四个是因为他们比较有代表性。
DUC-2004
该数据集是在 DUC-20041 总结竞赛中引入进行评估的。该数据集包含来自《纽约时报》和美联社通讯社服务的 500 篇新闻文章。每篇文章都配有 4 篇不同的人工撰写的参考摘要。 DUC-2004 旨在关注非常短(≤ 75 字节)的摘要,从而激励参与者超越提取方法。
Gigaword [Graff et al., 2003, Napoles et al., 2012]
Gigaword 是一个标题生成语料库,由大约 400 万个标题-文章对组成。 Gigaword 中的文章和摘要比 DUC-2004 中的文章和摘要要短。数据集中的新闻文章来自各种国内外新闻机构。
CNN/DailyMail [Nallapati 等人,2016]
CNN/DailyMail 数据集包含 CNN 和 DailyMail 记者撰写的超过 30 万篇独特的新闻文章。原始数据集是为机器阅读和理解以及抽象问答而创建的。纳拉帕蒂等人。 [2016]按原始顺序连接每篇文章的所有摘要项目符号以获得多句子概括。 CNN/DailyMail 可用于训练抽象和提取摘要模型。然而,该数据集本质上更具提取性。
XSum [Narayan 等人,2018]
为了创建不支持提取模型的大规模抽象摘要数据集,Narayan 等人。 [2018]从英国广播公司(BBC)收集了226,711篇在线文章。每篇 BBC 文章都以一句话摘要开头,可以用作简短的新闻摘要,捕获文章最重要的信息。与Gigaword中的标题不同,Gigaword的标题是为了鼓励读者阅读故事; XSum 中的摘要利用了分散在文档各个部分的信息。 XSum 数据集的规模和抽象性使其适合训练和评估抽象摘要系统。然而,需要指出的是,XSum 中的一些摘要包含无法从源文档推断出的信息。
2.3 摘要系统的评估
它们是评估抽象摘要系统的两种主要方法:
一种是收集人类对输出摘要质量的判断,另一种是将输出摘要与人类编写的黄金标准进行比较。
总体而言,人类的判断可以说是最好的,但它既耗时又昂贵。在本节中,我们将讨论摘要系统评估最常用的自动度量:ROUGE 分数。
2.3.1 Rouge [Lin, 2004]
Rouge 代表面向回忆的 Gisting 评估替补。它是摘要系统最常用的自动评估指标之一。 Rouge 计算生成的摘要和参考摘要之间的重叠程度。 Rouge 乐谱有几种变体。 Rouge-N 计算生成的摘要和黄金标准参考摘要之间重叠 n 元语法的百分比。它的定义如下:

其中Sreference是参考摘要集,n代表n-gram的长度,gramn,Count计算gramn在参考摘要中出现的次数,Countmatch是输出摘要中n-gram共现的次数,参考摘要。总之,分子计算在输出摘要和参考中找到的重叠 n 元语法的数量。分母计算参考中 n 元语法的总数。这是一项与召回相关的措施,以确保输出摘要捕获参考文献中包含的所有信息。为了惩罚生成很长摘要的模型,通过将分母替换为输出摘要中的 n 元语法总数来计算与精度相关的指标。有了精确率和召回率分数,我们可以计算出更平衡的 Rouge F1 度量:
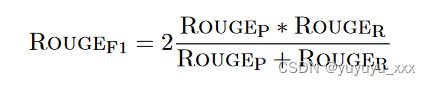
Rouge-L 测量输出摘要和参考摘要之间的最长公共子序列 (LCS)。这个想法是,较长的共享序列表明两个摘要之间的相似性较高。 Rouge-L 的计算方式与 Rouge-N 几乎完全相同,但用最长公共子序列的长度替换分子中的公共 n 元语法计数。
三.抽象概括技术
我们根据是否使用神经网络将现有的摘要方法大致分为两类。对于基于神经网络的模型,我们根据是否以半监督方式对原始文本进行了预训练来进一步对它们进行分类。由于几乎所有预训练模型都使用 Transformer 架构,因此我们将预训练汇总模型称为基于 Transformer 的模型。在 3.4 节中,我们将讨论基于 RL 的摘要方法。
