狄利克雷分布、采样方法、主题模型
Gamma函数
- 公式
Γ ( x ) = ∫ 0 + ∞ e − t t x − 1 d t \Gamma(x)=\int_0^{+\infty} e^{-t} t^{x-1}dt Γ(x)=∫0+∞e−ttx−1dt - 性质
Γ ( x + 1 ) = x Γ ( x ) \Gamma(x+1)=x\Gamma(x) Γ(x+1)=xΓ(x)
Γ ( n ) = ( n − 1 ) ! \Gamma(n)=(n-1)! Γ(n)=(n−1)!
Beta函数
- 公式
B ( m , n ) = ∫ 0 1 x m − 1 ( 1 − x ) n − 1 d x \Beta(m,n)=\int_0^1 x^{m-1}(1-x)^{n-1}dx B(m,n)=∫01xm−1(1−x)n−1dx - 性质
B ( m , n ) = Γ ( m ) Γ ( n ) Γ ( m + n ) \Beta(m,n)=\frac{\Gamma(m)\Gamma(n)}{\Gamma(m+n)} B(m,n)=Γ(m+n)Γ(m)Γ(n)
二项分布
-
假设在玩CS游戏,你拿着狙击枪,敌人出现你打中敌人的概率是P,打不中敌人的概率是1-P,那么敌人第一次出现你没打中,而第二次出现你打中的概率是(1-P)P。如果敌人出现了n词,而你打中了其k次,而不确定具体是哪k次,这样从n次中任取k次的次数是 C n k C_n^k Cnk,而这不确定k次打中敌人的概率是 C n k p k ( 1 − p ) n − k C_n^kp^k(1-p)^{n-k} Cnkpk(1−p)n−k,通过这个例子可以得知二项分布的概率:
f ( k ; n , p ) = C n k p k ( 1 − p ) n − k f(k;n,p)=C_n^kp^k(1-p)^{n-k} f(k;n,p)=Cnkpk(1−p)n−k
Beta分布
- 定义
f ( x ; a , β ) = x a − 1 ( 1 − x ) β − 1 ∫ 0 1 u a − 1 ( 1 − u ) β − 1 d u f(x;a,\beta)=\frac{x^{a-1}(1-x)^{\beta-1}}{\int_0^1 u^{a-1}(1-u)^{\beta -1} du} f(x;a,β)=∫01ua−1(1−u)β−1duxa−1(1−x)β−1
= x a − 1 ( 1 − x ) β − 1 B ( a , β ) =\frac{x^{a-1}(1-x)^{\beta -1}}{\Beta(a,\beta)} =B(a,β)xa−1(1−x)β−1
= Γ ( a + β ) Γ ( a ) Γ ( β ) x a − 1 ( 1 − x ) β − 1 =\frac{\Gamma(a+\beta)}{\Gamma(a)\Gamma(\beta)}x^{a-1}(1-x)^{\beta -1} =Γ(a)Γ(β)Γ(a+β)xa−1(1−x)β−1
- 期望
E ( p ) = ∫ 0 1 p a ( 1 − p ) β − 1 d p Γ ( a , β ) = B ( a + 1 , β ) B ( a , β ) E(p)=\int_0^1 \frac {p^a(1-p)^{\beta -1}dp}{\Gamma(a,\beta)}=\frac{\Beta(a+1,\beta)}{\Beta(a,\beta)} E(p)=∫01Γ(a,β)pa(1−p)β−1dp=B(a,β)B(a+1,β)
= Γ ( a + 1 ) Γ ( β ) Γ ( a + β + 1 ) Γ ( a + β ) Γ ( a ) Γ ( β ) =\frac{\Gamma(a+1)\Gamma(\beta)}{\Gamma(a+\beta+1)}\frac{\Gamma(a+\beta)}{\Gamma(a)\Gamma(\beta)} =Γ(a+β+1)Γ(a+1)Γ(β)Γ(a)Γ(β)Γ(a+β)
= a a + β =\frac{a}{a+\beta} =a+βa
-
相似分布
如果 p ⃗ 服 从 分 布 D i r ( t ⃗ ∣ a ⃗ ) \vec p 服从分布 Dir(\vec t | \vec a) p服从分布Dir(t∣a)则可证明,
E ( p ⃗ ) = ( a 1 ∑ i a i , a 2 ∑ i a i , ⋯ ) E(\vec p)=\big( \frac{a_1}{\sum_i a_i},\frac{a_2}{\sum_i a_i},\cdots \big) E(p)=(∑iaia1,∑iaia2,⋯) -
多项分布
设投掷n次骰子,这个骰子共有六种结果,且1点出现概率为 p 1 p_1 p1,2点出现概率为 p 2 , ⋯ p_2,\cdots p2,⋯多项分布给出了在n次实验中,骰子1点出现 x 1 x_1 x1次,2点出现 x 2 x_2 x2次,3点出现 x 3 x_3 x3次, ⋯ \cdots ⋯,6点出现 x 6 x_6 x6次,这个结果组合的概率为:
