【ElasticSearch从入门到放弃系列 六】Java客户端操作ElasticSearch
我们知道ES的操作方式有两种,一种是http风格的,一种是tcp风格的,http风格的我们可以通过发送请求去进行索引的增删改查等操作、tcp风格的处理方式则需要我们编码去调用实现,由于ES本身是基于Lucene,而Lucene又是Java的开源搜索引擎,所以我们用Java语言去实现ES的调用。
环境配置
创建一个带有Maven的Java项目,添加Jar包并引入Maven的坐标
<!--指定编译来源为jdk1.9-->
<properties>
<maven.compiler.source>1.9</maven.compiler.source>
<maven.compiler.target>1.9</maven.compiler.target>
</properties>
<!--引入的es和es客户端的版本-->
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<!--引入的日志版本-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<!--引入的单元测试版本-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--引入的json序列化版本-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.6</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
索引库维护
指定一个cluster集群,也就是我们上篇blog创建的elasticsearch-tml集群:为了方便我们每个方法使用client,把client放到公共的before里:
@Before
public void init() throws Exception {
//创建一个Settings对象
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch-tml")
.build();
//创建一个TransPortClient对象,注意连接的端口是9300开头的
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9301))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9302))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9303));
}
这里解释下before的用法:
@BeforeClass – 表示在类中的任意public static void方法执行之前执行
@AfterClass – 表示在类中的任意public static void方法执行之后执行
@Before – 表示在任意使用@Test注解标注的public void方法执行之前执行
@After – 表示在任意使用@Test注解标注的public void方法执行之后执行
@Test – 使用该注解标注的public void方法会表示为一个测试方法
创建索引库
创建索引库的时候,因为有了before的方法,所以创建客户端对象就不需要做了,直接创建一个索引
@Test
public void createIndex() throws Exception {
client.admin().indices().prepareCreate("index_hello")
//执行操作
.get();
//关闭client对象
client.close();
}
创建完成后我们可以在head里看到效果:

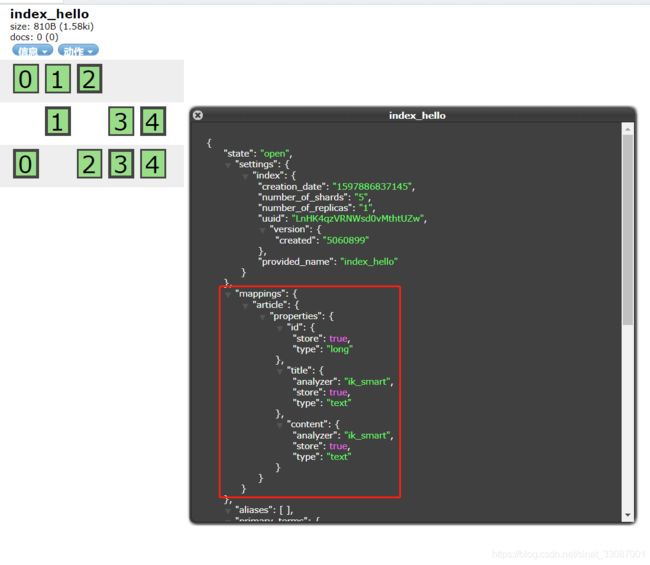
设置Mappings
创建完索引可以直接设置Mappings,例如我们想创建如下结构的Mappings:
{
"article":{
"properties":{
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"ik_smart"
},
"content":{
"type":"text",
"store":true,
"index":true,
"analyzer":"ik_smart"
}
}
}
}
那么需要使用XContentBuilder去构造一个Json对象:
@Test
public void setMappings() throws Exception {
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type","long")
.field("store", true)
.endObject()
.startObject("title")
.field("type", "text")
.field("store", true)
.field("analyzer", "ik_smart")
.endObject()
.startObject("content")
.field("type", "text")
.field("store", true)
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
//使用client把mapping信息设置到索引库中
client.admin().indices()
//设置要做映射的索引
.preparePutMapping("index_hello")
