DataSet API所编写的批处理程序跟DataStream API所编写的流处理程序在生成作业图(JobGraph)之前的实现差别很大。流处理程序是生成流图(StreamGraph),而批处理程序是生成计划(Plan)并由优化器对其进行优化并生成优化后的计划(OptimizedPlan)。
计划
计划(Plan)以数据流(dataflow)的形式来表示批处理程序,但它只是批处理程序最初的表示,在一个批处理程序生成作业图之前,计划还会被进行优化以产生更高效的方案。Plan不同于流图(StreamGraph),它以sink为入口,因为一个批处理程序可能存在若干个sink,所以Plan采用集合来存储它:
/**
* A collection of all sinks in the plan. Since the plan is traversed from the sinks to the sources, this
* collection must contain all the sinks.
*/
protected final List> sinks = new ArrayList<>(4);
另外Plan还封装了批处理作业的一些基本属性:jobId、jobName以及defaultParallelism等。
Plan实现了Visitable接口,该接口表示其实现者是可遍历的。Visitable要求实现者完善其accept方法,该方法接收一个Visitor作为遍历器对实现Visitable接口的对象进行遍历。Plan对accept方法的实现是依次对所有的sink进行遍历:
public void accept(Visitor> visitor) {
for (GenericDataSinkBase sink : this.sinks) {
sink.accept(visitor);
}
}
/**
* 遍历图,从所有的data sinks到Sources
* @see Visitable#accept(Visitor)
*/
@Override
public void accept(Visitor> visitor) {
for (GenericDataSinkBase sink : this.sinks) {
sink.accept(visitor);
}
}
代码段中的GenericDataSinkBase也间接实现了Visitable接口,在for循环中会调用它的accept方法。
Visitor接口提供了两个遍历方法,分别是前置遍历的preVisit和用于后置遍历的postVisit方法。Plan在内部实现了获得当前批处理程序最大并行度的MaxDopVisitor遍历器,preVisit会将当前遍历算子的并行度跟已知的最大并行度进行对比,在两者之间取较大值:
public boolean preVisit(Operator visitable) {
this.maxDop = Math.max(this.maxDop, visitable.getParallelism());
return true;
}
获取最大并行度的getMaximumParallelism方法,会实例化该遍历器并调用accept方法进行遍历来获得整个批处理程序的最大并行度:
public int getMaximumParallelism() {
MaxDopVisitor visitor = new MaxDopVisitor();
accept(visitor);
return Math.max(visitor.maxDop, this.defaultParallelism);
}
代码段中的accept方法即为我们之前所展示的那个实现。由此可见accept内部定义了一种遍历模式,而具体遍历过程中要实现的逻辑,取决于对其应用的Visitor。这种设计将遍历模式和遍历逻辑进行了分离。
生成计划源码分析
跟流处理程序中生成流图(StreamGraph)的方式类似,批处理程序中生成计划(Plan)的触发位置也位于执行环境类中。具体而言,是通过createProgramPlan方法来生成Plan的。生成Plan的核心部件是算子翻译器(OperatorTranslation),createProgramPlan方法通过它来”翻译“出计划,核心代码如下:
OperatorTranslation translator = new OperatorTranslation();
Plan plan = translator.translateToPlan(this.sinks, jobName);
根据之前我们对Plan的介绍,可知它是以sink为源头的,所以这里在对计划进行翻译时,也接收的是sink集合。
OperatorTranslation,该类提供了大量的翻译方法来对批处理程序进行翻译。大致来看,它们之间的调用关系如下图:
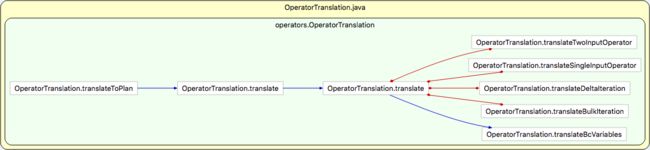
上图中的蓝色带箭头的线表示调用关系,而红色的线表示互相调用的关系,也就是说它们之间存在递归调用
可以看出translateToPlan是这个类对外提供能力的入口方法。translateToPlan的完整实现如下代码段:
public Plan translateToPlan(List> sinks, String jobName) {
List> planSinks = new ArrayList>();
//遍历sinks集合
for (DataSink sink : sinks) {
//将翻译生成的GenericDataSinkBase加入planSinks集合
planSinks.add(
//对每个sink进行”翻译“
translate(sink)
);
}
//以planSins集合构建Plan对象
Plan p = new Plan(planSinks);
p.setJobName(jobName);
return p;
}
上面代码段中的translate方法, 它接收每个需遍历的DataSink对象,然后将其转换成GenericDataSinkBase对象。其实现如下:
private GenericDataSinkBase translate(DataSink sink) {
Operator input = translate(sink.getDataSet());
GenericDataSinkBase translatedSink = sink.translateToDataFlow(input);
return translatedSink;
}
translate方法内部分为两步,第一步是对当前遍历的sink的DataSet进行递归翻译并获得其输入端的Operator对象:
Operator input = translate(sink.getDataSet());
