部署Scrapy项目到腾讯云服务器
前言
打算把写完的爬虫项目放到服务器上定时运行,然后了解到有scrapyd这个方便管理爬虫,于是这篇文章的指向是在腾讯云服务器上运行scrapd,然后把我们的爬虫上传到scrapyd,使得scrapyd可以管理爬虫项目(注:没有通过文件传输工具把scrapy爬虫项目的文件上传到服务器,额,我是这么理解的,但是是通过scrapyd上传的egg)
操作
服务器是刚买的腾讯云的CentOS 7系统,没有云数据库,所以后面自己搭mysql,有python2但是没有python3
第一步
在本机下载scrapyd-client:
对于windows系统,建议不要用pip install scrapyd-client去安装scrapyd-client,会出现,scrapyd-deploy不是内部或外部命令,因为scrapyd-deploy不能被windows执行
应当直接去github上下载并解压安装包后,进入解压后的目录下,执行
python setup.py install
进行安装,若已经用pip安装了的,先卸载Scrapyd-client
pip list
pip uninstall scrapyd-client
第二步
登陆腾讯云服务器里面进行相应的python和相关库安装(结合几篇博文的命令如下)
# 进入home目录
cd ~
# 安装相关库
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
yum -y install gcc
yum install -y libffi-devel zlib1g-dev
yum install zlib* -y
# 下载python3.6安装包
wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tgz
# 创建一个文件夹
mkdir /usr/local/python3
# 解压安装包
tar -zxvf Python-3.6.8.tgz
# 进入解压后的目录
cd Python-3.6.8
# 配置,使安装路径为/usr/local/python3.6
# 第一个指定安装的路径,不指定的话,安装过程中可能软件所需要的文件复制到其他不同目录,删除软件很不方便,复制软件也不方便.
# 第二个可以提高python10%-20%代码运行速度. 参考:https://blog.csdn.net/whatday/article/details/98053179
# 第三个是为了安装pip需要用到ssl,后面报错会有提到.
./configure --prefix=/usr/local/python3 --enable-optimizations --with-ssl
# 编译,安装 时间较长
make && make install
# 创建软连接
ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3
# 安装scrapyd,scrapyd-client和scrapy
pip3 install scrapyd
pip3 install scrapy
pip3 install scrapyd-client
# 更新pip
pip3 install --upgrade pip
# 安装项目需要的库
pip install requests
使得外网能够访问服务器IP,修改如下文件
# 查找default_scrapyd.conf路径
find / -name default_scrapyd.conf
# 修改default_scrapyd.conf,使外网IP可以访问
vi /usr/local/python3/lib/python3.6/site-packages/scrapyd/default_scrapyd.conf
default_scrapyd.conf文件里的bind_address修改为
bind_address = 0.0.0.0
然后进入腾讯云控制台,点击安全组—>再点击新建
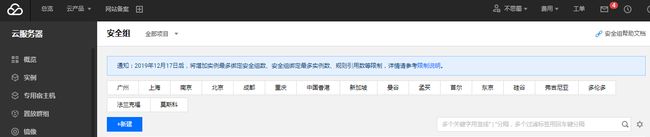

在新建的安全组点击修改规则然后添加规则

保存后返回服务器实例页面,选中实例,点击更多操作,加入安全组,添加刚才创建安全组

此时用 '/usr/local/python3.6/bin/scrapyd'启动scrapyd,加上nohup&则在后台启动运行
# 查看scrapy
'/usr/local/python3/bin/scrapy'
# 启动scrapyd
'/usr/local/python3/bin/scrapyd'
# 在后台启动运行scrapyd
nohup '/usr/local/python3/bin/scrapyd' &
启动scrapyd成功

后台运行scrapyd

[root@VM_0_14_centos ~]# nohup '/usr/local/python3/bin/scrapyd' &
[1] 25485
[root@VM_0_14_centos ~]# nohup: ignoring input and appending output to ‘nohup.out’
通过服务器外网IP:6800可以在浏览器里看到如下页面

第三步
服务器端安装Mysql 5.7
一、配置yum源
1.下载mysql源安装包
在MySQL官网中下载YUM源rpm安装包:http://dev.mysql.com/downloads/repo/yum/
本次下载目录为:/home/目录,因此进入:cd /home
执行下载命令:
wget https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm
2.安装mysql源
下载完成后使用下面命令安装源:
yum localinstall mysql80-community-release-el7-1.noarch.rpm
3.检查是否安装成功
yum repolist enabled | grep "mysql.*-community.*"
4.修改安装版本
默认安装的mysql版本是8.0,需要安装mysql5.7,需要修改/etc/yum.repos.d/mysql-community.repo源,改变默认安装的mysql版本
vi /etc/yum.repos.d/mysql-community.repo