3.1 前神经网络时代
3.1.1 统计方法 [Banko et al., 2000]
看待抽象概括的一种方法是将其视为类似于统计机器翻译的问题。给定一个输入文档 x,摘要任务是找到:
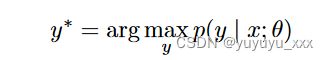
其中 θ 是统计模型的参数。最重要的问题是如何对p进行建模。班科等人。 [2000]的方法包括两个主要步骤:内容选择和表面实现。内容选择的任务是估计某些标记出现在给定源文档的摘要中的可能性。该概率可以估计为以下可能性的乘积:(i) 为摘要选择的标记,(ii) 摘要的长度,以及 (iii) 所选标记最可能的排序:
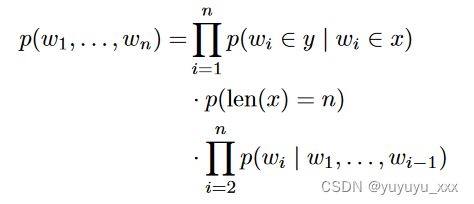
其中 p(len(x) = n) 可以使用高斯分布进行建模,p(wi ∈ y | wi ∈ x) 可以使用贝叶斯法则计算:
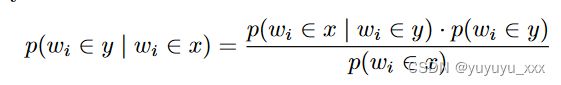
对于表面实现,可以使用二元语言模型来估计任何特定表面排序作为摘要的概率。结合内容和摘要结构生成,总体评分函数如下:
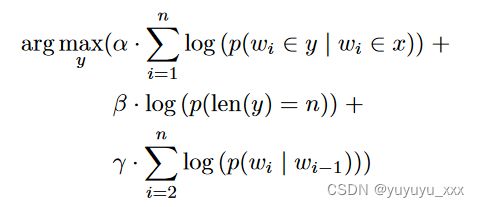
其中α、β和γ是通过交叉验证学习的超参数。
在这项工作中,内容选择和词序是使用从训练语料库中学习的统计模型联合应用的。后来出现的基于神经网络的摘要模型也采用了类似的思想。
3.1.2 基于删除的方法 [Knight 和 Marcu,2002]
Knight 和 Marcu [2002] 关注文本摘要问题的缩小版:句子压缩。任务设置如下:以自然语言句子作为输入,删除输入句子中的任意单词子集,并确保剩余单词(顺序不变)形成语法压缩。
他们首先将输入句子转换为语法树,并通过在树上应用一系列移位-归约-删除操作来执行重写操作。这种基于删除的方法的一个局限性是无法生成新单词和新颖的句子结构。
3.2基于 CNN/RNN 的方法
3.2.1 ABS [Rush et al., 2015]
兴趣分布 p(yi+1|x, yc; θ) 是基于输入文本 x 和先前生成的标记 yc 的条件语言模型。 [Rush et al., 2015] 工作的核心是将分布直接参数化为神经网络。这为基于神经网络的摘要系统打开了一扇门。具体来说,他们的网络包含一个用于估计下一个标记的上下文概率的神经语言模型和一个充当条件摘要模型的编码器模块。
作者探索了三种类型的编码器模型:词袋编码器、卷积编码器和基于注意力的编码器。我们将详细讨论每种类型的编码器模型。
词袋编码器 词袋编码器简单地计算输入标记嵌入的平均值,而不考虑词序或关系的属性: fenc(x, yc) = 1 M ΣM i=0 F xi = 1 M ΣM i=0 ̃ xi,其中 F ∈ RH×V 是输入侧词嵌入矩阵,xi ∈ {0, 1}V 是大小为 V 的 one-hot 向量。请注意,F 是词袋编码器的唯一参数。
卷积编码器 该编码器使用深度卷积网络对输入句子进行编码。卷积编码器总共有L层。在每一层,上下文标记首先使用 1D 卷积层进行编码: ̄ xli = Ql ̃ xl−1 [i−Q,…,i+Q],其中 ̃ xl−1 是前一层的输出(或第一层的词嵌入); l 是层数,Q 是上下文窗口大小。然后,有一个 2 元素时间最大池化层和一个点式非线性层:tanh(max{ ̄ xl2i−1, ̄ xl2i})。在顶部,执行最大池化时间以获得最终的输入文本表示。