注意这里的Operator对象是Flink core包中的Operator类型,而非批处理API包中的。
批处理API中的几个关键对象DataSet、Operator、DataSource、DataSink之间的继承和关联关系如下图:
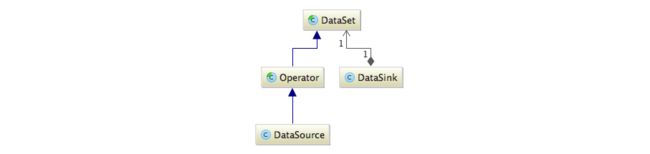
DataSet作为批处理API抽象的同时也是Operator的父类,而Operator则是批处理中所有算子的父类。DataSource和DataSink在哪里都是特殊的,这里也不例外。DataSource继承自Operator,因此它是一种特殊的算子。而DataSink跟上述这三个类不存在继承关系,但它保持了对DataSet的引用,表示跟它关联的数据集。
批处理API模块跟流处理API模块是完全独立的,就算名称相同的类,也不是双方API所共享的。
批处理Java API模块中的operators包不是核心模块中的operators包的扩展与延伸。核心模块中只是提供了一套公共的抽象,而批处理Java API提供的是面向编程接口的抽象。但他们之间并不是毫无联系,因为在translate方法中,会从批处理Java API模块中operators包往核心模块中operators包的转换,对应的转换关系如下:
DataSource -> GenericDataSourceBase (通过DataSource的translateToDataFlow方法)
DataSink -> GenericDataSinkBase(通过DataSink的translateToDataFlow方法)
SingleInputOperator -> Operator (通过SingleInputOperator抽象的translateToDataFlow方法,供子类实现)
TwoInputOperator -> Operator (通过TwoInputOperator抽象的translateToDataFlow方法,供子类实现)
BulkIterationResultSet -> BulkIterationBase (直接构建)
DeltaIterationResultSet -> DeltaIterationBase (直接构建)
translate方法将会在对特定类型的DataSet的翻译中触发对其递归调用,其顺序是从sink开始逆向往source方向进行的,同时会在它们之间建立关系。
这里需要注意的是,这种模式跟流处理中的生成StreamGraph的差别很大。StreamGraph是依靠StreamNode以及StreamEdge来建立节点和边之间的关系,并基于一个统一的StreamGraph数据结构在遍历中收集所有的StreamNode以及StreamEdge。而批处理所生成的Plan却并非是依靠一个中心化的数据结构,在从sink开始进行逆向遍历时,只构建当前算子跟其输入端算子这种临近算子之间的关系,这些关系被封装在各个算子对象中。如果需要串联起它们或者需要访问DAG整体,那么就需要通过遍历器从sink开始依据这种两两之间的关系进行遍历,因此这种模式可以看成是非中心化的。
每翻译一个DataSet会将其加入到一个名为translated的Map中去。translate方法最终返回的是sink紧邻接着的输入端的算子对象,该输入端算子目前还没有跟该sink进行关联。所以,第二步就是调用下面这句将它们建立关系同时将批处理API中的DataSink翻译为核心包中的GenericDataSinkBase表示:
GenericDataSinkBase translatedSink = sink.translateToDataFlow(input);
最终在遍历完sinks集合后产生planSinks集合并以此创建Plan对象。
现在我们将注意力收回到createProgramPlan方法中来,刚刚已经创建完Plan对象,如果配置了自动类型注册,那么Plan将注入一个用于类型注册的遍历器来遍历所有算子并对其类型进行注册:
if (!config.isAutoTypeRegistrationDisabled()) {
plan.accept(new Visitor>() {
private final HashSet> deduplicator = new HashSet<>();
@Override
public boolean preVisit(org.apache.flink.api.common.operators.Operator visitable) {
OperatorInformation opInfo = visitable.getOperatorInfo();
Serializers.recursivelyRegisterType(opInfo.getOutputType(), config, deduplicator);
return true;
}
@Override
public void postVisit(org.apache.flink.api.common.operators.Operator visitable) {}
});
}
完成自动类型注册之后,下一步是将缓存文件注册到Plan对象上:
registerCachedFilesWithPlan(plan);
计划优化
其实在Flink为批处理程序生成计划(Plan)之后,它会对计划进行优化产生优化后的计划(OptimizedPlan),而批处理程序对应的作业图(JobGraph)则是基于OptimizedPlan生成的。OptimizedPlan的生成涉及到优化器相关的内容,更深入的分析请参考“优化器”相关的内容。因为这里的重心是介绍用户程序的执行,而了解OptimizedPlan是分析JobGraph的前提,所以我们会对OptimizedPlan进行简单介绍。
OptimizedPlan主要封装了如下这些属性:
dataSources:SourcePlanNode集合;
dataSinks:SinkPlanNode集合;
allNodes:优化后计划中的所有PlanNode节点集合;
originalProgram:最初未被优化的Plan对象
在ClusterClient的run方法中生成OptimizedPlan:
OptimizedPlan optPlan = getOptimizedPlan(compiler, program, parallelism);1
对getOptimizedPlan方法进行追踪会发现其实生成OptimizedPlan的核心代码就一句:
compiler.compile(p);1
这里的compiler是优化器Optimizer的实例,而参数p是Plan的实例。
参考:
https://blog.csdn.net/yanghua_kobe/article/details/55224512?locationNum=5&fps=1