n ! x 1 ! x 2 ! ⋯ x k ! p 1 x 1 p 2 x 2 ⋯ p k x k \frac{n!}{x_1!x_2!\cdots x_k!}p_1^{x_1}p_2^{x_2}\cdots p_k^{x_k} x1!x2!⋯xk!n!p1x1p2x2⋯pkxk
亦可表示为:
Γ ( ∑ i x i + 1 ) ∏ i Γ ( x i + 1 ) ∏ i p i x i \frac{\Gamma(\sum_i x_i+1)}{\prod_i \Gamma(x_i+1)}\prod_i p_i^{x_i} ∏iΓ(xi+1)Γ(∑ixi+1)i∏pixi
狄利克雷分布
-
狄利克雷分布式beta分布在多项式情况下的情况,也就是多项分布的共轭先验分布,其概率密度如下:
f ( p 1 , p 2 , ⋯ , p k − 1 ∣ a 1 , a 2 , ⋯ , a k ) = 1 Δ ( a ⃗ ) ∏ i = 1 k p a i − 1 f(p_1,p_2,\cdots,p_{k-1}|a_1,a_2,\cdots,a_k)=\frac{1}{\Delta(\vec a)}\prod_{i=1}^kp^{a_i-1} f(p1,p2,⋯,pk−1∣a1,a2,⋯,ak)=Δ(a)1i=1∏kpai−1
其中的 Δ ( a ⃗ ) \Delta(\vec a) Δ(a)计算公式如下:
Δ ( a ⃗ ) = ∏ i = 1 k Γ ( a i ) Γ ( ∑ i a i ) \Delta(\vec a) = \frac {\prod_{i=1}^k \Gamma(a_i)}{\Gamma(\sum_i a_i)} Δ(a)=Γ(∑iai)∏i=1kΓ(ai)
共轭先验分布
-
所谓共轭,知识我们选取一个函数作为似然函数的先验分布,使得后验分布函数和先验分布函数形式一致。比如Beta分布是二项分布的共轭先验概率分布,而狄更斯分布式多项式分布的共轭先验概率分布。
-
参数估计
对于典型的离散型随机变量分布:二项分布、多项分布;典型的连续性随机变量分布:正态分布。他们都可以看作参数分布,因为他们的函数形式被一小部分参数控制,比如正态分布的均值合方差,二项分布事件发生的概率等。因此,给定一堆观测数据集,我们需要有一个解决方案来确定这些参数值的大小,以便能够利用分布模型做密度估计,这就是参数估计。
对于参数估计,一直存在两个学派的不同解决方案。一是频率学派解决方案:通过某些优化准则来选定特定参数值;二是贝叶斯学派方案:假定参数服从一个先验分布,通过观测到的数据,使用被也是理论计算对应的后验分布。先验和后验的选择满足共轭,这些分布都是指数簇分布的例子。
简而言之,假设参数 θ \theta θ也是变量而非常量,而且在做实验前已经服从某个分布,然后现在做新实验去更新这个分布假设。 -
从二项分布到beta分布
二项分布的似然函数
L ( X = s , Y = f ∣ p ) = C n s p s ( 1 − p ) f L(X=s,Y=f|p)=C_n^sp^s(1-p)^f L(X=s,Y=f∣p)=Cnsps(1−p)f
先验分布beta分布
P ( p ∣ a , β ) = p a − 1 ( 1 − p ) β − 1 B ( a , β ) P(p|a,\beta)=\frac{p^{a-1}(1-p)^{\beta -1}}{\Beta(a,\beta)} P(p∣a,β)=B(a,β)pa−1(1−p)β−1
计算后验分布
P ( X = s , Y = f , p ∣ a , β ) = p s + a − 1 ( 1 − p ) f + β − 1 B ( s + a , f + β ) P(X=s,Y=f,p|a,\beta)=\frac{p^{s+a-1}(1-p)^{f+\beta -1}}{\Beta(s+a,f+\beta)} P(X=s,Y=f,p∣a,β)=B(s+a,f+β)ps+a−1(1−p)f+β−1 -
多项分布到Dirichlet分布
同上可以证明多项分布与Dirichlet分布共轭
马尔科夫蒙特卡洛
一、 Inverse CDF
- cdf(累计分布函数)
F ( x ) = ∫ − ∞ x f ( x ) d x F(x)=\int_{-\infty}^xf(x)dx F(x)=∫−∞xf(x)dx
高斯的CDF图形

- 采样
- 求F(x)的反函数 F − 1 ( y ) F^{-1}(y) F−1(y),进而进行采样
- 使用uniform(0,1)获取采样点s,进而获取简单计算 t = F − 1 ( s ) t=F^{-1}(s) t=F−1(s)
- 上式计算结果极为采样点
- 证明
- 均匀分布的CDF函数
P ( x ≤ a ) = H ( x ) = x ( 0 ≤ x ≤ 1 ) P(x \leq a)=H(x)=x (0\leq x \leq 1) P(x≤a)=H(x)=x (0≤x≤1)
- 采样有以下性值
P ( x ≤ s ) = P ( x ≤ F ( t ) ) = F ( t ) P(x\leq s)=P(x\leq F(t))=F(t) P(x≤s)=P(x≤F(t))=F(t)
-
总结