//设置要做映射的type
.setType("article")
//mapping信息,可以是XContentBuilder对象可以是json格式的字符串
.setSource(builder)
//执行操作
.get();
//关闭链接
client.close();
}
这样在索引里就能看到我们创建的Mappings了:
添加文档
添加文档同样很简单,首先构造一个文档对象,然后定位到索引和type的位置,设置好文档id,直接塞进去就好了:文档对象以type为基本单位:
public class Article {
private long id;
private String title;
private String content;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
构造好的对象用于添加属性内容以及转为Json:
@Test
public void testAddDocument2() throws Exception {
//创建一个Article对象
Article article = new Article();
//设置对象的属性
article.setId(2l);
article.setTitle("tml第二个测试");
article.setContent("tml第二个测试内容");
//把article对象转换成json格式的字符串。
ObjectMapper objectMapper = new ObjectMapper();
String jsonDocument = objectMapper.writeValueAsString(article);
System.out.println(jsonDocument);
//使用client对象把文档写入索引库
client.prepareIndex("index_hello","article", "2")
.setSource(jsonDocument, XContentType.JSON)
.get();
//关闭客户端
client.close();
}
可以从head里查看文档的创建效果:

我们批量创建几个文档,便于下边文档搜索时验证:

使用ES客户端搜索
使用ES客户端搜索同样我们验证之前的几种搜索方式:id查询、term查询以及query查询,同时再尝试下分页查询和查询的高亮显示。为了方便起见,我们把构造查询对象的公共代码提出来:
private void search(QueryBuilder queryBuilder) throws Exception {
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
//每页显示的行数
.setSize(5)
.get();
//取查询结果
SearchHits searchHits = searchResponse.getHits();
//取查询结果的总记录数
System.out.println("查询结果总记录数:" + searchHits.getTotalHits());
//查询结果列表
Iterator<SearchHit> iterator = searchHits.iterator();
while(iterator.hasNext()) {
SearchHit searchHit = iterator.next();
//打印文档对象,以json格式输出
System.out.println(searchHit.getSourceAsString());
//取文档的属性
System.out.println("-----------文档的属性");
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
}
//关闭client
client.close();
}
根据id搜索
依据ID查询时,只需要给查询对象添加对应的id列表:
@Test
public void testSearchById() throws Exception {
//创建一个client对象
//创建一个查询对象
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("2", "8");
search(queryBuilder);
}
我们可以取到这两条记录:

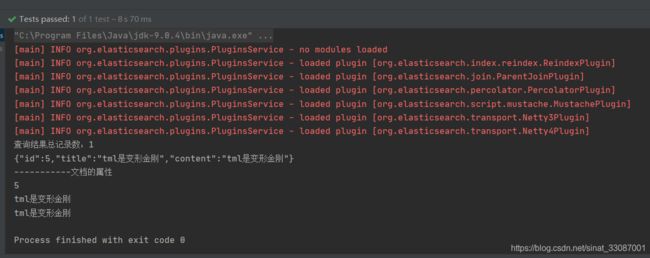
根据Term查询
依据terms查询,因为我们使用了ik分词,所以应该能得到较好的分词效果:
@Test
public void testQueryByTerm() throws Exception {
//创建一个QueryBuilder对象
//参数1:要搜索的字段
//参数2:要搜索的关键词
QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "变形金刚");
//执行查询
search(queryBuilder);
}
QueryString查询方式
带分析的查询方式,输入一个查询语句,先分割再查询:
@Test
public void testQueryStringQuery() throws Exception {
//创建一个QueryBuilder对象
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("tml是很帅的变形金刚")
.defaultField("title");
//执行查询
search(queryBuilder);
}