将5.7源的enabled=0改成enabled=1,将8.0的enabled=1改成enabled=0即可
二、安装mysql
直接使用命令:
yum install mysql-community-server
三、启动mysql服务
1.启动
systemctl start mysqld
或者
service mysqld start
2.查看启动状态
systemctl status mysqld
或者
service mysqld status
3.设置开机启动
systemctl enable mysqld
systemctl daemon-reload
四、配置及部分命令
1.修改登录密码
mysql安装完成之后,在/var/log/mysqld.log文件中给root生成了一个默认密码,通过下面的方式找到root默认密码,然后登录mysql进行修改:
grep 'temporary password' /var/log/mysqld.log
密码就是root@localhost冒号后面的全部字符
2.本地MySQL客户端登录
mysql -uroot -p
密码是上一步查询出来的,输入后回车
然后修改密码:
set password for 'root'@'localhost'=password('xxxxxxxx');
注意:mysql5.7默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位。否则会提示ERROR 1819 (HY000): Your password does not satisfy the current policy requirements错误
通过msyql环境变量可以查看密码策略的相关信息(执行这一步需要先修改默认密码,即执行完上一步修改才可以,否则会报错:ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.)
show variables like '%password%';
validate_password_policy:密码策略,默认为MEDIUM策略
validate_password_dictionary_file:密码策略文件,策略为STRONG才需要
validate_password_length:密码最少长度
validate_password_mixed_case_count:大小写字符长度,至少1个
validate_password_number_count :数字至少1个
validate_password_special_char_count:特殊字符至少1个
上述参数是默认策略MEDIUM的密码检查规则
修改密码策略:
在/etc/my.cnf文件添加validate_password_policy配置,指定密码策略:
选择0(LOW),1(MEDIUM),2(STRONG)其中一种,选择2需要提供密码字典文件
validate_password_policy=0
如果不需要密码策略,添加my.cnf文件中添加如下配置禁用即可:
validate_password = off
重新启动mysql服务使配置生效:
systemctl restart mysqld
3.添加远程登录用户
默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,必须修改root允许远程连接,或者添加一个允许远程连接的帐户
修改root用户远程访问权限:
选择 mysql 数据库:
use mysql;
在 mysql 数据库的 user 表中查看当前 root 用户的相关信息:
select host, user from user;
查看表格中 root 用户的 host,默认应该显示的 localhost,只支持本地访问,不允许远程访问
授权 root 用户的所有权限并设置远程访问
update user set host='%' where user ='root';
然后使用下面命令使修改生效:
flush privileges;
4.修改默认编码方式
mysql8.0默认编码方式为utf8mb4,因此使用时不需要修改,可使用如下命令查看:
SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
如果需要修改其他编码方式,方法有很多,以下仅为举例
比如需要修改为utf8mb4,可以使用如下方式:
修改mysql配置文件my.cnf(windows为my.ini)
my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
重启mysql即可
collation_connection 、collation_database 、collation_server是什么没关系,但必须保证以下这几个变量必须是utf8mb4:
character_set_client (客户端来源数据使用的字符集)
character_set_connection (连接层字符集)
character_set_database (当前选中数据库的默认字符集)
character_set_results (查询结果字符集)
character_set_server (默认的内部操作字符集)
数据库连接参数中:
characterEncoding=utf8会被自动识别为utf8mb4,也可以不加这个参数,会自动检测
而autoReconnect=true是必须加上的
第四步
部署爬虫到服务器
1.进入本地项目根目录,用scrapyd-deploy -l生成scrapy.cfg(最新的scrapy项目创建后就自带,无需再生成),并且修改该文件
[settings]
default = LVideoSpider.settings
[deploy:busishu] # busishu 是自己给定义的host名称
url = http://公网IP:6800/
project = LVideoSpider # project名称就是上面.settings的前一部分
2.部署爬虫到服务器
本地进入scrapy.cfg文件所在目录,执行scrapyd-deploy
scrapyd-deploy busishu -p LVideoSpider
成功后,服务器会返回一个json