基于注意力的编码器 受到机器翻译中 [Bahdanau et al., 2015] 注意力机制的启发,作者还应用基于注意力的编码器来学习输入文本和生成的摘要之间的潜在软对齐。该模型可以写成如下:
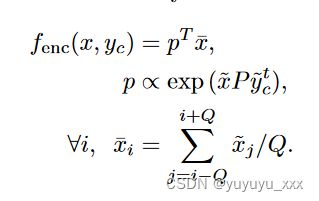
其中 ̃ x 是输入端词嵌入, ̃ yt c 是输出端嵌入,上下文大小等于 C: ̃ yt c = [yt−C+1, . 。 。 ,yt]。非正式地,我们可以将此模型视为用学习的对齐分布 p 替换词袋编码器中的均匀分布。
解码器 用于估计下一个标记的上下文概率,Rush 等人。 [2015] 采用前馈神经网络语言模型(NNLM)。完整模型可以描述为
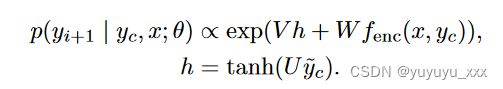
其中 U、V、W 是模型参数。
Training Rush 等人的培训。 [2015],作者通过使用小批量随机梯度下降最小化负对数似然损失来训练摘要模型。
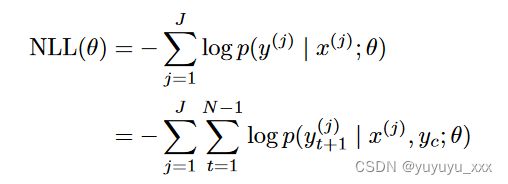
其中 yc 是黄金标准上下文(教师强制)。 J 是小批量的大小。本节的所有其他工作均采用相同的训练方法。
这项工作的一个限制是编码器受到上下文窗口的限制。接下来,我们看看 Chopra 等人是如何做到的。 [2016]使用循环神经网络来解决这个限制。
3.2.2 RAS-LSTM & RAS-Elman [Chopra et al., 2016]
乔普拉等人。 [2016] 改进了 Rush 等人。 [2015] 的工作是将前馈神经网络解码器(NNLM)替换为循环神经网络(RNN)。与NNLM相比,RNN可以在其能力范围内建模任意长的上下文,而不需要手动选择上下文长度C。先前的上下文信息存储在RNN的隐藏状态ht中。 RNN 用于对以下条件概率分布 pt 进行建模:
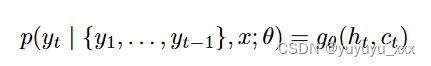
其中 ct 是编码器输出,ht 是 RNN 的隐藏状态:

作者探索了两种类型的 RNN 解码器:Elman RNN [Elman, 1990] 和 LSTM Hochreiter and Schmidhuber [1997]。
Elman RNN Elman RNN 定义为:
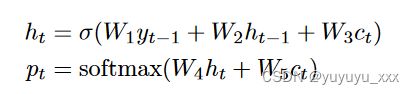
其中 W{1,2,3,4,5} 都是神经网络的可学习参数。
LSTM LSTM 解码器比 Elman RNN 更复杂,具有更多内部层:
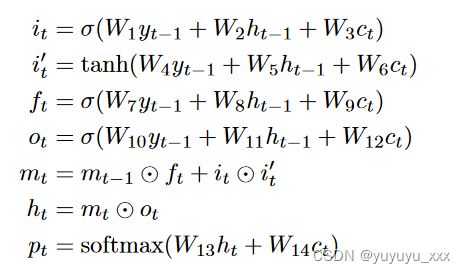
其中 W{1,2,…,12} 是解码器的可学习参数。操作 ⊙ 指的是分量乘法。
3.2.3 分层注意力 RNN [Nallapati 等人,2016]
与 Rush 等人相比。 [2015]和乔普拉等人。 [2016] 的方法,Nallapati 等人。 [2016]的工作引入了四个主要变化:首先,它将RNN应用于编码器和解码器网络。其次,编码器模型的输入不仅是基于词嵌入的表示,还包括其他语言特征,例如词性标签、命名实体标签以及单词的 TF 和 IDF 统计信息。第三,模型的解码器采用指针机制来处理生僻词。最后,他们为解码器设计了一个分层注意力结构来处理长源文档。我们将详细讨论每一点。
Nallapati 等人的 RNN 编码器-解码器。 [2016],作者采用双向 GRU-RNN [Chung et al., 2014] 作为编码器,并采用具有相同隐藏层大小的单向 GRU-RNN 作为解码器。他们还在每个时间步对编码器的隐藏状态应用注意机制。他们使用的另一种技术称为大词汇量技巧 (LVT) [Jean et al., 2015]。这个想法是将解码器词汇限制为仅出现在当前小批量训练中源文档中的单词。为了使词汇量固定,还添加了目标词典中最常用的单词。 LVT技术用于减少softmax层计算并加快训练速度。