可以看到6个document都被搜索出来了,但因为分页设置了显示5条,只显示5个记录。
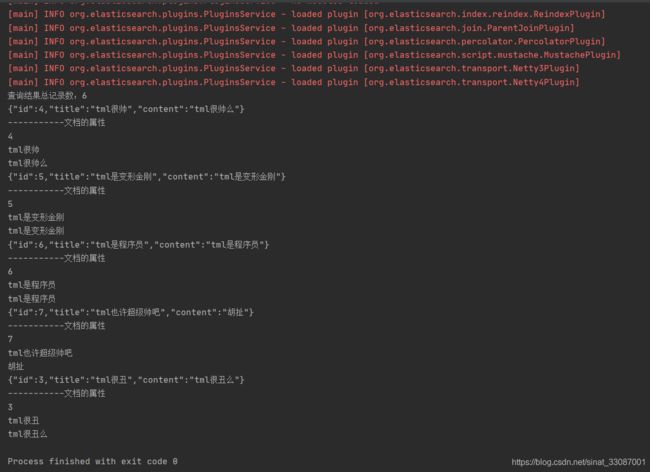
分页搜索
我们调整分页显示为分页显示10条记录,就可以看到上述搜索能被全部显示出来:
private void search(QueryBuilder queryBuilder) throws Exception {
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
//每页显示的行数
.setSize(10)
.get();
//取查询结果
SearchHits searchHits = searchResponse.getHits();
//取查询结果的总记录数
System.out.println("查询结果总记录数:" + searchHits.getTotalHits());
//查询结果列表
Iterator<SearchHit> iterator = searchHits.iterator();
while(iterator.hasNext()) {
SearchHit searchHit = iterator.next();
//打印文档对象,以json格式输出
System.out.println(searchHit.getSourceAsString());
//取文档的属性
System.out.println("-----------文档的属性");
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
}
//关闭client
client.close();
}
再次执行查询:
@Test
public void testQueryStringQuery() throws Exception {
//创建一个QueryBuilder对象
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("tml是很帅的变形金刚")
.defaultField("title");
//执行查询
search(queryBuilder);
}
此时可以看到,6篇文档都被检索出来了:
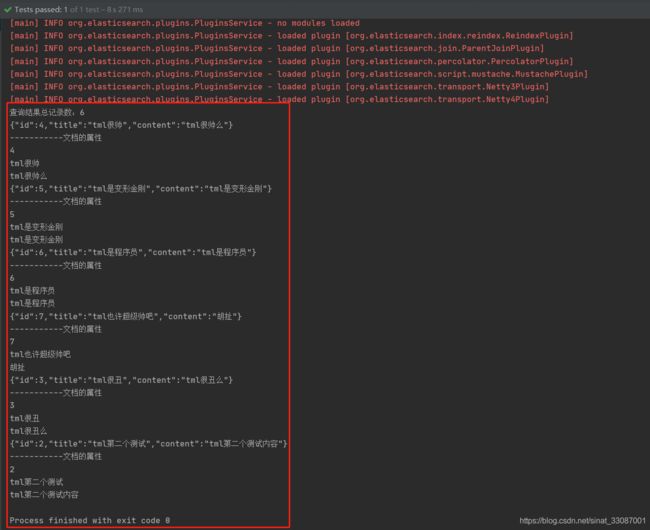
高亮显示
高亮显示的时候,可以重新设置下querybuilder:
private void search(QueryBuilder queryBuilder, String highlightField) throws Exception {
HighlightBuilder highlightBuilder = new HighlightBuilder();
//高亮显示的字段
highlightBuilder.field(highlightField);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
//每页显示的行数
.setSize(5)
//设置高亮信息
.highlighter(highlightBuilder)
.get();
//取查询结果
SearchHits searchHits = searchResponse.getHits();
//取查询结果的总记录数
System.out.println("查询结果总记录数:" + searchHits.getTotalHits());
//查询结果列表
Iterator<SearchHit> iterator = searchHits.iterator();
while(iterator.hasNext()) {
SearchHit searchHit = iterator.next();
//打印文档对象,以json格式输出
System.out.println(searchHit.getSourceAsString());
//取文档的属性
System.out.println("-----------文档的属性");
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println("************高亮结果");
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
System.out.println(highlightFields);
//取title高亮显示的结果
HighlightField field = highlightFields.get(highlightField);
Text[] fragments = field.getFragments();
if (fragments != null) {
String title = fragments[0].toString();
System.out.println(title);
}
}
//关闭client
client.close();
}
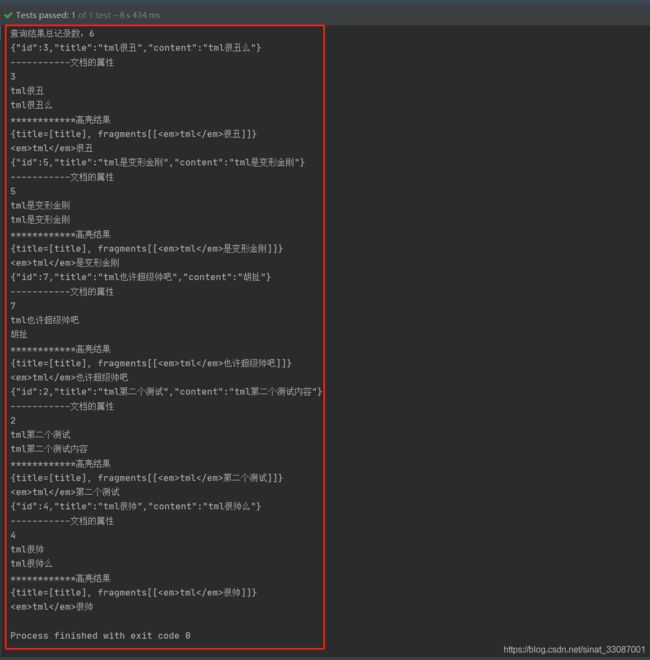
然后再进行高亮查询:
@Test
public void testQueryStringQueryHeight() throws Exception {
//创建一个QueryBuilder对象
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("女护士")
.defaultField("title");
//执行查询
search(queryBuilder, "title");
}
可以看到打印出来的高亮结果