对概率密度函数 f f f进行采样可以使用以上方式进行,但是并非所有的CDF都容易求得或其逆容易求得因此使用了其它方法
二、 Reject Sampling
- 采样类比
-
目标分布 π ( x ) \pi(x) π(x),分布 q ( x ) q(x) q(x)和常数 M M M,通过对 q ( x ) q(x) q(x)的采样实现对 π ( x ) \pi(x) π(x)采样,满足:
q ( x ) q(x) q(x)采样比较容易
q ( x ) q(x) q(x)的形状接近 π ( x ) \pi(x) π(x),且 ∀ x , π ( x ) ≤ M q ( x ) \forall x,\pi(x)\leq Mq(x) ∀x,π(x)≤Mq(x),即保证 0 ≤ π ( x ) M q ( x ) ≤ 1 0 \leq \frac{\pi(x)}{Mq(x)}\leq 1 0≤Mq(x)π(x)≤1
- 采样过程
- 生成样本 x ∽ q ( x ) x \backsim q(x) x∽q(x)和 u ∽ U n i f o r m [ 0 , 1 ] u \backsim Uniform[0,1] u∽Uniform[0,1]
- 若 u ≤ π ( x ) M q ( x ) u \leq \frac{\pi(x)}{Mq(x)} u≤Mq(x)π(x)则接受样本x
- 则接受样本服从 π ( x ) \pi(x) π(x)分布
- 证明
-
等价于
产生样本 X ∽ q ( X ) X \backsim q(X) X∽q(X)和 U ∽ [ 0 , 1 ] U \backsim[0,1] U∽[0,1]
Y = M q ( X ) U Y=Mq(X)U Y=Mq(X)U,若 Y ≤ π ( X ) Y \leq \pi(X) Y≤π(X),则接受X -
x的概率密度如下
p x ( x ) = q ( x ) p_x(x)=q(x) px(x)=q(x)
-
y的概率密度
F ( y ∣ x ) = P ( Y ≤ y ∣ x ) = P ( M q ( x ) U ≤ y ∣ x ) = P ( U ≤ y M q ( x ) ∣ x ) F(y|x)=P(Y\leq y|x)=P(Mq(x)U \leq y|x)=P(U \leq \frac{y}{Mq(x)}|x) F(y∣x)=P(Y≤y∣x)=P(Mq(x)U≤y∣x)=P(U≤Mq(x)y∣x)
上式表示在X发生的情况下y发生的情况 P ( U ≤ y M q ( x ) ) = y M q ( x ) P(U \leq \frac{y}{Mq(x)})=\frac{y}{Mq(x)} P(U≤Mq(x)y)=Mq(x)y
得到其概率密度函数如下:
p y ( y ∣ x ) = 1 M q ( x ) p_y(y|x)=\frac{1}{Mq(x)} py(y∣x)=Mq(x)1 -
联合密度函数
p ( x , y ) = p x ( x ) p y ( y ∣ x ) . = 1 M p(x,y)=p_x(x)p_y(y|x).=\frac{1}{M} p(x,y)=px(x)py(y∣x).=M1
-
按接受-拒绝采样抽出的随机数d的概率
F ( d ∣ a c c e p t ) = P ( X ≤ d ∣ Y ≤ π ( x ) ) = P ( X ≤ d , Y ≤ π ( x ) ) P ( Y ≤ π ( x ) ) = ∫ − ∞ d π ( x ) d x F(d|accept)=P(X\leq d| Y \leq \pi(x))=\frac{P(X\leq d, Y\leq \pi(x))}{P(Y \leq \pi(x))}=\int_{-\infty}^d\pi(x)dx F(d∣accept)=P(X≤d∣Y≤π(x))=P(Y≤π(x))P(X≤d,Y≤π(x))=∫−∞dπ(x)dx
-
缺点
选择q(x)非常重要,当 q ( x ) q(x) q(x)与 π ( x ) \pi(x) π(x)相差较大时采样效率就会非常低
三、蒙特卡洛采样
-
细致平稳条件
π ( x ∗ ) K ( x ∗ → x ) = p ( x ) K ( x → x ∗ ) \pi(x^*)K(x^* \rightarrow x) = p(x)K(x \rightarrow x^*) π(x∗)K(x∗→x)=p(x)K(x→x∗)
-
使用的过程
以一维分布为例
initialise x 0 x^0 x0
for i =0 to N-1
u ~ U(0,1)
x ∗ ∽ q ( x ∗ ∣ x i ) x^* \backsim q(x^*|x^{i}) x∗∽q(x∗∣xi)
i f u < a ( x ∗ ) = m i n ( 1 , π ( x ∗ ) q ( x ∣ x ∗ ) π ( x ) q ( x ∗ ∣ x ) ) x i + 1 = x ∗ if u < a(x^*)=min(1,\frac{\pi(x^*)q(x|x^*)}{\pi(x)q(x^*|x)}) x^{i+1}=x^* if u<a(x∗)=min(1,π(x)q(x∗∣x)π(x∗)q(x∣x∗)) xi+1=x∗
