网络模型配件 ASPP 学习笔记
目录
Motivation
Dilated Convolution
Atrous Spatial Pyramid Pooling
ASPP空洞卷积主要用于对图像或视频进行Segmentation,由于在传统的卷积神经网络模型中,下采样来扩大感受野,抽象化特征信息,对于高等级的图像处理任务,例如图像分类任务有很大的帮助,但对于需要输出一个和输入等分辨率的预测图像的Segmentation任务来说,反而无益。
-
Motivation
用现有的卷积神经网络去做Segmentation任务,存在两个关键的问题:
-
下采样过程中导致的信息丢失
-
卷积神经网络的空间不变性
下采样过程是为了扩大感受野,使得每个卷积输出都包含较大范围的信息,对于提取抽象化信息有很大帮助,但在这个过程中,图像的分辨率不断下降,包含的信息越来越抽象,而图像的局部信息与细节信息会逐渐丢失,虽然现在也有通过线性插值上采样来恢复分辨率的手段存在,但在这个过程,还是不可避免的会造成信息的损失。
卷积神经网络的空间不变性指的是对于一幅输入图像,不论我们对它进行怎样的空间变换,例如说旋转,它输入网络模型后得到的图像分类结果都是不变的,但对于Segmentation任务来说,如果进行了空间变化,输出的预测图是会发生变化的。
因此,就希望能有一种方法,让我们能够不进行下采样,同样能启到扩大感受野的目的,这就是空洞卷积。
-
Dilated Convolution

如上图,(a)是一个普通的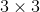 的卷积核,它也可以理解为dilation rate = 1的空洞卷积,是空洞卷积的一个特殊形式;(b)是一个dliation rate = 2的空洞卷积,它在普通的的卷积核的基础上,通过在九个点的周围增加权重为0的空洞点,来将一个的卷积核扩张为
的卷积核,它也可以理解为dilation rate = 1的空洞卷积,是空洞卷积的一个特殊形式;(b)是一个dliation rate = 2的空洞卷积,它在普通的的卷积核的基础上,通过在九个点的周围增加权重为0的空洞点,来将一个的卷积核扩张为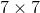 的卷积核,增大了感受野;(c)同理,dilation rate = 4,将的卷积核扩张到了
的卷积核,增大了感受野;(c)同理,dilation rate = 4,将的卷积核扩张到了![]() 。
。
空洞卷积的目的就是在不使用池化与下采样的操作的情况下,启到同样增大感受野的功能,让卷积的每一个输出都拥有较大范围的信息。
-
Atrous Spatial Pyramid Pooling
Atrous Spatial Pyramid Pooling(ASPP),即带有空洞卷积的空间金字塔结构,在Deeplab的各个版本中,都有着广泛的应用。它的主要操作非常简单,就是对于同一幅顶端feature map,使用不同dilation rate的空洞卷积去处理它,将得到的各个结果concat到一起,扩大通道数,最后再通过一个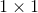 的卷积层,将通道数降到我们想要的数值。
的卷积层,将通道数降到我们想要的数值。
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
# global average pooling : init nn.AdaptiveAvgPool2d ;also forward torch.mean(,,keep_dim=True)
self.mean = nn.AdaptiveAvgPool2d((1, 1))
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
# k=1 s=1 no pad
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net
上面的代码是一个ASPP的pytorch代码实现,对于输出的顶端feature map,将其平行输出到五个模块中,第一个模块经过了平均池化,的卷积层进行通道数变换,最后通过双线性插值恢复分辨率,第二到第五个模块都是空洞卷积,知识dilation rate不同,分别取了1,6,12,18;之后将这五个模块的输出concat到一起,通过一个的卷积层,降低通道数到需要的数值,然后输出。
上图是DeepLabv3+中,作者提出的一个encoder-decoder结构,输出图像在Encoder模块中,通过一个ASPP模块,获得输出,这个输出的通道数一般来说非常大,而且信息会比较抽象(所以才会经过一个的卷积层降低通道数,可以参考之前代码中,降低前后的通道数有着五倍的大小差距),为了Segmentation任务,还需要低层feature map来提供边缘特征信息,于是首先将Encoder模块中的输出进行四倍上采样,然后从DCNN的网络过程中输出一张分辨率一致的feature map(类似跳跃层结构),这张feature map经过的卷积层扩大通道数使之与Encoder的输出一致,然后concat到一起,通过的卷积层和四倍的双线性插值上采样,改善特征,最后输出预测。
在这个模型中,Encoder中使用ASPP结构来提取不同尺度的空间信息,得到一个包含抽象化特征信息的输出,而Decoder阶段通过concat一个低层,包含足量局部信息,边缘信息的feature map来补充细节信息,最后进行预测。