2020CVPR | ATSS——最新技术的目标检测(文末源码下载)
点击蓝字关注我们

computerVision
计算机视觉战队
● 扫码关注,回复:ATTS ●
获取原文和源码下载链接
今天我们从录用的CVPR2020文章中选了一篇目标检测的优秀文章:ATSS:Bridging the Gap Between Anchor-based and Anchor-free Detection。

简要
详细解释了anchor-free与anchor-based的本质区别,此外,使用ATSS去尝试解决label assignment的问题;
ATSS是目标检测中可以学习借鉴的点,解决正负样本的选取问题。无论是anchor-based还是anchor-free采用ATSS都有一定的性能提升;
当前Anchor-free detectors可以分为两种类型:
1)Keypoint-based:Cornernet、Centernet;
2) Center-based:FCOS、Foveabox;
ATSS需要借助于铺设1个anchor来选取正样本,但无论这1个anchor铺什么比例,或铺多大尺寸,ATSS提升都挺稳定,主要是因为ATSS会根据目前所铺设的anchor,自适应地根据统计信息来选取合适的正负训练样本;
关于label assign的上限问题。由于label assign没有ground-truth,因而很难做上限分析。关注label assign的除了FreeAnchor、PISA、ATSS之外,还有一篇与ATSS几乎同时放出来的MAL,它的ResNet-50的结果也是39.2。虽然实现方式各有差异,但都只做到39出头。
01
创新
基于上述分析的区别,先指出了anchor-based检测与anchor-free检测的本质区别;
提出了一种自适应训练样本选择(ATSS),根据目标的统计特征自动选择正样本和负样本;
讨论了在图像上每个位置平铺多个anchor点来检测目标的必要性。正确的选取正负样本以后并不是很有必要平铺多个anchor。
02
背景
目标检测是计算机视觉领域中一个由来已久的课题,其目的是检测预先定义的目标。准确的目标检测将对图像识别和视频监控等多种应用产生深远的影响。近年来,随着卷积神经网络(CNN)的发展,基于锚定的目标检测方法逐渐成为主流,一般可分为一级方法和两级方法。这两种方法首先在图像上平铺大量的预设锚定,然后预测锚定的类别并对锚定的坐标进行一次或多次细化,最后将这些细化后的锚定作为检测结果输出。
由于两阶段法对锚杆的细化程度是一阶段法的七倍以上,前者的结果更准确,后者的计算效率更高。通用检测基准的最新结果仍然由基于锚的检测器保存。然而,由于FPN的出现和Focal Loss,近年来学术界关注的焦点转向了无锚探测器。无锚探测器通过两种不同的方式直接查找没有预设锚的物体。
一种方法是首先定位几个预定义或自学习的关键点,然后限定对象的空间范围。我们称这种类型的无锚检测器为基于关键点的方法。另一种方法是利用物体的中心点或区域来定义正样本,然后预测从正样本到物体边界的四个距离。我们称这种无锚检测器为基于中心的方法。这些无锚检测器能够消除与锚相关的超参数,并取得了与基于锚的检测器相似的性能,使得它们在泛化能力方面更具潜力。在这两种类型的无锚检测器中,基于关键点的方法遵循不同于基于锚检测器的标准关键点估计管道。然而基于中心的检测器类似于基于锚的检测器,它将点作为预设样本而不是锚箱来处理。
以单级锚定检测器RetinaNet和中心锚定检测器FCOS[56]为例,它们之间有三个主要区别:(1)每个位置平铺的锚数。RetinaNet为每个位置平铺多个锚定框,而FCOS为每个位置平铺一个锚定点1;(2) 正样本和负样本的定义。RetinaNet重新排序到交集上的正和负,而FCOS则利用空间和尺度约束来选择样本;(3) 回归开始状态。
RetinaNet从预设锚定框回归对象边界框,而FCOS从锚定点定位对象。如《Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS:fully convolutional one-stage object detection. In ICCV,2019.》所述,无锚FCOS比基于锚的RetinaNet具有更好的性能,值得研究这三个差异中的哪一个是导致性能差距的关键因素。
作者通过严格排除锚定方法和无锚方法之间的所有实现不一致性,公正地研究了锚定方法和无锚方法之间的差异。从实验结果可以看出,这两种方法的本质区别在于对正反两种训练样本的定义,从而导致了它们之间的性能差距。如果他们在训练中选择了相同的正负样本,那么无论从一个盒子或一个点回归,最终的表现都没有明显的差距。
因此,如何选择正负的训练样本值得进一步研究。受此启发,提出了一种新的自适应训练样本选择(ATSS)方法,根据目标特征自动选择正负样本。它弥补了基于锚和无锚探测器之间的差距。此外,通过一系列的实验可以得出这样的结论:ATSS不需要在图像上的每个位置贴上多个锚来检测物体。新算法框架在MS-COCO数据集上的大量实验支持作者的分析和结论。最先进的AP 50.7%是通过应用新引入的ATS而不引入任何开销来实现的。
03
Difference Analysis of Anchor-based andAnchor-free Detection
在不丧失一般性的情况下,采用了具有代表性的锚定RetinaNet和无锚FCOS来剖析它们之间的差异。作者将重点讨论最后两个差异:正/负样本定义和回归开始状态。
剩下的一个区别是:每个位置平铺的锚的数量,将在后续章节中讨论。因此,作者只为RetinaNet的每个位置平铺一个方形锚,这与FCOS非常相似。在剩下的部分中,首先介绍实验设置,然后排除了所有实现上的不一致,最后指出了基于锚和无锚检测器之间的本质区别。经过实验分析,可以看出来FCOS比RetinaNet实际AP值只高了0.8个点。
实验设置
Dataset. All experiments are conducted on the challenging MS COCO dataset that includes 80 object classes.Following the common practice, all 115K imagesin the trainval35k split is used for training, and all 5Kimages in the minival split is used as validation for analysis study. We also submit our main results to the evaluationserver for the final performance on the test-dev split.
Training Detail. We use the ImageNet pretrainedResNet-50 with 5-level feature pyramid structure asthe backbone. The newly added layers are initialized in thesame way as in [Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He,and Piotr Dollar. Focal loss for dense object detection. In ´ICCV, 2017.]. For RetinaNet, each layer in the 5-levelfeature pyramid is associated with one square anchor with8S scale, where S is the total stride size. During training,we resize the input images to keep their shorter side being800 and their longer side less or equal to 1,333. The wholenetwork is trained using the Stochastic Gradient Descent(SGD) algorithm for 90K iterations with 0.9 momentum,0.0001 weight decay and 16 batch size. We set the initiallearning rate as 0.01 and decay it by 0.1 at iteration 60K and 80K, respectively. Unless otherwise stated, the aforementioned training details are used in the experiments.
Inference Detail. During the inference phase, we resize theinput image in the same way as in the training phase, andthen forward it through the whole network to output the predicted bounding boxes with a predicted class. After that, weuse the preset score 0.05 to filter out plenty of backgroundbounding boxes, and then output the top 1000 detectionsper feature pyramid. Finally, the Non-Maximum Suppression (NMS) is applied with the IoU threshold 0.6 per classto generate final top 100 confident detections per image.