e l s e x i + 1 = x i else x^{i+1}=x^i else xi+1=xi -
证明其满足detail balance
需要证明: π ( x ) K ( x → x ∗ ) = π ( x ∗ ) K ( x ∗ → x ) \pi(x)K(x\rightarrow x^*)=\pi(x^*)K(x^*\rightarrow x) π(x)K(x→x∗)=π(x∗)K(x∗→x)
K ( x → x ∗ ) = q ( x ∗ ∣ x ) m i n ( 1 , π ( x ∗ ) q ( x ∗ ∣ x ) π ( x ) q ( x ∗ ∣ x ) ) K(x \rightarrow x^*)=q_(x^*|x)min(1,\frac{\pi(x^*)q(x^*|x)}{\pi(x)q(x^*|x)}) K(x→x∗)=q(x∗∣x)min(1,π(x)q(x∗∣x)π(x∗)q(x∗∣x))原式转化为
π ( x ) K ( x → x ∗ ) = π ( x ) q ( x ∗ ∣ x ) m i n ( 1 , π ( x ∗ ) q ( x ∗ ∣ x ) π ( x ) q ( x ∗ ∣ x ) ) \pi(x)K(x\rightarrow x^*)=\pi(x)q(x^*|x)min(1,\frac{\pi(x^*)q(x^*|x)}{\pi(x)q(x^*|x)}) π(x)K(x→x∗)=π(x)q(x∗∣x)min(1,π(x)q(x∗∣x)π(x∗)q(x∗∣x))
= m i n ( π ( x ) q ( x ∗ ∣ x ) , π ( x ∗ ) q ( x ∗ ∣ x ) ) =min(\pi(x)q(x^*|x),\pi(x^*)q(x^*|x)) =min(π(x)q(x∗∣x),π(x∗)q(x∗∣x))
= π ( x ∗ ) q ( x ∗ ∣ x ) m i n ( 1 , π ( x ) q ( x ∗ ∣ x ) π ( x ∗ ) q ( x ∣ x ∗ ) ) =\pi(x^*)q(x^*|x)min(1,\frac{\pi(x)q(x^*|x)}{\pi(x^*)q(x|x^*)}) =π(x∗)q(x∗∣x)min(1,π(x∗)q(x∣x∗)π(x)q(x∗∣x))
= π ( x ∗ ) K ( x ∗ → x ) =\pi(x^*)K(x^* \rightarrow x) =π(x∗)K(x∗→x)
四、Gibbs Sampling
-
过程
已知 x 1 , y 1 , z 1 x^1,y^1,z^1 x1,y1,z1
x 2 ∽ P ( x ∣ y 1 , z 1 ) x^2 \backsim P(x|y^1,z^1) x2∽P(x∣y1,z1)
y 2 ∽ P ( y ∣ x 2 , z 1 ) y^2 \backsim P(y|x^2,z^1) y2∽P(y∣x2,z1)
z 2 ∽ P ( z ∣ x 2 , y 2 ) z^2 \backsim P(z|x^2,y^2) z2∽P(z∣x2,y2)
x 3 ∽ P ( z ∣ x 2 , y 2 ) x^3 \backsim P(z|x^2,y^2) x3∽P(z∣x2,y2) -
证明Gibbis 与 蒙特卡洛关系
- 当采样第i个样本时
π ( x i ∗ ∣ X − i ) = q i ( x ∗ ∣ x ) \pi(x_i^*| X_{-i})=q_i(x^*|x) π(xi∗∣X−i)=qi(x∗∣x)
-
需证明
π ( x ∗ ) q i ( x ∣ x ∗ ) = π ( x ∗ ) q i ( x ∣ x ∗ ) \pi(x^*)q_i(x|x^*)=\pi(x^*)q_i(x|x^*) π(x∗)qi(x∣x∗)=π(x∗)qi(x∣x∗)
-
对应的接收率为
π ( x ∗ ) q ( x ∣ x ∗ ) π ( x ) q ( x ∗ ∣ x ) = π ( x ∗ ) π ( x i ∣ X − i ∗ ) π ( x ) π ( x i ∗ ∣ X − i ) \frac{\pi(x^*)q(x|x^*)}{\pi(x)q(x^*|x)}=\frac{\pi(x^*)\pi(x_i|X^*_{-i})}{\pi(x)\pi(x_i^*|X_{-i})} π(x)q(x∗∣x)π(x∗)q(x∣x∗)=π(x)π(xi∗∣X−i)π(x∗)π(xi∣X−i∗)
-
采样时 X − i ∗ = X − i X^*_{-i}=X_{-i} X−i∗=X−i因此有以下公式
π ( x i ∗ ∣ X − i ∗ ) π ( x i ∣ X − i ∗ ) π ( x i ∣ X − i ) π ( x i ∗ ∣ X − i ) = 1 \frac{\pi(x_i^*|X^*_{-i})\pi(x_i|X^*_{-i})}{\pi(x_i|X_{-i})\pi(x_i^*|X_{-i})}=1 π(xi∣X−i)π(xi∗∣X−i)π(xi∗∣X−i∗)π(xi∣X−i∗)=1 -
总结