但是,我没成功,因为我的scrapy爬虫配置的MySQL连接信息,连接不上服务器的数据库,配置好后服务器端的数据库中却没有对应的表
Server response (200):
{"node_name": "VM_0_14_centos", "status": "error", "message": "Traceback (most recent call last):\n File \"/usr/local/python3/lib/python3.6/runpy.py\", line 1
93, in _run_module_as_main\n \"__main__\", mod_spec)\n File \"/usr/local/python3/lib/python3.6/runpy.py\", line 85, in _run_code\n exec(code, run_global
s)\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapyd/runner.py\", line 40, in \n main()\n File \"/usr/local/python3/lib/python3.6/si
te-packages/scrapyd/runner.py\", line 37, in main\n execute()\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/cmdline.py\", line 145, in exe
cute\n cmd.crawler_process = CrawlerProcess(settings)\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/crawler.py\", line 267, in __init__\n
super(CrawlerProcess, self).__init__(settings)\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/crawler.py\", line 145, in __init__\n self
.spider_loader = _get_spider_loader(settings)\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/crawler.py\", line 347, in _get_spider_loader\n
return loader_cls.from_settings(settings.frozencopy())\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/spiderloader.py\", line 61, in from_se
ttings\n return cls(settings)\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/spiderloader.py\", line 25, in __init__\n self._load_all_sp
iders()\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/spiderloader.py\", line 47, in _load_all_spiders\n for module in walk_modules(name):
\n File \"/usr/local/python3/lib/python3.6/site-packages/scrapy/utils/misc.py\", line 73, in walk_modules\n submod = import_module(fullpath)\n File \"/usr
/local/python3/lib/python3.6/importlib/__init__.py\", line 126, in import_module\n return _bootstrap._gcd_import(name[level:], package, level)\n File \"\", line 994, in _gcd_import\n File \"\", line 971, in _find_and_load\n File \"\", line 955, in _find_and_load_unlocked\n File \"\", line 656, in _load_unlocked\n File \"\"
, line 626, in _load_backward_compatible\n File \"/tmp/LVideoSpider-1579927825-mwhuhl90.egg/LVideoSpider/spiders/lvideo.py\", line 15, in \n File \"/
tmp/LVideoSpider-1579927825-mwhuhl90.egg/LVideoSpider/spiders/lvideo.py\", line 18, in LvideoSpider\n File \"/tmp/LVideoSpider-1579927825-mwhuhl90.egg/LVideoS
pider/spiders/source_data.py\", line 13, in get_source_data\n File \"/usr/local/python3/lib/python3.6/site-packages/pymysql/__init__.py\", line 94, in Connect
\n return Connection(*args, **kwargs)\n File \"/usr/local/python3/lib/python3.6/site-packages/pymysql/connections.py\", line 325, in __init__\n self.con
nect()\n File \"/usr/local/python3/lib/python3.6/site-packages/pymysql/connections.py\", line 599, in connect\n self._request_authentication()\n File \"/u