指针机制摘要中的一个问题是输入文档通常包含词汇表中不存在的稀有词,例如关键词或命名实体。当时,词块分词器还没有被广泛使用。提出指针机制是为了使模型能够直接从输入中复制那些词汇表外的单词(OOV)。在每个解码步骤中,解码器决定是从词汇表生成单词还是从源文档复制标记。这有时也称为“复制机制”。基于每个时间步的整个可用上下文,复制概率被建模为线性层上的 sigmoid 激活函数,如下所示:

其中 hi 是 RNN 隐藏状态,yt−1 是先前生成的 token 的嵌入,ci 是注意力加权上下文向量,Wh、Wy、Wc、b 和 v 是可学习参数。 si 是指示变量,指示是否从输入文档复制标记。他们将文档单词的注意力权重重新用作该单词被复制的概率。
分层注意力机制 为了处理很长的输入文档,Nallapati 等人。 [2016]提出了一种分层注意力结构来捕获单词级和句子级信息。他们的模型中的源端有两个双向 RNN。一个在单词级别运行,另一个在句子级别运行。单词级注意力进一步受到句子级注意力的加权。最后,使用重新归一化的词级注意力来计算注意力加权上下文向量ci。
3.2.4 指针生成器网络 [参见 et al., 2017]
参见等人。 [2017] 的工作与 Nallapati 等人类似。 [2016]的模型中,它们都使用基于RNN的序列到序列架构,并且都使用指针机制来处理源文档中的OOV单词。 See 等人有两个主要区别。 [2017] 的工作。首先,作者在解码时混合了来自副本分布和词汇分布的概率: P (w) = pgenPvocab(w) + (1 − pgen) Σ i:wi=w ait,其中 w 是文档中的 OOV 单词, ait 是解码步骤 t 处的注意力权重。
其次,参见等人。 [2017]引入覆盖机制来解决抽象摘要中的重复问题。他们维护一个覆盖向量 ct,它是所有先前解码器时间步长的注意力分布之和: ct = Σt−1 t′=0 at′ 。直观上,ct 表示源文档中的每个单词到目前为止受到的关注程度。覆盖向量用作注意力机制的附加输入。为了惩罚重复参与相同职位的模型,他们添加了一个新的覆盖损失项:

实验结果表明,覆盖损失对于消除重复、提高ROUGE分数是有效的。
3.2.5 自下而上的总结 [Gehrmann et al., 2018]
格尔曼等人。 [2018]提出了一种自下而上的抽象概括方法。他们使用与 See 等人相同的模型架构。 [2017]。他们的方法包括两个步骤:首先,他们应用内容选择系统来决定源文档的相关部分。这是一个序列标记任务,目的是识别源文档中的相关标记。在第二步中,他们使用掩码将复制的单词限制为文本的选定部分。
内容选择内容选择步骤被构建为二进制序列标记任务。对于源文档中的每个标记,它被标记为 1 或 0。如果单词相关,则标记为 1,否则标记为 0。为了为此任务创建训练集,作者将摘要与文档对齐。对于文档中的每个单词 xi,如果 (1) 它是标记 s 的最长可能子序列的一部分(如果 s ∈ x 且 y ∈ y),并且 (2) s 是单词中的第一次出现,则将其标记为相关。文档。他们为此标记任务训练了一个双向 LSTM 模型。
自下而上的复制注意力在训练期间,指针生成器模型和内容选择器模型在完整的数据集上进行训练,而无需屏蔽。在推理时,他们首先应用经过训练的内容选择器来预测每个标记被选择的概率 qi。然后,该选择概率用于调整源文档标记上的注意力分布。令 aij 为单词 i 的解码步骤 j 的注意力分数。调整后的注意力分数̃ aij 为

其中 ε 是预先确定的阈值。作者还重新规范化调整后的注意力分数,以确保其正确的概率分布