吉布斯采样可以直接在 π ( x i ∣ X − i ) \pi(x_i|X_{-i}) π(xi∣X−i)上依次进行采样
主题模型
-
LDA
- LDA是一种无监督的贝叶斯模型
- 是一种主题模型,它可以将文档集中的每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量K即可。此外LDA的另一个优点则是,对于每个主题均可找出一些词语来描述它。
- 是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的顺序,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
-
生成词过程
例:
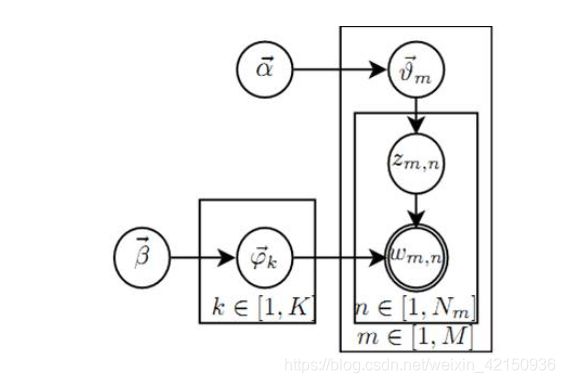
- a → → θ → m → z m , n \overrightarrow a \rightarrow \overrightarrow \theta_m \rightarrow z_{m,n} a→θm→zm,n,这个过程表示在生成m篇文档时,先抽取一个doc-topic骰子 θ → m \overrightarrow \theta_m θm,然后投掷这个筛子生成文档第n个词topic编号 z m , n z_{m,n} zm,nr
- β → → φ → k → w m , n \overrightarrow \beta \rightarrow \overrightarrow \varphi_k \rightarrow w_{m,n} β→φk→wm,n,这个过程表示如下动作生成第m篇文档中的第n个词:在K个topic-word筛子 φ → k \overrightarrow \varphi_k φk中,选择编号为 k = z m , n k=z_{m,n} k=zm,n这个筛子进行投掷,生成单词 w m , n w_{m,n} wm,n
-
LDA模型理解
LDA生成模型中,M篇文档会对应于M个独立的Dirchlet-Multionmial共轭分布。K个主题会生成K个独立的Dirichlet-Multionmial共轭结构。下面将分析LDA是如何被分解为M+K个Dirichlet-Multionmial共轭结构
-
第一个物理过程
此过程主要时需要获取 θ → m \overrightarrow \theta_m θm,我们知道 P ( θ → m ∣ z → m , a → ) ∝ P ( θ → m ∣ a → ) P ( z → m ∣ θ → m ) P(\overrightarrow \theta_m | \overrightarrow z_m,\overrightarrow a ) \propto P(\overrightarrow \theta_m|\overrightarrow a)P(\overrightarrow z_m| \overrightarrow \theta_m) P(θm∣zm,a)∝P(θm∣a)P(zm∣θm)因此我们可以对后面的数据进行优化,操作如下:
P ( z → m ∣ a → ) = ∫ θ → m P ( z → m ∣ θ → m ) P ( θ → m ∣ a → ) d θ → m = Δ ( n → m + a → ) Δ ( a → ) P(\overrightarrow z_m | \overrightarrow a ) = \int _{\overrightarrow \theta_m}P(\overrightarrow z_m |\overrightarrow \theta_m )P(\overrightarrow \theta_m|\overrightarrow a )d_{\overrightarrow \theta_m}=\frac{\Delta(\overrightarrow n_m+\overrightarrow a)}{\Delta(\overrightarrow a)} P(zm∣a)=∫θmP(zm∣θm)P(θm∣a)dθm=Δ(a)Δ(nm+a)
同时 θ → m ∽ D i r ( θ → m ∣ n → m + a → ) \overrightarrow \theta_m \backsim Dir(\overrightarrow \theta_m|\overrightarrow n_m+\overrightarrow a) θm∽Dir(θm∣nm+a)且对整个词库而言满足以下公式:
P ( z → ∣ α → ) = ∏ m = 1 M P ( z → m ∣ α → ) = ∏ m = 1 M Δ ( n → m + a → ) Δ ( a → ) P(\overrightarrow z | \overrightarrow \alpha)=\prod_{m=1}^MP(\overrightarrow z_m | \overrightarrow \alpha)=\prod_{m=1}^M \frac{\Delta(\overrightarrow n_m+\overrightarrow a)}{\Delta(\overrightarrow a)} P(z∣α)=m=1∏MP(zm∣α)=m=1∏MΔ(a)Δ(nm+a)