sr/local/python3/lib/python3.6/site-packages/pymysql/connections.py\", line 861, in _request_authentication\n auth_packet = self._read_packet()\n File \"/u
sr/local/python3/lib/python3.6/site-packages/pymysql/connections.py\", line 684, in _read_packet\n packet.check_error()\n File \"/usr/local/python3/lib/pyt
hon3.6/site-packages/pymysql/protocol.py\", line 220, in check_error\n err.raise_mysql_exception(self._data)\n File \"/usr/local/python3/lib/python3.6/site
-packages/pymysql/err.py\", line 109, in raise_mysql_exception\n raise errorclass(errno, errval)\npymysql.err.InternalError: (1049, \"Unknown database 'lvid
eo'\")\n"}
所以我尝试在服务器端的数据库创建爬虫所需要的表
# 新建数据库lvideo
create database lvideo default character set utf8mb4 collate utf8mb4_general_ci;
# 使用该数据库
use lvideo;
# 创建三表
CREATE TABLE `video_source` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`domin` varchar(128) NOT NULL,
`name` varchar(128) NOT NULL,
`type` int(10) unsigned NOT NULL,
`is_effect` int(10) unsigned NOT NULL,
`format_page` varchar(512) NOT NULL,
`created_time` datetime(6) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `video_videoinfo` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(512) NOT NULL,
`alias` varchar(512) NOT NULL,
`cover_url` varchar(512) NOT NULL,
`director` varchar(512) NOT NULL,
`actor` varchar(1024) NOT NULL,
`first_type` varchar(256) NOT NULL,
`second_type` varchar(256) NOT NULL,
`region` varchar(256) NOT NULL,
`update_time` varchar(128) NOT NULL,
`nums` int(10) unsigned NOT NULL,
`release_time` varchar(64) NOT NULL,
`intro` longtext NOT NULL,
`source` varchar(128) NOT NULL,
`created_time` varchar(128) NOT NULL,
`remark` varchar(512) NOT NULL,
`pv` int(10) unsigned NOT NULL,
`uv` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `video_videoinfo_name_3495f1c0` (`name`),
KEY `video_videoinfo_alias_0b3eabbd` (`alias`),
KEY `video_videoinfo_release_time_8393c554` (`release_time`),
KEY `update_time` (`update_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=38974 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `video_videolink` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(512) NOT NULL,
`link` varchar(512) NOT NULL,
`number` varchar(128) NOT NULL,
`is_new` int(10) unsigned NOT NULL,
`status` int(10) unsigned NOT NULL,
`source` varchar(128) NOT NULL,
`created_time` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`) USING BTREE,
KEY `link` (`link`) USING BTREE,
KEY `number` (`number`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=235037 DEFAULT CHARSET=utf8mb4;
# 插入起始所需的数据源
insert into video_source(`domin`,`name`,`type`,`is_effect`,`format_page`,`created_time`) values('kuyunzy.tv','kuyun',1,1,'http://www.kuyunzy.tv/?m=vod-index-pg-{}.html','2020-01-07 09:07:41.466798');