3.3 基于变压器的方法
在本节中,我们将讨论 Vaswani 等人提出的三种基于 Transformer 的方法。 [2017]摘要模型。与 3.2 节中提到的模型在摘要数据集上从头开始训练的方法不同,我们在本节中讨论的模型首先以无监督的方式在大型语料库上进行预训练,然后在摘要数据集上进行微调。预训练阶段帮助模型学习丰富的句法和语义知识,极大地提高了模型在摘要任务上的性能。
3.3.1 BertSum [Liu and Lapata, 2019]
与 Nallapati 等人相比。 [2016] 和 See 等人。 [2017] 的工作中,Liu 和 Lapata [2019] 也采用了序列到序列架构,但用 Transformer 架构取代了基于 RNN 的编码器和解码器。
Transformer Encoder 他们使用 6 层 Transformer 编码器模型。所有六层都是相同的(但参数不同),每层由两个子层组成,分别是多头自注意力网络和全连接前馈网络。每个子层都有残差连接和归一化,因此子层的输出可以表示为:
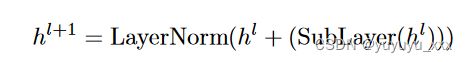
其中 hl 是前一个子层的输出。接下来,我们将按顺序讨论这两个子层:
- 多头自注意力:多头注意力使用 h 个不同的线性变换来投影 Q、K 和 V ,最后将输出连接在一起:

其中 h 是头的数量,{W Q i ,WK i ,WV i , W O} 是注意力参数。注意力函数如下:

其中 dk 是 K 的维数。 - 位置式前馈网络:该子层包含一个完全连接的前馈网络:
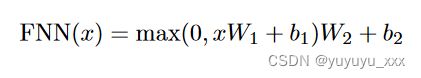
Transformer Decoder 与编码器类似,解码器也由 N = 6 个相同层组成。每个解码器层中有三个子层,其中两个子层与编码器中的两个子层相同。解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意力。在该子层中,K和V来自编码器任务输出,Q来自解码器前一层的输出。
BERT Bi Direction Encoder Representations from Transformers(BERT;Devlin et al. [2019])是一种基于 Transformer 的语言表示模型,使用 Masked Language Modeling (Masked LM) 任务和 Next Sentence Prediction (NSP) 任务进行训练。预训练语料库由BooksCorpus(8亿字)和英语维基百科(2,500M字)组成。对于 Masked LM 任务,模型经过训练可以预测输入句子中 15% 的随机屏蔽标记。屏蔽标记将替换为 [MASK] 符号。对于 NSP 任务,每个训练示例由句子 A 和 B 组成。B 有 50% 的机会是 A 之后的实际下一个句子,B 有 50% 的机会是从语料库中采样的随机句子。该模型经过训练可以预测 B 是否跟随 A。
BertSum 使用预训练的 BERT 模型作为编码器。为了学习更好的句子表示,BertSum 在每个文档句子的开头插入多个 [CLS] 标记并使用区间分段嵌入。对于解码器,BertSum 采用 6 层随机初始化的 Transformer 解码器模型。此外,Liu和Lapata [2019]提出了一种两阶段微调方法:编码器首先在提取摘要任务上进行微调,然后在抽象摘要任务上进行微调。
3.3.2 BART [Lewis et al., 2020]