Essential Difference
分类
在应用了这些普遍的改进之后,这些仅仅是基于锚的RetinaNet(#A=1)和无锚FCOS之间的两个区别。一个是关于检测中的分类子任务,即定义正样本和负样本的方法。另一个是关于回归子任务,即从锚箱或锚点开始的回归。
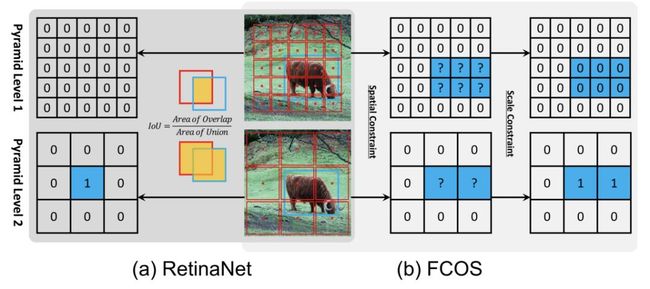
如上图(a)所示,RetinaNet利用IoU将来自不同金字塔层的锚划分为正样本和负样本。首先将每个对象的最优锚框和IoU>θp的锚标记为正,然后将IoU<θn的锚标记为负,最后在训练过程中忽略其他锚。上图(b)所示,FCOS使用空间和比例约束来从不同的金字塔级别划分锚点。它首先将地面真值框中的定位点作为候选正样本,然后根据为每个金字塔级别定义的比例范围从候选中选择最终的正样本,最后未选择的定位点为负样本。
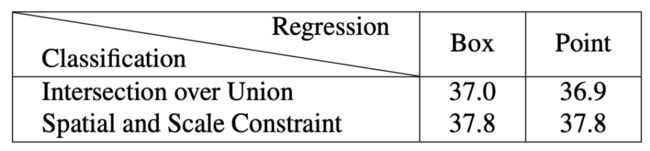
具体地,FCOS首先使用空间约束来查找空间维度中的候选正数,然后使用比例约束来选择比例维度中的最终正数。相反,Retinanet网利用IoU在空间和尺度维度上同时直接选择最终的正样本。这两种不同的样本选择策略产生不同的正负样本。如下表第一列所列,对于RetinaNet(#A=1),使用空间和比例约束策略代替IoU策略将AP性能从37.0%提高到37.8%。对于FCOS,如果使用IoU策略选择正样本,AP性能将从37.8%下降到36.9%,如下表第二列所示。这些结果表明,正样本和负样本的定义是锚定检测器和无锚检测器的本质区别。
回归
在确定正样本和负样本之后,对象的位置从正样本回归,如下图(a)所示。