然后成功再执行命令就成功了
Server response (200):
{"node_name": "VM_0_14_centos", "status": "ok", "project": "LVideoSpider", "version": "1579928601", "spiders": 1}
本地检查爬虫是否部署成功,这里的实际上是你deploy的目标,不是项目名称
scrapyd-deploy -L <host>
若有爬虫成功部署则会返回你部署的项目名称
D:\Python\PycharmProject\LVideoSpider>scrapyd-deploy -L busishu
LVideoSpider
也可以用scrapyd-deploy -l查看
检查在服务器上部署的项目
curl http://<服务器公网IP>:6800/listprojects.json
检查服务器上部署的某个项目的爬虫
curl http://:6800/listspiders.json?project=<项目名称>
删除服务器上部署的项目
curl http://:6800/delproject.json -d project=<项目名称>
第五步
在服务器端操作爬虫
# 运行爬虫
curl http://<公网IP>:6800/schedule.json -d project=<项目名称> -d spider=<爬虫名称>
# 后台运行
nohup curl http://<公网IP>:6800/schedule.json -d project=<项目名称> -d spider=<爬虫名称> &
# 停止爬虫
curl http://<公网IP>:6800/cancel.json -d project=<项目名称> -d job=
若需要向爬虫传递命令参数和设置DOWNLOAD_DELAY:
curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider -d setting=DOWNLOAD_DELAY=2 -d arg1=val1
# 我的例子,额外传递参数pages=20
curl http://IP:6800/schedule.json -d project=LVideoSpider -d spider=lvideo -d pages=20
![]()

win系统curl需要下载, 然后将解压目录下的bin目录加入path环境变量中即可在windows的命令行使用
第六步
追加使用spiderkeeper来实现爬虫的定时功能
- 在原来的基础上安装以下依赖:
pip3 install scrapy_redis
pip3 install spiderkeeper
前面已经修改过可以使外网访问到我们的IP,但是还需要开通另一个安全组入口配置5000(spiderkeeper)
运行spiderkeeper(我这里还真奇了怪了,很多人的博客都说直接输入spiderkeeper就能启动,我试了半天啥都没有,最后跟前面的一样加上所在的路径才成功启动,难道我pip3安装了个鬼?)
'/usr/local/python3/bin/spiderkeeper'
# 后台运行
[root@VM_0_14_centos ~]# nohup '/usr/local/python3/bin/spiderkeeper' &
[1] 17355
[root@VM_0_14_centos ~]# nohup: ignoring input and appending output to ‘nohup.out’
要想直接输入spiderkeeper就运行,需要创建软连接,scrapyd也是同理:
ln -s /usr/local/python3/bin/spiderkeeper /usr/bin/spiderkeeper
之后直接输入spiderkeeper就能运行spiderkeeper了!!!
- 接着我们访问http://IP:5000,账号密码初始都是
admin
接着在本地项目根目录下给爬虫打包
scrapyd-deploy --build-egg output.egg
D:\Python\PycharmProject\LVideoSpider>scrapyd-deploy --build-egg output.egg
Writing egg to output.egg
然后在spiderkeeper可视化界面点击creat project,点击创建,跳到deploy界面,上传output.egg文件,点击submit
若出现deploy success说明部署成功
部署完后,点击Dashboard这个按钮,再选择你创建的项目,然后点击RunOnce按钮创建爬虫
点击后会出现

其中Args可以让你输入传给爬虫的参数,这里我传入的参数就是爬取的页数,其他选项一般不用动,然后点击CREATE,刷新页面就可以看到你的爬虫正在运行了
- Periodic Jobs
定时任务,点击右上角的addjobs后可以添加任务,除了之前有的选项之后还可以设置每个月/每星期/每天/每小时/每分钟 的定时爬虫
m h dom mon dow
0 0/4 * * * # 每隔4小时运行一次
- Running Stats
查看爬虫的运行情况,只能显示时间段爬虫的存活情况
- Manage
如果要删除任务可以在这里删除
总结
现在scrapyd一直在服务器后台运行着,只要本地执行命令就可以把本地的scrapy项目部署上去,然后可以在cmd命令行或者服务器端输入curl命令来启动爬虫等操作
加入spiderkeeper后,spiderkeeper同时运行在服务器端,只要把本地项目生成的egg上传到spiderkeeper,就可以在spiderkeeper这个可视化界面上运行爬虫,设置定时爬取等
参考
部署scrapy项目到腾讯云服务器,并操作爬虫
centos7中安装python3
python3 编译优化 --enable-shared --enable-optimizations
腾讯云Centos7 安装Mysql5.7
Scrapyd documentation
Windows安装curl及基本命令
在linux下安装并运行scrapyd
SpiderKeeper的使用
m h dom mon dow