ElasticSearch suggester
Suggesters就是一款基于用于提供的文本给出一些相似性的东西,即在用户输入搜索的过程中,进行自动补全或者纠错。 通过协助用户输入更精准的关键词,提高后续全文搜索阶段文档匹配的程度
POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : {
"my-suggestion" : {
"text" : "trying out Elasticsearch",
"term" : {
"field" : "message"
}
}
}
}
每一个请求体内,都可以指定多个suggestions,每一个suggestion都可以随意命名,如:
POST _search
{
"suggest": {
"my-suggest-1" : {
"text" : "tring out Elasticsearch",
"term" : {
"field" : "message"
}
},
"my-suggest-2" : {
"text" : "kmichy",
"term" : {
"field" : "user"
}
}
}
}
ES中,Suggester主要分为四种类型:term, phrase,completion以及context。
一 Term Suggester
在建议之前,会对用户提供的输入进行分词,然后进行suggest,只是针对单个term进行suggest,并不会考虑多个term之间的关系。
流程如下:
给一点数据:
PUT /website/news/1
{
"title":"China strives to improve products,services",
"content":"President said China will strive to providethe world with better products and services in a congratulatory letter to theChina Quality Conference, which opened on Friday in Shanghai"
}
PUT /website/news/2
{
"title":"COMAC eyes 750 orders for C919 jet",
"content":"Ordersfor the C919, the first large passenger aircraft produced in China inaccordance with international civil aviation regulations, are expected to reach750 by year's end, corporate officials told China Daily"
}
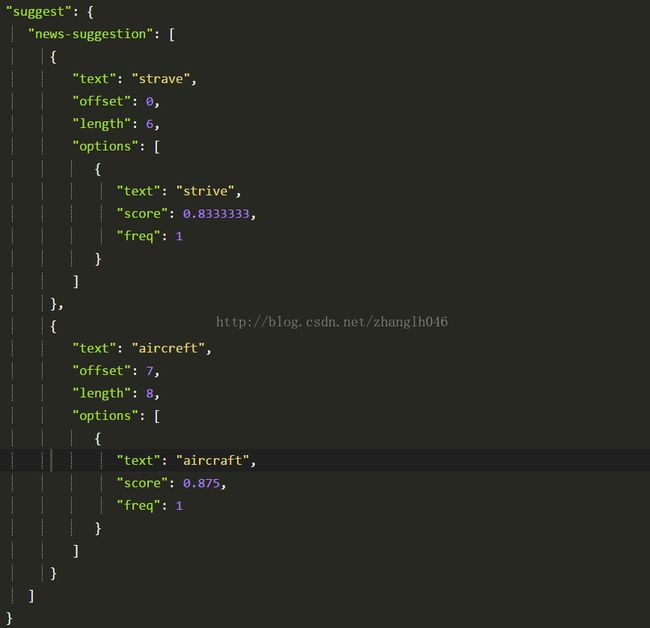
比如你提供两个单词:strave aircreft
# 将这个文本进行分词,拆分成strave和aircreft两个tokens
# 再suggest搜索中指定term suggest方式
POST /website/news/_search
{
"suggest":{
"news-suggestion":{
"text":"strave aircreft",
"term":{
"field":"content"
}
}
}
}
# 返回建议的terms,并不会将该字段全部返回
参数选项:
text:要进行suggest的文本,必须的
field:即从哪一个字段去获取suggest term,必须的
analyzer:指定分析text中文本的分词器,默认是field字段的分词器
size:最多返回多少个纠正,不是每一种类型都支持
sort:纠正的term如何排序,两个选项:score和frequency
suggest_mode:纠正或者建议模式:
# missing: 只对那些在索引里没有term给出建议,默认选项,如果已经有了,表示已经很精准了,不需要
# popular: 即使可能已经很精准了,但是如果存在一个词频更高的相似项,这个相似项可能是更合适的
# always:是不管token是否存在于索引词典里都要给出相似项。
prefix_length:前缀匹配的时候,必须满足的最少字符
min_word_length:最少包含的单词数量
min_doc_freq:最少的文档频率
max_term_freq:最大的词频
二 Phrase Suggester
我们知道,term suggester可以对单个term进行建议或者纠错,不会考虑多个term之间的关系,但是phrase suggester在term suggester的基础上,考虑多个term之间的关系,比如是否同时出现一个索引原文中,相邻程度以及词频等等
PUT /website/phrase/1
{
"title":"Spark uses Hadoop client libraries for HDFS andYARN."
