
一、YOLO v3简介
YOLO v3可以说是当前目标检测算法的集大成者,速度和精度都达到了不错的水准。不了解的同学可以看一下吴恩达的深度学习中有关YOLO的讲解,然后在读一下这个博客,写的很详细。
最近一直热衷于AI研习社的比赛,对是新手练习实操很友好。在这里取得了一些不错的排名,比赛结束不仅达到比赛要求分数的参赛者可以获得一定数量的奖金,官方还会放出排名优秀者的源码,真是太贴心了。在此安利一波。下图是我的比赛收益情况,由于本人时间有限,而且跑模型时间太过漫长,所以并没有太过投入,主要目的是动手实践,如果有感兴趣的朋友,可以一起组队参赛,共同进步。

二、本次比赛简介
本次比赛介绍链接:https://www.yanxishe.com/blogDetail/14905
比赛地址:https://god.yanxishe.com/12
简介
训练集共6057张图片,包含工地照片、某大学监控视频图片、普通场景照片
任务:正确识别图片中人物是否佩戴安全帽
结果文件如下所示:
第一个字段位:测试集图片ID
第二个字段:图片种佩戴安全帽人员数量
第三个字段:图片中没有佩戴安全帽人员数量

四、YOLO v3训练详解
4.1 运行环境
- ubuntu18.04
- Python==3.7
- pytorch==1.3
- 显卡:1060-6G
4.2 训练详解
首先下载github上的yolo源码,然后从比赛链接下载数据集。
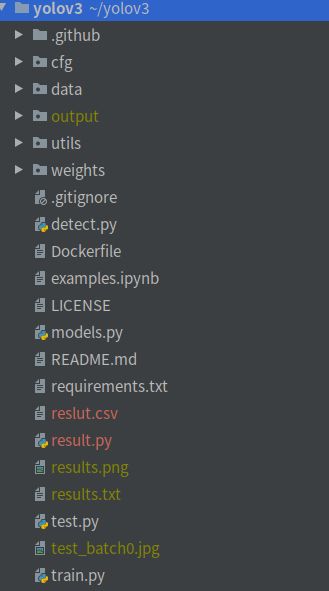
源码大体上上图是这样的,稍有不同也没关系,因为有些文件是我训练时生成的,有些是我自己添加的,后面都会介绍到。

下载下来的数据集只有label、test、train三个文件夹。剩下的文件同样或者添加的或者生成的,后面会介绍。
- 第一步:
先看一下训练介绍:https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data
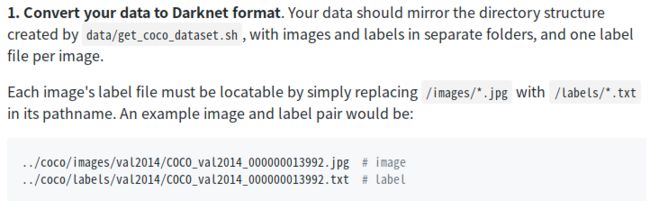
该教程要求把数据放在主目录下的coco文件夹下,图片和文本按此路径以及格式放置。
好了,现在我们在主目录创建文件夹coco,然后点开,再分别创建imges>val2014,labels>val2014,
将下载下来的train文件夹里的图片放入images>val2014里面。
-
第二步:

由于我们数据集的labels是xml文件类型,而此工程要求的是txt格式的label,所以需要进行转换。
在下载的数据集文件夹里创建voc_label.py,写入一下代码,运行得到一个labels文件夹,里面包含了txt格式的标签文件。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=['train', 'val'] #替换为自己的数据集
classes = ["person", "hat"] #修改为自己的类别
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('label/new_%s.xml'%(image_id))
out_file = open('labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels'):
os.makedirs('labels')
image_ids = open('%s.txt'%(image_set)).read().strip().split()
list_file = open('%s.txt'%(image_set), 'w')
for image_id in image_ids:
list_file.write('train/%s.jpg\n'%(image_id))
convert_annotation(image_id)
list_file.close()
最后,labels里面的文本复制入labels>val2014里面。至此我们的数据算准备好了。
-
第三步:
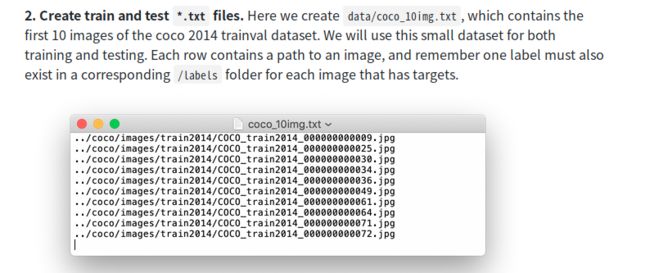
讲train文件夹的数据划分测试集和验证集,在train文件夹同级下创建train_val.py(如图2),具体代码如下。
import os
import random
train_percent = 0.8
xmlfilepath = 'label'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
train_num = int(num * train_percent)
train = random.sample(list, train_num)
ftrain = open('train.txt', 'w')
fval = open('val.txt', 'w')
for i in list:
name = total_xml[i].split('_')[-1][:-4]
name = '../coco/images/val2014/' + name + '.jpg' + '\n'
if i in train:
ftrain.write(name)
else:
fval.write(name)
ftrain.close()
fval.close()
运行后会得到trian.txt和val.txt。将他们放到yolov3目录的data文件夹创建Imagesets文件夹,将此两个文件拷贝进去。
- 第四步
在data文件夹下再创建hat.names和hat.data文件,分别写入如下所示:
hat.names
no_hat
hat
hat.data
classes=2
train=./data/ImageSets/train.txt
valid=./data/ImageSets/val.txt
names=data/hat.names
backup=backup/
eval=coco
这个数据集只有两个类别戴安全帽hat和没带安全帽no_hat。
-
第五步
更改yolov3/cfg下的yolov3-spp.cfg配置文件。当然如果对精度要求不高,却速度有需求可以更改yolov3-tiny.cfg的配置,这是一个轻量级的yolo模型。

如上图所示,将filters该成21,即3×(calsses+4+1),classes改为2。
- 第六步
万事俱备,终于开始训练了!
运行:python train.py --data data/hat.data --cfg cfg/yolov3-spp.cfg
另外可以根据需要更改在train.py里自定义差参数,例如:LR, LR scheduler, optimizer, augmentation,settings, multi_scale settings等等。根据自己显存大小适当调整batch_size。

停止后继续训练可以在上面的命令后面添加--resume
4.3 测试
训练完成后,将数据集中test文件夹的图片拷贝到yolov3/data/samples中,运行:
python detect.py --weights weights/best.pt --data data/hat.data
断断续续训练了大概一天时间。效果还可以,但是在小目标上还是存在漏检、误检的情况。




更新:截止到2019.12.17,排名稳定保持在30/270。
