CenterNet训练自己的数据集
重点!
首先说一下具体的代码能运行成功所需要的条件:
cuda9.0
与cuda9.0相匹配的cudnn
pytorch0.4.0版本
然后就是自己遇到的一系列问题了:
Q1
首先我是想在自己原来的cuda10.0和cudnn下运行的,但是出现了很多问题,尤其是在编译DCNv2的时候,于是我参考了这篇博客,发现问题并没有解决,主要问题是想要和cuda10.0匹配,那么pytorch就不能是0.4.1版本的,就一定会高于这个版本,那么出现的ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.问题和TypeError: dist must be a Distribution instance问题就不可避免,想要解决就只能自己重写DCNv2的代码,所以我放弃了。
选择重新安装cuda9.0
前提:
自己的电脑是2080Ti的,已经有的环境是cuda10.0+与cuda10.0匹配的cudnn7.6.5。
由于代码在cuda10.0下会出现很多错误,所以我先把cuda10.0换成了cuda9.0。详细请参考另一篇博客:安装另一个版本cuda和cudnn
搭建环境
cuda和cudnn已经安装好了,开始利用Anaconda搭建一个新的环境,来运行CenterNet网络。
- 创建虚拟conda 环境
conda create --name CenterNet python=3.6 - 激活环境
conda activate CenterNet
以后运行CenterNet都要在这个环境中运行,关闭终端,再开启新的终端的时候,一定记得切换环境,否则肯定会有问题的。如果使用pycharm,也要记得加载新的环境。
pycharm加载新的环境方法:Files——settings——Project: CenterNet-master——Project Interpreter——点击Project Interpreter后面的设置符号,出现两个选项,选择Add那一项——选择conda Environment——Existing environment——选择自己刚才新建的环境CenterNet。 - 安装pytorch0.4.1版本:
pip install torch==0.4.1 - 安装 torchvision
pip install torchvision==0.2.2
一定一定!!!记住就是打开终端的时候记得切换环境!后面的很多操作,我没有强调切换环境,但是只要你是重新开启了新的终端就一定要切换环境!切换到CenterNet。
这样暂时算环境搭建完毕,现在想试试demo能不能跑起来。
测试demo
- 安装cocoapi
自己去下载一个cocoapi,github上有很多:参考
下载完,放在CenterNet目录下就可以了,然后进入到目录./cocoapi/PythonAPI 运行make
然后在运行:python setup.py install --user - 安装需要用到的依赖库:
来到CenterNet的目录下,打开终端执行pip install -r requirements.txt下载需要用到的依赖库。 - 编译 Compile deformable convolutional (from DCNv2).
进入到指定路径CenterNet_ROOT/src/lib/models/networks/DCNv2下,运行make.sh文件即可。 - 编译一下NMS,来到external文件下,打开终端,环境切换到CenterNet下,编译一下,
make - 下载预训练的模型放置到models文件夹下,这里下载的是目标检测,选了一个最高分的。在这个网址中下载一个训练好的模型,我下载了第一个model。下载完了,放在models下。
- 然后开始可以测试demo,来到src文件下,打开终端,输入:
python demo.py ctdet --demo /home/dlut/网络/CenterNet-master/images/ --load_model /home/dlut/网络/CenterNet-master/models/ctdet_coco_dla_2x.pth
注意这个路径要改成自己的绝对路径。就可以看到测试的结果了。
我在运行的时候遇到了问题:RuntimeError: cuda runtime error (11) : invalid argument at /pytorch/aten/src/THC/THCGeneral.cpp:663
解决办法是:在demo.py中加了:
import torch
torch.backends.cudnn.enabled = False #加上这两句就可以跑通代码
准备自己的数据集
一般,我们自己的数据集都是VOC格式的,这个需要转换成coco格式的数据集,参考另一篇博客。
- 当我们生成三个json文件(train.json;val.json;test.json)之后,来到CenterNet-master这个工程里,在data文件夹下新建一个文件夹,名字就是你数据集的名字。

- 再在这个文件夹里面建两个文件夹(annotations里面存放的是我们之前生成的那三个json文件;images存放的是所有的图片,包括训练测试验证三个,所有的):
- 在src/lib/datasets/dataset里面新建一个
“insulatorBolt.py”,文件内容照着文件夹下coco.py改成自己的。
(1)将COCO类改成自己的名字
class InsulatorBolt(data.Dataset):
(2)第14行num_classes=80改成自己的类别数,我的是四类,所以改为了num_classes=4