RetinaNet从锚定框回归,锚定框和对象框之间有四个偏移,如上图(b)所示,而FCOS从锚定点回归,四个距离到对象的边界,如上图(c)所示。这意味着对于正样本,RetinaNet的回归起始状态是一个box,而FCOS是一个点。
然而,如上表2第一行和第二行所示,当RetinaNet和FCOS采用相同的样本选择策略来获得一致的正/负样本时,无论从一个点或一个框开始回归,即37.0%对36.9%和37.8%对37.8%,最终的性能都没有明显的差异。这些结果表明回归开始状态是一个不相关的差异而不是本质的差异。
小结论
通过这些实验,作者可以指出单级锚定检测器与中心锚定检测器的本质区别在于如何定义正负训练样本,这对当前的目标检测具有重要意义,值得进一步研究。
04
Adaptive Training Sample Selection
在训练目标检测器时,首先需要定义正样本和负样本进行分类,然后使用正样本进行回归。根据前面的结论,前者是关键,而无锚探测器FCOS改进了这一步骤。它引入了一种新的正负定义方法,比传统的基于IoU的策略获得了更好的性能。受此启发,作者深入研究了目标检测中最基本的问题:如何定义正负训练样本,并提出了自适应训练样本选择(ATSS)。与这些传统策略相比,该方法几乎没有超参数,并且对不同的环境具有鲁棒性。
描述
以往的样本选择策略都有一些敏感的超参数,如基于锚的检测器的IoU阈值和无锚检测器的尺度范围。这些超参数设置后,所有的地面真值盒都必须根据固定的规则来选择其正样本,这些规则适用于大多数对象,但会忽略一些外部对象。因此,这些超参数的不同设置将产生非常不同的结果。为此作者提出了一种ATSS方法,它几乎不需要任何超参数就可以根据对象的统计特性自动划分正、负样本。

上面的 Algorithm 1描述了所提出的方法对输入图像的工作原理。对于图像上的每个地面真值框g,首先找出它的候选正样本。如第3至6行所述,在每个金字塔层上,我们根据L2距离选择中心距g中心最近的k个锚箱。假设有L个特征金字塔层,则地面真值框g将有k×L个可检出阳性样本。之后计算出这些候选值与7号线的地面真值g(Dg)之间的IoU be,其平均值和标准差在8号线和9号线分别计算为mg和vg。利用这些统计数据,在第10行中,以tg=mg+vg的形式获得该地面真值g的IoU阈值。最后,选择IoU大于或等于阈值tg的候选样本作为第11行到第15行的最终正样本。
值得注意的是,作者还将正样本的中心限制在第12行所示的地面真值框内。此外,如果一个锚定框被分配给多个地面真相框,那么将选择IoU最高的一个。其余为负样品。我们的方法背后的一些动机解释如下。

Figure 3
Using the sum of mean and standard deviation as theIoU threshold. The IoU mean mg of an object is a measureof the suitability of the preset anchors for this object. A highmg as shown in Figure 3(a) indicates it has high-qualitycandidates and the IoU threshold is supposed to be high.A low mg as shown in Figure 3(b) indicates that most ofits candidates are low-quality and the IoU threshold shouldbe low. Besides, the IoU standard deviation vg of an objectis a measure of which layers are suitable to detect this object. A high vg as shown in Figure 3(a) means there is amost suitable pyramid level for this object, adding vg to mgobtains a high threshold to select positives only from thatlevel. A low vg as shown in Figure 3(b) means that thereare some pyramid levels suitable for this object, adding vgto mg obtains a low threshold to select appropriate positivesfrom these levels. Using the sum of mean mg and standarddeviation vg as the IoU threshold tg can adaptively selectenough positives for each object from appropriate pyramidlevels in accordance of statistical characteristics of object.
分析
只有一个超参数k,其实在金字塔的每一层确定的锚框的数目,经过试验证明这个参数是不敏感的,因而这种方法可以看做是一种非超参数的方法。而且试验发现anchor size也是不敏感的。
Hyperparameter k
作者进行了几个实验来研究超参数k的鲁棒性,它用于从每个金字塔级选择候选正样本。