注: n → m \overrightarrow n_m nm表示第m个文档中对应主题所形成的分布,即 [ n 1 , n 2 , ⋯ , n k ] m [n_1,n_2,\cdots,n_k]_m [n1,n2,⋯,nk]m -
第二个物理过程
此过程主要获取 φ → k \overrightarrow \varphi_k φk,我们知道 P ( φ → k ∣ w → ( k ) , β → ) ∝ P ( φ → k ∣ β → ) P ( w → ( k ) ∣ φ → k ) P(\overrightarrow \varphi_k | \overrightarrow w_{(k)},\overrightarrow \beta ) \propto P(\overrightarrow \varphi_k|\overrightarrow \beta)P(\overrightarrow w_{(k)}| \overrightarrow \varphi_k) P(φk∣w(k),β)∝P(φk∣β)P(w(k)∣φk),因此我们需要对后面的数据进行优化,操作如下:
P ( w → ( k ) ∣ β → ) = Δ ( n → k + β → ) Δ ( β → ) P(\overrightarrow w_{(k)}|\overrightarrow \beta)=\frac{\Delta(\overrightarrow n_k + \overrightarrow \beta)}{\Delta(\overrightarrow \beta)} P(w(k)∣β)=Δ(β)Δ(nk+β)
同时 φ → k ∽ D i r ( φ → k ∣ n → k + β → ) \overrightarrow \varphi_k \backsim Dir(\overrightarrow \varphi_k|\overrightarrow n_k+\overrightarrow \beta) φk∽Dir(φk∣nk+β)对整个语料而言:
P ( w → ∣ z → , β → ) = ∏ k = 1 K Δ ( n → k + β → ) Δ ( β → ) P(\overrightarrow w | \overrightarrow z ,\overrightarrow \beta)= \prod_{k=1}^K\frac{\Delta(\overrightarrow n_k + \overrightarrow \beta)}{\Delta(\overrightarrow \beta)} P(w∣z,β)=k=1∏KΔ(β)Δ(nk+β)
注: n → k \overrightarrow n_k nk表示第k个主题中word形成的分布,即 [ n 1 , n 2 , ⋯ , n N ] k [n_1,n_2,\cdots,n_N]_k [n1,n2,⋯,nN]k -
综合有整个词库中主题、词的联合分布如下:
P ( w → , z → ∣ α → , β → ) = ∏ k = 1 K Δ ( n → k + β → ) Δ ( β → ) ∏ m = 1 M Δ ( n → m + a → ) Δ ( a → ) P(\overrightarrow w ,\overrightarrow z | \overrightarrow \alpha ,\overrightarrow \beta)=\prod_{k=1}^K\frac{\Delta(\overrightarrow n_k + \overrightarrow \beta)}{\Delta(\overrightarrow \beta)}\prod_{m=1}^M \frac{\Delta(\overrightarrow n_m+\overrightarrow a)}{\Delta(\overrightarrow a)} P(w,z∣α,β)=k=1∏KΔ(β)Δ(nk+β)m=1∏MΔ(a)Δ(nm+a)
-
使用Gibbs Sampling法求解 P ( z → ∣ w → ) P(\overrightarrow z| \overrightarrow w) P(z∣w)
Gibbs采样需要进行用到 P ( z i = k , w i = t ∣ z → − i , w → − i ) P(z_i=k,w_i=t|\overrightarrow z_{-i},\overrightarrow w_{-i}) P(zi=k,wi=t∣z−i,w−i),因此需要以下推导:
有了联合分布 p ( w → , z → ) p(\overrightarrow w, \overrightarrow z) p(w,z),则Gibbs Sampling就可以发挥作用了,语料库 z → \overrightarrow z z中的第i个词对应的topic我们记为 z i z_i zi,其中 i = ( m , n ) i=(m,n) i=(m,n)表示第m个文本的第n个词,其采样的分布如下:
P ( z i = k , w i = t ∣ z → − i , w → − i ) P(z_i=k,w_i=t|\overrightarrow z_{-i},\overrightarrow w_{-i}) P(zi=k,wi=t∣z−i,w−i)
由于 z i = k , w i = t z_i =k,w_i=t zi=k,wi=t只涉及到第m篇文档第k个topic,所以只会涉及到两个Dirichlet-Multinomial共轭结构:- a → → θ → m → z → m \overrightarrow a \rightarrow \overrightarrow \theta_m \rightarrow \overrightarrow z_m a→θm→zm
- β → → φ → k → w → ( k ) \overrightarrow \beta \rightarrow \overrightarrow \varphi_k \rightarrow \overrightarrow w_{(k)} β→φk→w(k)
-
减少了词的后验分布变为如下公式:
P ( θ → m ∣ z → − i , w → − i ) = D i r ( θ → m ∣ n → m , − i + α → ) P(\overrightarrow \theta_m|\overrightarrow z_{-i},\overrightarrow w_{-i}) = Dir(\overrightarrow \theta_m | \overrightarrow n_{m,-i}+\overrightarrow \alpha) P(θm∣z−i,w−i)=Dir(θm∣nm,−i+α)
P ( φ → k ∣ z → − i , w → − i ) = D i r ( φ → k ∣ n → k , − i + β → ) P(\overrightarrow \varphi_k|\overrightarrow z_{-i},\overrightarrow w_{-i}) = Dir(\overrightarrow \varphi_k | \overrightarrow n_{k,-i}+\overrightarrow \beta) P(φk∣z−i,w−i)=Dir(φk∣nk,−i+β)
-
则可以推导出:
P ( z i = k ∣ z → − i , w → ) ∝ ∫ p ( z i = k , w i = t , θ → m , φ → k ∣ z → − i , w → − i ) d θ → m d φ → k = n m , − i k + a k ∑ k = 1 K ( n m , − i k + a k ) n k , − i t + β t ∑ t − 1 V ( n k , − i t + β t ) P(z_i=k|\overrightarrow z_{-i},\overrightarrow w)\propto \int p(z_i=k,w_i=t,\overrightarrow \theta_m,\overrightarrow \varphi_k| \overrightarrow z_{-i},\overrightarrow w_{-i})d_{\overrightarrow \theta_m} d_{\overrightarrow \varphi_k}=\frac{n_{m,-i}^k+a_k}{\sum_{k=1}^K(n_{m,-i}^k+a_k)} \frac{n_{k,-i}^t+\beta_t}{\sum_{t-1}^V(n_{k,-i}^t+\beta_t)} P(zi=k∣z−i,w)∝∫p(zi=k,wi=t,θm,φk∣z−i,w−i)dθmdφk=∑k=1K(nm,−ik+ak)nm,−ik+ak∑t−1V(nk,−it+βt)nk,−it+βt -
采样过程
我们的目标如下:
- 估计模型中的参数 φ → 1 , ⋯ , φ → K \overrightarrow \varphi_1,\cdots,\overrightarrow \varphi_K φ1,⋯,φK和 θ → 1 , ⋯ , θ → M \overrightarrow \theta_1,\cdots,\overrightarrow \theta_M θ1,⋯,θM
- 对于新来的一篇文档d_{new},我们能够计算这篇文档的topic分布 θ → n e w \overrightarrow \theta_{new} θnew
-
第一步需要训练LDA以估计参数 φ → 1 , ⋯ , φ → K \overrightarrow \varphi_1,\cdots,\overrightarrow \varphi_K φ1,⋯,φK和 θ → 1 , ⋯ , θ → M \overrightarrow \theta_1,\cdots,\overrightarrow \theta_M θ1,⋯,θM
- 随机初始化:对语料中每篇文档中的每个词 w w w,随机的赋一个topci编号为 z z z
- 重新扫描语料库,对每个词w,按照Gibbs Sampling公式重新采样它的topic,在语料库中重新更新;