(3)第15行default_resolution(这个参数有两种(300,300)或者(512,512),很明显512的参数计算量大,300计算量小,我用的是512),所以为:default_resolution = [512, 512]
(4)接下来的mean和std改成自己图片数据集的均值和方差,脚本链接: Python计算图片数据集的均值方差
通过计算,我的均值和方差改为了:
mean = np.array([1.816706, 1.856168, 1.751525],
dtype=np.float32).reshape(1, 1, 3)
std = np.array([2.632229, 2.685731, 2.541777],
dtype=np.float32).reshape(1, 1, 3)
(5)修改数据和图片路径,data_dir 输入的是咱们之前建立的数据集文件夹的名字,img_dir 输入的是 images 图片文件夹。
def __init__(self, opt, split):
super(InsulatorBolt, self).__init__()
self.data_dir = os.path.join(opt.data_dir, 'insulator_bolt')
self.img_dir = os.path.join(self.data_dir, 'images')
(6)修改json文件路径如下:
if split == 'val': ##################################val或者test
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'val.json').format(split) ##################################val或者test
#自己加的
elif split == 'test':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'test.json').format(split) # 修改test的json文件位置
else:
if opt.task == 'exdet':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split)
else:
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split)
(7)类别名字和类别id改成自己,
self.class_name = [
'__background__', 'normal', 'defect', 'norbolt', 'debolt']
self._valid_ids = [
0,1, 2, 3, 4]
我就改了以上七点内容。
- 将数据集加入src/lib/datasets/dataset_factory里面
在dataset_facto字典里加入自己的数据集名字 (格式为 '你之前创建的Python文件的名字':你自己数据集类的名字,因为要从你创建的py文件里找到你的数据类,名字必须对应上)
(1)先导包,否则会报错:导包:from .dataset.insulatorBolt import InsulatorBolt #自己添加的
(2)在dataset_facto字典里加入自己的数据集名字
dataset_factory = {
'coco': COCO,
'pascal': PascalVOC,
'kitti': KITTI,
'coco_hp': COCOHP,
'insulatorBolt':InsulatorBolt #自己添加的
}
- 修改/src/lib/opts.py
(1)将自己的数据集设为默认数据集,加入到help里面,15行左右
self.parser.add_argument('--dataset', default='insulatorBolt', ###################################修改
help='coco | kitti | coco_hp | pascal | insulatorBolt')
(2)修改ctdet任务使用的默认数据集为新添加的数据集,如下(修改分辨率,类别数,均值,方差,数据集名字):336行左右
def init(self, args=''):
default_dataset_info = {
'ctdet': {'default_resolution': [512, 512], 'num_classes': 4,
'mean': [1.816706, 1.856168, 1.751525], 'std': [2.632229, 2.685731, 2.541777],
'dataset': 'insulatorBolt'}, ############################################修改
- 修改src/lib/utils/debugger.py文件(变成自己数据的类别和名字,前后数据集名字一定保持一致)
(1)添加自己的数据集:47行左右,添加:
elif num_classes == 4 or dataset == 'insulatorBolt':
self.names = insulatorBolt_class_name
(2)460行左右添加自己的类别:
insulatorBolt_class_name=[
'normal', 'defect', 'norbolt', 'debolt'
]
到这里,准备数据集的工作就算完成了!