Anchor scales

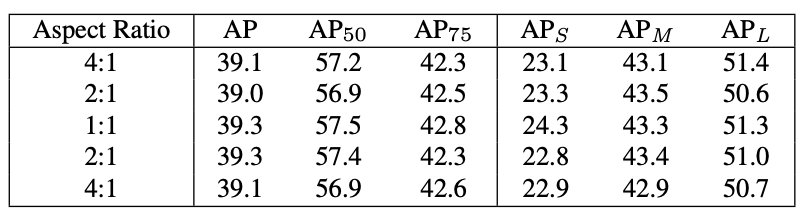
Anchor aspect
比较
作者将最终模型与其他最新对象检测器进行了比较如下表中所示。
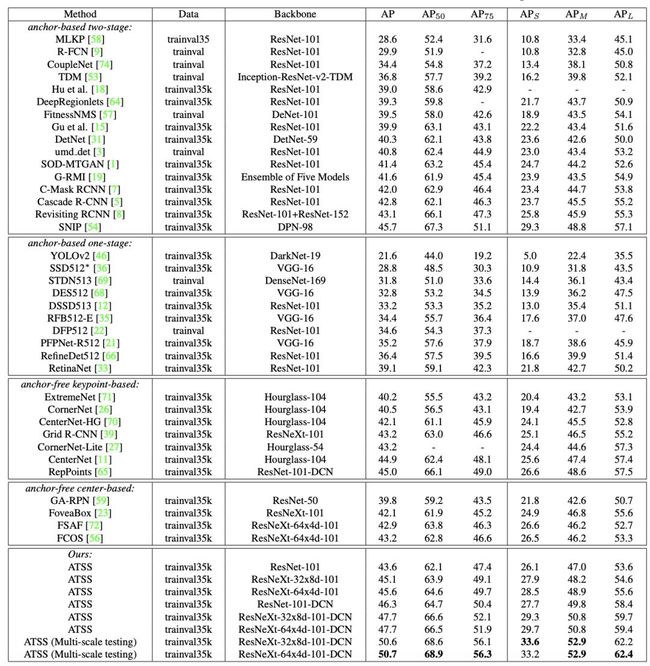
在前人工作的基础上,本文采用多尺度训练策略,即在训练过程中随机选取640-800之间的尺度来调整图像的短边。此外作者将总迭代次数增加一倍至180K,学习率降低点相应地增加至120K和160K。其他设置与前面提到的一致。如上表所示,作者使用ResNet-101的方法在没有任何钟声和哨声的情况下获得43.6%的AP,这比所有具有相同主干的方法都好,包括级联R-CNN(42.8%AP)、C-掩码RCNN(42.0%AP)、RetinaNet(39.1%AP)和RefineDet(36.4%AP)。
通过使用更大的骨干网ResNeXt-32x8d-101和ResNeXt-64x4d-101,作者可以将该方法的AP准确率进一步提高到45.1%和45.6%。45.6%的AP结果优于所有的无锚和基于锚的检测器,只比SNIP低0.1%(45.7%的AP),后者引入了改进的多尺度训练和测试策略。由于新提出的方法是关于正样本和负样本的定义,所以它与当前的大多数技术兼容和完整。因此,作者使用可变形卷积网络(DCN)对ResNet和ResNeXt骨干网以及最后一层探测塔进行分析。DCN使ResNet-101、ResNeXt-32x8d-101和ResNeXt-64x4d-101的AP性能分别提高到46.3%、47.7%和47.7%。单模型单尺度测试的最佳结果为47.7%,大大优于所有的先验检测器。最后,采用多尺度测试策略,提出的新方法的最佳模型达到了50.7%的AP。
讨论
以前的实验是基于每个位置只有一个锚的RetinaNet。基于锚和无锚探测器之间仍有一个未探索的差异:每个位置平铺的锚数量。实际上,最初的RetinaNet每个位置有9个锚(3个刻度×3个纵横比),作者将其标记为RetinaNet(#A=9),达到36.3%的AP,如下表第一行所列。

此外,下表中的这些普遍改进也可用于RetinaNet(#A=9),将AP性能从36.3%提高到38.4%。在不使用所提出的ATSS的情况下,改进的Reti naNet(#A=9)比Reti-naNet(#A=1)具有更好的性能,即上表中的38.4%比下表中的37.0%。
这些结果表明,在传统的基于IoU的样本选择策略下,每一个位置都需要贴上更多的锚盒。然而,在使用提出的方法之后,会得出相反的结论。
具体地说,所提出的ATSS还将AP上的Retinanet(A=9)提高了0.8%,AP50上的Retinanet(A=1)提高了1.4%,AP75上的Retinanet(A=1)提高了1.1%。
此外,当作者将锚定比例尺或纵横比的数量从3更改为1时,结果几乎不变。换言之,只要正确选择正样本,无论在每个位置平铺多少锚,结果都是相同的。因此最后结论是:在新提出的方法下,每个位置铺设多个锚是一项费力的工作,需要进一步研究以发现每个位置多个锚的正确作用。
computerVision
计算机视觉战队
● 扫码关注,回复:ATTS ●
获取原文和源码下载链接
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

——————————往期推荐——————————
CVPR2020 | 超越MobileNetV3的轻量级网络(文末论文下载) 2020-03-09