随机森林算法(RandomForest)——运营商流失用户预测

如何最大程度地挽留在网用户、吸取新客户,是电信企业最关注的问题之一。竞争对手的促销、公司资费软着陆措施的出台和政策法规的不断变化,影响了客户消费心理和消费行为,导致客户的流失特征不断变化。对于电信运营商而言,流失会给电信企业带来市场占有率下降、营销成本增加、利润下降等一系列问题。在发展用户每月增加的同时,如何挽留和争取更多的用户,是一项非常重要的工作。本次比赛就是关于运营商流失用户预测的二分类问题。
话不多说,直接上代码(•̀ω•́)✧
import pandas as pd
pd.set_option("display.max_columns", None)
import numpy as np
from pprint import pprint
import warnings
warnings.filterwarnings("ignore")特征说明文档请见文末。
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()#查看数据维度
print(train.shape)
print(test.shape)
test["IS_LOST"] = 999
#将训练集与测试集合并做特征工程
all_data = pd.concat([train, test], ignore_index=True)
print(all_data.shape)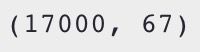
#查看用户编码与转网前编码是否存在相同
print(sum(all_data["USER_ID"] == all_data["USER_ID_OLD"]))![]()
#从渠道编码中提取特征(取前三位)
all_data["CHNL"] = all_data["CHNL_ID"].str[:3]
pprint(all_data["CHNL"].value_counts())
#改变CHNL中数值比例小的数据
all_data["CHNL"].where(all_data["CHNL"].isin(["11a", "11b"]), "11c", inplace=True)
pprint(all_data["CHNL"].value_counts())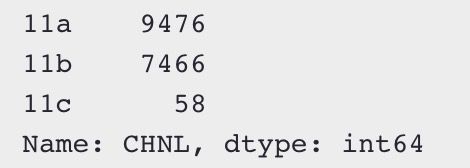
#删除无用的ID属性特征
all_data.drop(['CHNL_ID','TRANS_ID','CYCLE_ID','USER_ID','USER_ID_OLD','CUST_ID','DEVICE_NUMBER'], axis=1, inplace=True)
print(all_data.shape)![]()
特征数量由67减少到61。
#将部分数值特征转变为类别特征
trans_features = ["SERVICE_TYPE", "SERVICE_TYPE_OLD", "USER_STATUS", "LEVEL_A",
"LEVEL_B", "PAY_MODE", "IS_CARD", "IS_GROUP", "IS_INNET", "IS_LV",
"MANU_NAME", "IS_SMART", "NET_TYPE", "COMP_TYPE",
"ACTIVITY_TYPE", "IS_ACCT_AFT", "CHNL"]
for feature in trans_features:
all_data[feature] = all_data[feature].astype("category")接下来处理时间属性的特征。
有些时间值还有其他的异常表现,比如月份是00(正常月份最小值是01),所以需要对这些异常值变化为正常值。
#处理时间特征COMP_START_DATE、COMP_END_DATE、ACT_START_DATE、ACT_END_DATE
time_features = ["COMP_START_DATE", "COMP_END_DATE", "ACT_START_DATE", "ACT_END_DATE"]
for feature in time_features:
all_data[feature] = all_data[feature].astype(str).replace("0.0", "20000101")
all_data[feature] = all_data[feature].astype(str).replace("0", "20000101")pprint(all_data["ACT_START_DATE"].apply(lambda x: len(str(x))).value_counts())
还有的日期只记录到月份,无法直接转换为date格式,所以需要做处理,将所有日期为00的数据改为01(日期之差不变)。
for feature in time_features:
all_data.loc[all_data[feature]=="20200000000000.0", feature] = "20200100000000.0"编写时间特征处理函数,将时间字符串截取前6位(年份和月份),然后将end与start时间做差得到间隔时间来表征有效期特征。
#处理时间特征COMP_START_DATE、COMP_END_DATE、ACT_START_DATE、ACT_END_DATE
def get_year_and_period(df, features: list):
for feature in features:
start = f"{feature}_START_DATE"
end = f"{feature}_END_DATE"
df[f"{feature}_PERIOD(years)"] = (pd.to_datetime(df[end].apply(lambda x: x[:6]), format="%Y%m") -
pd.to_datetime(df[start].apply(lambda x: x[:6]), format="%Y%m")).dt.days / 365.0
df[start] = df[start].apply(lambda x: str(x)[:4])
df[end] = df[end].apply(lambda x: str(x)[:4])
return df知识点:pandas中的to_datetime的时间处理。
new_all_data = get_year_and_period(all_data, features=["COMP", "ACT"])卸磨杀驴,删除原始时间特征。
#删除COMP_START_DATE、COMP_END_DATE、ACT_START_DATE、ACT_END_DATE
new_all_data.drop(time_features, axis=1, inplace=True)对SERVICE_TYPE、SERVICE_TYPE_OLD、PRODUCT_ID、PRODUCT_CLASS建立新特征,新特征表征新旧TYPE、 PRODUCT_ID与PRODUCT_CLASS是否发生变化。
#对SERVICE_TYPE、SERVICE_TYPE_OLD、PRODUCT_ID、PRODUCT_CLASS建立新特征
new_all_data["IS_SERVICE_TYPE_EQUAL"] = (new_all_data["SERVICE_TYPE"] == new_all_data["SERVICE_TYPE_OLD"]).astype(int).astype("category")
new_all_data["IS_PRODUCT_EQUAL"] = (new_all_data["PRODUCT_ID"] == new_all_data["PRODUCT_CLASS"]).astype(int).astype("category")删除无用的"PRODUCT_CLASS", "PRODUCT_ID"特征。
new_all_data.drop(["PRODUCT_CLASS", "PRODUCT_ID"], axis=1, inplace=True)print(new_all_data.shape)![]()
对类别型特征做独热编码处理。
new_all_data = pd.get_dummies(new_all_data)
print(new_all_data.shape)![]()
最后将train与test分开,并将train分为训练集与验证集。
#划分训练集、验证集与测试集
train = new_all_data[new_all_data["IS_LOST"]!=999]
x_train = train.drop("IS_LOST", axis=1)
y_train = train["IS_LOST"]
train_X, valid_X, train_Y, valid_Y = train_test_split(x_train, y_train)
test_X = new_all_data[new_all_data["IS_LOST"]==999].drop("IS_LOST", axis=1)
print(train_X.shape)
print(valid_X.shape)
print(test_X.shape)
建立初始随机森林模型。
rf_model = RandomForestClassifier()
rf_model.fit(train_X, train_Y)
print(rf_model.score(valid_X, valid_Y))![]()
对测试集进行预测并保存结果。
prediction = rf_model.predict(test_X)
submits = test[['USER_ID']]
submits['IS_LOST'] = prediction
submits['IS_LOST'] = submits['IS_LOST'].apply(lambda x: int(1) if x>0.5 else int(0))
submits.to_csv('results.csv')
pprint(submits['IS_LOST'].value_counts())
本代码只进行了初级的特征工程,还并未对模型进行调参,这些方面就留给大家去挖掘啦!关注本公众号数据科学与人工智能技术发送“运营商”,或添加微信paixiaoseng即可获得本比赛的全部数据集~