【用SQLite做数据分析】Python操作SQLite的入门介绍

本篇推文共计2000个字,阅读时间约3分钟。
Python 进行数据分析和数据挖掘是当前炙手可热的技术领域,如何高效地管理大量数据是其中非常关键的环节。数据库是最佳的解决方案之一,目前流行的数据库有 Oracle、MySQL、MongoDB、Redis、SQLite。
关于数据库的选型通常取决于性能、数据完整性以及应用方面的需求。

1
Oracle数据库
官方网站:https://www.oracle.com/index.html
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的、适应高吞吐量的数据库方案。
2
MySQL数据库
官方网站:https://www.mysql.com/

MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
3
MongoDB数据库
官方网站:https://www.mongodb.org.cn/
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
4
Redis数据库
官方网站:https://redis.io/
Redis 是一个高性能的key-value数据库。redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。

当然本系列推文为各位读者安利一款Python 内置的轻型数据库——SQLite3
SQLite3数据库
官方网站:https://www.sqlite.org/index.html
SQLite 是在世界上最广泛部署的 SQL 数据库引擎。它本身是用 C 写的,不但体积小巧,而且处理速度快,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。非常适合用于 Python数据分析爱好者在本地实现数据管理。
DB-Engines发布了2019年6月份的全球数据库流行度排名,如下图所示。虽然排名前五一如既往还是Oracle、MySQL、Microsoft SQL Server、PostgreSQL、MongoDB。
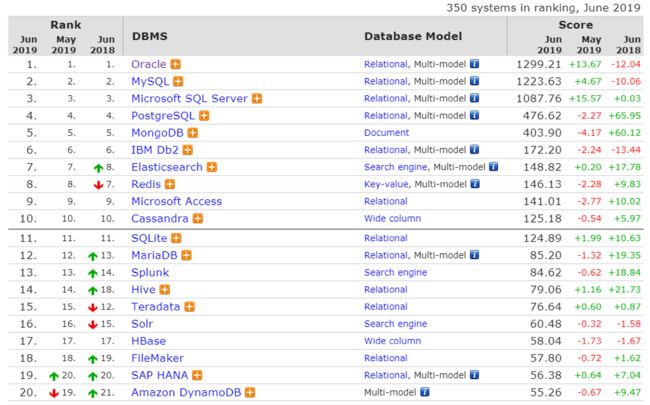
不过每个数据库都有它的特点和最适合的应用场合,尽管 SQLite 几乎每个月都保持在10 名左右,但我们还是强力推荐,此处推荐理由如下:
轻量级:传统的C/S模式的数据库软件不同,它是进程内的数据库引擎,不存在客户端和服务器。使用SQLite,只需要带上一个几百K大小的动态库就可以操作。SQLite本身是C写的,所以体积小巧,占用资源低。
绿色组件SQLite的核心引擎本身不依赖第三方软件,即插即用。
单一文件:数据库中所有的信息(比如表、视图、触发器等)都保存在单个文件内,可以拷贝到其他地方,照用不误。
跨平台:支持主流操作系统(Windows/Linux/Unix),还支持很多小型嵌入式系统(Android,WP,Vxworks)。查询效率极高:SQLite的API不区分当前数据库是保存在内存中还是在磁盘文件中,为了提高效率,可以切换为内存方式。只需要在开始时将数据库载入内存,读写完成后,再把内存数据库dump会磁盘文件上就可以,读写内存比读写磁盘快很多倍。
直接使用:Python 2.5.x 以上版本默认内置 SQLite3,无需单独安装和配置,直接使用。
Python 2.5.x 以上版本内置了SQLite库,因此无需单独安装SQLite库,只需导入Python 提供的API接口模块SQLite3即可,如下所示:
导入SQLite驱动
import sqlite3连接到Python内置的SQlite数据库
Python 中操作 SQLite 的常用 API 如下所示:
创建数据库的连接
conn = sqlite3.connect('Peter-data.db')使用 Python 操作 SQLite 库,首先需要连接这个数据库。通过 sqlite3.connect() 接口可以链接到 SQLite 库并返回一个连接对象 connection,如果数据库不存在,那么将会自动创建一个数据库。如上所示如果名字为“Peter-data”的数据库不存在,那么系统就会自动创建一个数据库“Peter-data”
SQLite 是文件型数据库,可以看到创建的Peter-data.db是个文件,备份该文件就备份了整个数据库。
建立 Cursor对象
在连接到数据库之后,需要建立Cursor对象,通过建立Cursor能让数据库执行 SQL 语句。通俗一点来说,Cursor可以指向数据库里的数据,在SQLite里的所有数据操作都是通过Cursor来进行。
c = conn.cursor()创建数据库中的表
在数据库中数据是以表的形式存放的。我们使用 SQL 语句“CREATE TABLE”在 Peter-data.db数据库中创建一个SG000001表。
“CREATE TABLE”语句后跟着表的唯一的名称或标识,数据库识别到“CREATE TABLE”关键字后则会创建一个新表。如下所示:
c.execute('''CREATE TABLE SG000001
(ID INT PRIMARY KEY NOT NULL,
TIME TEXT NOT NULL,
CODE TEXT NOT NULL,
HIGH REAL,
LOW REAL,
CLOSE REAL,
OPEN REAL,
DESCRIPTION CHAR(50));''')
conn.commit()ID、TIME、CODE、HIGH、LOW、CLOSE、OPEN、DESCRIPTION 为表中的列.
INT、TEXT、REAL、CHAR 表示数据类型.
NOT NULL 约束:确保某列不能有 NULL 值.
PRIMARY Key 约束:主键,唯一标识数据库表中的各行/记录,主键,一般为自动增长并且是非空、int类型的,主要用来保证数据的唯一性.
创建表后记得使用connection.commit()接口提交当前的操作,如果未调用该函数,那么所做的任何操作对数据库来说都是无效的。
验证数据库中的表是否创建成功
我们可以查看表的结构来验证表是否已成功创建,cursor.fetchall()接口可将查询到的结果以列表形式返回所有行。
# 查询表结构
c.execute("PRAGMA table_info(SG000001)")
print(c.fetchall())执行以上程序后:
import sqlite3
conn = sqlite3.connect('Peter-data.db')
c = conn.cursor()
c.execute('''CREATE TABLE SG000001
(ID INT PRIMARY KEY NOT NULL,
TIME TEXT NOT NULL,
CODE TEXT NOT NULL,
HIGH REAL,
LOW REAL,
CLOSE REAL,
OPEN REAL,
DESCRIPTION CHAR(50));''')
conn.commit()
c.execute("PRAGMA table_info(SG000001)")
print(c.fetchall())显示如下所示:
![]()
我们数据库中的表创建成功!
当然以上操作结束后别忘了关闭游标,关闭数据库
# 关闭游标
c.close()
# 关闭数据库连接
conn.close()本期内容到此结束,下期内容,我们将手把手教你Python中使用SQLite数据库的常用操作,添加数据,更新数据,删除数据,查询数据等,敬请期待!

往期回顾

经典 | Python实例小挑战—Part ten

【玩转华为云】伟大的时代,需要每个伟大的你
【玩转华为云】手把手教你利用ModelArts实现人脸年龄预测

【玩转华为云】2020年5月22日,我成为了华为云·云享专家

【福利AI&Python】精心整理81份干货资料,让你轻松获取大厂offer!
欢迎各位读者在下方进行提问留言
☆ END ☆

你与世界
只差一个
公众号