- 重复以上语料库的重新采样过程直到Gibbs Sampling收敛
- 统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型了
-
第二步为估计新文档的topic分布,此时我们认为Gibbs Sampling公式中的 φ ^ k t \hat \varphi_{kt} φ^kt部分时稳定不变的,是由训练语料得到的模型提供的,所以采样过程中我们只需要估计该文档的topic部分的 θ → n e w \overrightarrow \theta_{new} θnew
- 随机初始化:对当前文档中的每个词w,随机的赋值一个topic编号z
- 重新扫描当前文档,按照Gibbs Sampling公式,对每个词w,重新采样它的topic
- 重复以上过程直到Gibbs Sampling收敛
- 统计文档中的topic分布,该分配就是 θ → n e w \overrightarrow \theta_{new} θnew
-
使用sklearn实现一个LDA算法
-
获取数据
from sklearn.datasets import fetch_20newsgroups dataset = fetch_20newsgroups(shuffle=True,random_state=1,remove=('headers','footers','quotes')) n_samples = 2000 data_samples = dataset.data[:n_samples] -
文本处理
import nltk import string from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer def textPrecessing(text): #小写 text = text.lower() #去除特殊标点 for c in string.punctuation: text = text.replace(c,' ') #分词 wordList = nltk.word_tokenize(text) #去除停用词 filtered = [w for w in wordList if w not in stopwords.words('english')] #保留名词与特定POS refiltered = nltk.pos_tag(filtered) filtered = [w for w,pos in refiltered if pos.startswith('NN')] #词干化 ps = PorterStemmer() filtered = [ps.stem(w) for w in filtered] return ' '.join(filtered) docLst = [] for desc in data_samples: docLst.append(textPrecessing(desc)) -
将数据存入文档
with open('./data.txt','w') as f: for line in docLst: f.write(line+'\n') -
词频统计
from sklearn.feature_extraction.text import CountVectorizer from sklearn.externals import joblib tf_vectorizer = CountVectorizer(max_df=0.95,min_df=2,max_features=500,stop_words='english') tf = tf_vectorizer.fit_transform(docLst) joblib.dump(tf_vectorizer,'.\model.pck') -
LDA训练
from sklearn.decomposition import LatentDirichletAllocation n_topics = 30 lda = LatentDirichletAllocation(n_topics=n_topics,max_iter=50,learning_method='batch') lda.fit(tf) -
结果展示
def print_top_words(model,feature_names,n_top_words): for topic_idx,topic in enumerate(model.components_): print('Topic #%d'%topic_idx) print(' '.join([feature_names[i] for i in topic.argsort()[: -n_top_words -1:-1]])) print(model.components_) n_top_words=20 tf_feature_names = tf_vectorizer.get_feature_names() print_top_words(lda,tf_feature_names,n_top_words)