与仅使用 Transformer 编码器构建的掩码语言模型 BERT 不同,BART 是使用基于 Transformer 的编码器和解码器构建的序列到序列去噪自动编码器。由于 BART 的序列到序列性质,它在针对文本生成任务(例如机器翻译、文本摘要)进行微调时特别有效。 BART 的预训练过程包括两个步骤(1)定义任意噪声函数来破坏原始句子,(2)训练 BART 来重建原始文本。他们使用标准令牌级交叉熵损失来进行重建损失。论文中介绍了五种类型的腐败函数:
- 令牌屏蔽:遵循 BERT Devlin 等人的观点。 [2019],随机抽取 15% 的 token 并用 [MASK] 屏蔽它们。
- 令牌删除:从输入中删除随机令牌。不使用 [MASK] 令牌。
- 文本填充:对多个文本跨度进行采样,跨度长度根据泊松分布(λ = 3)得出。每个采样范围都替换为单个 [MASK] 标记。
- 句子排列:随机打乱输入文档中句子的顺序。
- 文档旋转:在输入文档中随机选择一个标记,然后旋转文档,使其以该标记开头。该任务是预测文档的原始开头。
在 CNN/DailyMail 上,BART 大模型获得了 44.16 ROUGE-1 分数。在 XSum 上,ROUGE1 得分为 45.14。这两个结果都比基于 RNN 的模型高得多。他们还在 CNN/DailyMail 和 XSum 数据集上单独比较了五种预训练方法。结果表明,文本填充是五个目标中最有效的一个。单独旋转文档或排列句子效果不佳。
3.3.3 PEGASUS [Zhang et al., 2020]
PEGASUS 是一种基于 Transformer 的编码器-解码器模型,专门针对摘要任务进行预训练。它使用与 BART Lewis 等人相同的模型架构。 [2020] 模型。张等人。 [2020]提出了一个新的预训练任务:间隙句子生成(GSG)。这个想法是从文档中屏蔽整个句子,并训练语言模型以根据文档的其余部分生成屏蔽句子。每个屏蔽句子都被替换为特殊的 [MASK1] 标记来通知模型。他们提出了三种选择句子进行掩蔽的策略:(1)随机:随机均匀选择m个句子。 (2)lead:选择前m个句子,(3)principal:根据句子与文档其余部分之间的ROUGE F1分数选择得分最高的m个句子。在 XSum 上,PEGASUS 在 ROUGE 分数方面略好于 BART。
3.4 使用 RL 进行文本摘要
在强化学习中,智能体经过训练在环境中采取行动,以最大化累积奖励的概念。对于总结任务,强化学习提供了更大的灵活性,因为我们可以设计不同的奖励函数来关注模型的不同方面。 (例如事实一致性)。 保卢斯等人。 [2018]提出了一种混合学习目标函数,它将“教师强制”目标[Williams and Zipser, 1989]和自我批评的政策梯度训练目标[Rennie et al., 2017]结合起来。在标准的教师强制训练目标中,模型经过训练,以最小化每个解码步骤的地面实况摘要条件下的负对数似然损失: 斯蒂农等人。 [2020] 指出人类参考和 ROUGE 指标都是概括质量的粗略代理,这才是我们真正关心的。基于这个想法,作者提出通过训练摘要模型直接针对人类偏好进行优化来提高摘要质量。这与以前的训练方法有很大不同,以前的训练摘要模型是为了模仿人类演示(即参考摘要)。 Stiennon 等人提出了三个步骤。 [2020]的方法: 尽管在自动评估分数(例如 ROUGE [Lin,2004])方面比以前的方法有了显着改进,但确保生成的摘要相对于源的事实一致性仍然具有挑战性。表 1 显示了包含事实错误的输出摘要示例。造成此问题的原因之一是这些 n-gram 重叠度量不能保证生成的摘要的语义正确性。例如,曹等人。 [2018] 声称抽象模型生成的摘要中约有 30% 包含事实错误。梅内斯等人。 [2020] 发现 XSum 上基于 BERT 的抽象摘要模型生成的摘要中有 64.1% 包含幻觉。因此,检测抽象摘要系统引入的事实错误至关重要。 