}
PUT /website/phrase/2
{
"title":"Downloads are pre-packaged for a handful ofpopular Hadoop versions"
}
PUT /website/phrase/3
{
"title":"Users can also download a “Hadoop free” binaryand run Spark with any Hadoop version by augmenting Sparks classpath"
}
PUT /website/phrase/4
{
"title":"deploy Sparks on top of Hadoop NextGen"
}
开始进行搜索spaek and hadop
POST /website/phrase/_search
{
"suggest":{
"news-suggestion":{
"text":"spaek and hadop",
"phrase":{
"field":"title",
"size":3,
"highlight":{
"pre_tag": "",
"post_tag": ""
}
}
}
}
}
首先返回的是一个phrase列表,我们加了highlight选项,被建议的term会被高亮。另外如果被建议的词以前是在同一个索引原文里,那么他的分数最高。

参数选项:
field: 针对哪一个字段进行短语纠正
gram_size: 如果字段不包含n-grams,那么可以略过此参数,此参数设置gram级别
confidence:置信水平定义了一个应用于输入词组分数的因子,它被用作其他建议候选人的阈值。只有得分高于阈值的候选人才会被包括在结果中。例如,1.0的置信级别只会返回高于输入的提示。如果设置为0.0,则返回前N个候选项。缺省值是1.0。
separator:用于在bigram字段中分离term的分隔符
size:返回的结果个数
analyzer:指定分词器,默认和字段分词器一样
text:提供的输入文本
highlight:高亮显示
collate:检查针对指定查询的每个建议,以删除索引中不存在匹配文档的建议。
三 Completion Suggester
这就是我们经常说的auto completion,即自动补全。在用户输入的时候,给用户一些导航性质的结果,以提升搜索精度,但是他不是拼写检查或者did you mean这种功能或者像单词或者短语建议一样。
一般理想的讲,自动补全功能希望是越快越好,所以自动completion suggester主要在速度上做了优化,它所使用的数据结构能够使得快速查询,但是成本就是基于内存的。
索引并非通过倒排来完成,而是将分词过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是CompletionSuggester的局限所在。
要使用自动补全,我们需要在mapping中为该字段指定一些属性:
PUT /ecommerce/_mapping/mf
{
"properties":{
"description":{
"type":"completion"
}
}
}
或者
PUT /ecommerce/_mapping/mf
{
"properties":{
"description":{
"type":"text",
"analyzer": "ik_max_word",
"fields": {
"suggest" : {
"type" : "completion",
"analyzer": "ik_max_word"
}
}
}
}
}
PUT /ecommerce/mf/1
{
"description":"Premium Faring Hinges"
}
PUT /ecommerce/mf/2
{
"description":"Premium Round Sunglasses"
}
PUT /ecommerce/mf/3
{
"description":"Premium Fashion Full-Rim Frame"
}
PUT /ecommerce/mf/4
{
"description":"Premium Rectangular Fashionable Eyeglasses"
}
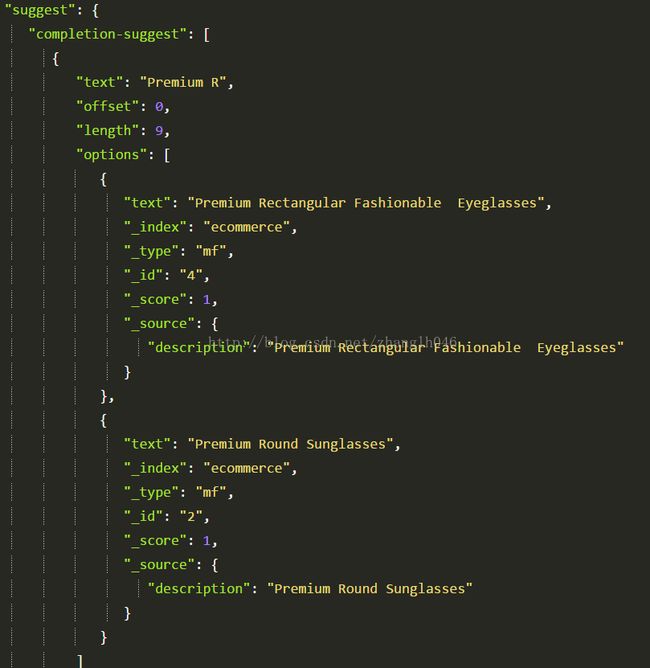
POST /ecommerce/mf/_search
{
"suggest":{
"completion-suggest":{
"prefix":"Premium R",
"completion":{
"field":"description"
}
}
}
}
参数选项:
analyzer:分词器,默认是simple,我们也可以修改为其他分词器
POST /ecommerce/mf/_search
{
"suggest":{
"completion-suggest":{
"prefix":"雅马哈电",
"completion":{
"field":"description",
"analyzer":"ik_max_word"
}
}
}
}
search_analyzer:默认就是analyzer
max_input_length: 限制单个输入的长度,默认为50.这个限制只在索引时使用,以减少每个输入字符串的字符总数
preserve_separators:保留的分隔符,如果我们设置为false,那么你可能找foof的时候找到了Foo Fighters,即中间有空格的也出现了
我们还可以向其他字段一样对suggestions进行索引,它是由input字段和weight字段组成,input是预期的文本,与suggestion查询匹配,权重决定建议如何得分
input: 可以是一个数组
weight: input里面的值的权重
PUT music/song/1?refresh
{
"suggest" : [
{
"input": "Nevermind",
"weight" : 10
},
{
"input": "Nirvana",
"weight" : 3
}
]
}
查询相关的参数
field: 指定从哪一个字段进行completion
size: 指定返回个数
prefix:指定前缀
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest"
}
}
}
}
如果是模糊匹配,即fuzzy query:
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nor",
"completion" : {
"field" : "suggest",
"fuzzy" : {
"fuzziness" : 2
}
}
}
}
}
fuzziness:表示模糊因子
min_length:在返回模糊建议之前,输入最小长度,默认值为3
prefix_length:最小长度的输入,没有检查的模糊选择,默认为1
如果正则查询:
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"regex" : "n[ever|i]r",
"completion" : {
"field" : "suggest"
}
}
}
}
flags: ALL(默认),ANYSTRING,COMPLEMENT,EMPTY,
INTERSECTION, INTERVAL, or NONE
max_determinized_states:正则表达式很危险,因为很容易意外地创建一个看起来无害的外观,它需要一个指数级的内部决定自动化状态(以及相应的RAM和CPU)来执行Lucene。Lucene通过使用max_UNK minized_states设置(默认为10000)来防止这些错误。您可以提高这个限制,允许执行更复杂的正则表达式。