训练自己的数据吧 main.py
来到main.py的文件下:/home/dlut/网络/CenterNet-master/src
切换环境。
python main.py ctdet --exp_id coco_dla --batch_size 8 --master_batch 1 --lr 1.25e-4 --gpus 0
因为我只有一块gpu,所以gpus 设置为0,学习率,batch_size这些都可以自己进行修改。
想要修改参数可以去opts.py中取修改。(如果显示显存不够之类的那种错误,需要在opts.py文件中将–num_workers改成0,batch_size改成16或者更小。
我在运行的时候遇到了问题:RuntimeError: cuda runtime error (11) : invalid argument at /pytorch/aten/src/THC/THCGeneral.cpp:663
解决办法是:在main.py中加了:
import torch
torch.backends.cudnn.enabled = False #加上这两句就可以跑通代码
没什么意外的话,应该开始训练了。
评价结果
当训练完之后,在./exp/ctdet/coco_dla/文件夹下会出现如下文件
其中,model_last是最后一次epoch的模型;model_best是val最好的模型,我选的是model_best模型;
将test.py中两处的 split = 'val' if not opt.trainval else 'test'替换为split = 'test在63行和100行左右。
然后终端输入:python test.py --exp_id coco_dla --not_prefetch_test ctdet --load_model /home/dlut/网络/CenterNet-master/exp/ctdet/coco_dla/model_best.pth开始评价。
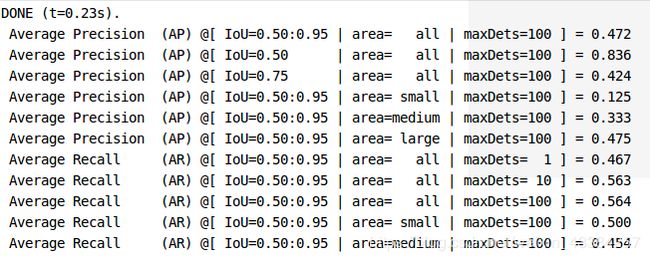
不出意外的话会出现下面的画面(出现一系列AP值),其中,一般使用的是第二行,也就是IOU=0.5,全区域的AP值,其他的分别是不同IOU以及不同目标尺寸区域的结果。
测试结果
这回运行demo.py来查看自己的结果。
- 首先你得把你自己要测试的图片放在一个单独的文件夹中,比如你要将test.txt文本中的图片进行测试,那么,你就得把这些数字的图片单独存放在一个文件夹中,可以用如下的代码:
##########################某一个txt文本中的数字存的是图片的名字,要把这些名字的图片保存到另一个文件夹中########################
#修改两处,注意自己建立文件
from PIL import Image
import os
f3 = open("/home/dlut/网络/CenterNet-master/VOC2018/ImageSets/Main/test.txt",'r') #test文件所在路径
for line2 in f3.readlines():
line3=line2[:-1] #读取所有数字 000000
im = Image.open('/home/dlut/网络/CenterNet-master/VOC2018/JPEGImages/{}.jpg'.format(line3))#打开改路径下的line3记录的的文件名
im.save('/home/dlut/网络/CenterNet-master/VOC2018/testImg/{}.jpg'.format(line3)) #把文件夹中指定的文件名称的图片另存到该路径下 #自己需要新建一个新的文件夹
f3.close()
然后我把所有需要测试的图片存放在了testImg下,把testImg文件放在CenterNet-master目录下面,然后在开始测试。
- 要注意的是,当弹出第一站图片的时候,按esc除外的任意键可以继续检测下一张图,想要保存检测结果的话,只需要在src/lib/detectors/cdet.py文件中:
def show_results(self, debugger, image, results):
debugger.add_img(image, img_id='ctdet')
for j in range(1, self.num_classes + 1):
for bbox in results[j]:
if bbox[4] > self.opt.vis_thresh:
debugger.add_coco_bbox(bbox[:4], j - 1, bbox[4], img_id='ctdet')
#debugger.show_all_imgs(pause=self.pause)
debugger.save_all_imgs(path='/home/dlut/网络/CenterNet-master/output/', genID=True)
加上一行代码,就是最后一行debugger.save_all_imgs(path='/home/dlut/网络/CenterNet-master/output/', genID=True),path是输出路径,需要在CenterNet文件夹下新建一个文件夹output,然后再运行一遍发现检测后的图片就会保存在这个文件夹里面了。当然,去掉倒数第二行show_all_imgs,那么运行的时候就不会弹出照片了。
参考:
(绝对详细)CenterNet训练自己的数据(pytorch0.4.1)
感谢博主写的那么详细,但是自己在运行的时候,还是遇到了一些问题,所以自己重新总结谢了一份。