区分事实一致性和正确性很重要。两者不一定相等。摘要的事实一致性取决于其与源文件中事实的一致性。重点考察摘要是否真实、准确地呈现文章内容。相反,事实正确性侧重于与某些外部知识库(即世界知识)中的事实的一致性。例如,事实不正确的新闻文章可以以完美的事实一致性进行概括。 曹等人。 [2018]提出通过“双重注意”机制以从源文档中提取的事实为条件来提高摘要模型的事实一致性。 事实感知摘要模型 Cao 等人。 [2018]的模型由两个基于 GRU 的编码器组成:句子编码器和关系编码器。句子编码器对输入文档进行编码,关系编码器对提取的事实描述进行编码。对于解码器来说,由于有文档和关系表示作为输入,因此它们开发了两个注意力层来构建整体上下文向量。这被称为“双重关注”机制。 结果 作者对 Gigaword 测试集中的 100 个样本进行了事实一致性的人工评估,发现事实一致摘要的百分比(由人工判断)从 68% 提高到了 87%。 基于问答(QA)的评估方法已被证明可以有效地评估生成的摘要的事实一致性。这些方法背后的想法是,如果摘要和输入文档对于某个事件是一致的,那么当给出有关该事件的问题时,它们应该产生相同的答案。因此,摘要和源文档产生的相同答案越多,它们就越一致。这些方法中有三个重要的组成部分:问题生成模块、问答模块和答案相似度函数。 克里斯辛斯基等人。 [2020]提出了一种弱监督方法来验证输入文档和生成的摘要之间的事实一致性。他们的基本想法是训练自然语言人工创建的数据的推理模型。合成训练数据生成过程可概括如下: 结果 在数据创建过程之后,事实一致性分类器在合成数据上进行训练。作者将 931 个示例标记为验证集,将 503 个示例标记为测试集。在测试集上,他们的最佳模型实现了 72.88% 的加权准确率,比基于 BERT 的 NLI 基线模型高出约 20%。 Kryscinski 等人的一个局限性。 [2020]的方法是它无法正确对生成的摘要高度抽象的示例进行分类。 尽管研究界做出了巨大的努力,但抽象摘要仍然面临许多挑战: 在本次调查中,我们总结并分析了最先进的基于神经网络的抽象摘要方法。我们还指出,这些模型还有许多挑战尚未解决,特别是摘要与来源之间的事实一致性问题。我们希望本次调查能够帮助研究人员更好地了解近年来抽象概括的发展,从而在该领域取得更具科学意义的进展。
从强化学习的角度来看,摘要生成过程可以看作是有限马尔可夫决策过程(MDP)。在每个时间步 t,状态 st = (y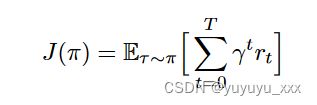
其中 γ 是折扣因子。在文本生成中,通常在生成整个序列时获得奖励(即rt3.4.1 深度强化模型 [Paulus et al., 2018]

其中 y* = {y* 1, y* 2, . 。 。 , y* n} 是给定输入文档 x 的真实参考序列。这个教师强制目标有两个主要问题。第一个问题被称为曝光偏差 [Ranzato et al., 2016]。它来自这样一个事实:语言模型经过训练,可以在给定先前的真实标记作为输入的情况下预测下一个标记。然而,在推理时,模型没有这种监督,并且生成的令牌必须在每个时间步作为输入反馈。这种差异使得模型在推理时很脆弱,并且很快就会出错积累。第二个问题是,教师强制目标并不总是与 ROUGE 等离散评估指标相关,因为 ROUGE 指标不考虑令牌顺序。
缓解这些问题的一种方法是使用强化学习来直接优化目标评估指标。现在考虑两个序列 ys 和 ^ y。 ys 是通过在每个解码时间步从 p(ys t | ys 1, . . . , ys t−1, x) 概率分布中采样获得的,并且 ˆ y 是使用贪婪解码获得的: arg maxˆ yt p(ˆ yt | ^ y1,…, ^ yt−1, x)。 RL 目标如下:
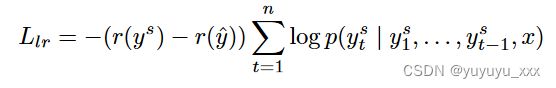
其中 ^ y 是基线输出,r 是奖励函数(即 ROUGE 指标)。
提高生成的摘要的评估分数,而不损害其人类可读性或相关性。作者提出了一个混合学习目标函数,它结合了两个目标:
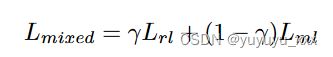
作者对输出摘要的相关性(摘要捕获文章重要部分的程度)和可读性(摘要写得如何)进行人工评估。要求五位评估员为生成的每个摘要分配 1 到 10 分。在这两个指标上,混合目标获得了最高平均得分 7.04(可读性)和 7.45(相关性)。对于 RL 目标,平均得分为 4.18 和 6.32。对于教师强迫目标,得分为 6.76 和 7.14。3.4.2 从人类反馈中总结 [Stiennon 等人,2020]

其中 D 是人类判断的数据集。 i ∈ {0, 1} 是人类偏好标签。

其中 πRL 是学习策略,πSFT 是监督模型。该术语确保学习到的策略不会与参考偏差太大。
结果 在 TL;DR 数据集上,所提出的模型相对于参考摘要获得了 61% 的偏好分数(来自人类评委)。它显着优于监督基线 43% 的分数。四 抽象摘要系统的事实一致性

不幸的是,即使对于人类来说,确定摘要的事实正确性也是极其困难的。在本节中,我们将讨论最近提出的一些抽象摘要系统的事实性评估方法。4.1事实一致性与正确性
4.2 最近的方法
4.2.1事实条件生成 [Cao et al., 2018]
事实描述提取 曹等人的第一步。 [2018]的方法是从源文档中提取事实描述。他们使用开放信息提取 (OpenIE) 来提取源文档中的关系三元组(主语、谓语、宾语),并将它们连接在一起作为文本描述。然后,他们使用依赖解析器提取 OpenIE 未捕获的(主语;谓词)或(谓词;宾语)元组。4.2.2 基于 QA 的评估方法 [Durmus 等人,2020,Wang 等人,2020]
问题生成模块 为了根据摘要自动生成问题,Durmus 等人。 [2020] 屏蔽摘要句子中的所有名词短语和命名实体。每个屏蔽文本范围都被视为黄金标准答案。为了生成问题,Durmus 等人。 [2020] 在 QA2D 数据集上微调 BART 语言模型 [Demszky et al., 2018]。王等人。 [2020]遵循非常相似的问题生成方法。他们在 NewsQA 数据集上微调 BART 语言模型,该数据集由 CNN 文章和人工编写的问题组成。
问答模块 给出基于摘要的问题和答案对,Durmus 等人。 [2020]和王等人。 [2020] 使用现成的 QA 模型从源文档中生成问题的答案。
答案相似性函数 Durmus 等人。 [2020]和王等人。 [2020]使用令牌级F1分数来评估生成的答案。最终的忠实度分数是通过对所有生成的问题的答案相似性度量进行平均而得出的。在人工注释的摘要忠实度数据集上,与 ROUGE 指标相比,他们的方法都获得了更高的相关性分数。4.2.3 FactCC [Kryscinski 等人,2020]
五 讨论
1)确保生成的摘要与来源的事实一致性具有挑战性。造成这种情况的主要原因有两个:首先,很难为摘要模型设计快速、低成本的事实感知评估指标。大多数使用的n-gram评估方法没有考虑事实一致性。另一方面,人工评估过程过于昂贵且耗时。
其次,许多抽象概括数据集是自动生成的,其中不可避免地包含噪声。神经网络模型在训练过程中很容易过度拟合这些噪声,并在推理过程中产生非事实错误。
3)随着模型规模的增长,对训练数据的需求也随之增加。它需要研究人员找到样本高效的训练方法。一种可能的方向是找到对总结任务具有良好归纳偏差的预训练目标。
六 结论