双系统Ubuntu18.04安装以及一系列配置&错误处理方法
笔者原来的系统是win10,跑一些github上的例子总是设置这个设置那个,然后跑不起来,于是就想着装双系统,选择了ubuntu18.04版本,借的是同学的启动盘,
(1)Ubuntu18.04安装
如果大家也想自己制作启动盘,可以看这个链接:
Ubuntu18.04安装教程
需要注意的是,文中的分区过程过于繁琐,其实只需要把空出来的内存空间分两个区就行,一个是6GB的交换空间(swap,逻辑分区,空间起始位置),剩下的内存全部分到挂载点/,逻辑分区,空间起始位置,ext4,系统会自动分配,我们不用管那么多。
正常安装之后,结果安装了一半屏幕黑掉了,然后就重启了,好像也能进入系统,不过此时的ubuntu没有装完全,建议重新安装一下,安装完出现是否重启的选项的时候,我们再去重启。
(2)grub引导修复
重启之后,我们发现,哇,没能进到ubuntu,重启时会出现
error : unknow filesystem
grub rescue>
可以通过如下方法解决
ubuntu系统grub引导修复
当然啦,需要注意的是,我们进入了ubuntu系统之后,就不需要再按照他说的改这改那了,我们直接下载一个叫做boot-repair的工具,可以使用如下命令
连接网络后我们打开终端,依次输入下面的内容,每行之后都要按回车
sudo -i add-apt-repository ppa:yannubuntu/boot-repair && apt-get update
apt-get install -y boot-repair && boot-repair
第一行表示进入root账户模式
第二行添加软件源并更新系统
第三行为安装boot-repair并在安装完成后启动软件。
软件启动后自动扫描,会出现如下界面,选择recommended repair
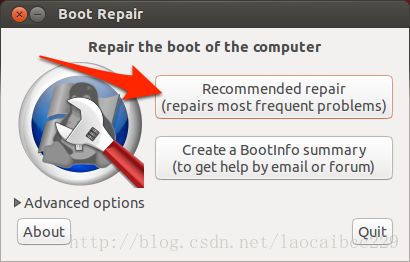
按照boot repair提示的操作进行,完成后重启电脑即可完成。
如果需要修改文件,可能会需要使用vim,命令很简单,sudo apt-get install vim即可
(3)开机之后,发现电脑没声音
ubuntu16耳机没声音解决
(4)无法连接上 dl.google.com:80 (6.6.6.6)
发现apt-get update的时候报了连接不上谷歌服务器的错误,这个时候需要我们修改hosts,具体方法如下
无法连接上 dl.google.com:80 (6.6.6.6)
(5)ubuntu18.04无法连接网络
然后呢,我浏览了一会火狐浏览器,发现突然上不了网了,无论是重启电脑还是设置什么dns什么乱七八糟的都没有用,最后我找到了解决方法
win10+ubuntu16.04双系统网络问题(win10可以上网,ubuntu上不了网)
其中我遇到的问题解决办法是禁用windows网络(关闭windows网络自动唤醒功能),也就是他的方法2,马上就见效了。
(6)ubuntu安装NVIDIA显卡驱动
接下来,我发现登陆的时候鼠标移动到用户上面会卡一下,原因是我们没有安装显卡驱动,安装下卡驱动的方法如下:
ubuntu16.04系统run方式安装nvidia显卡驱动
ubuntu显卡驱动安装
当然也有其他的办法,大家可以自行百度
上面的方法会要求你关掉lightdm服务,但是我的版本里好像没有,那么也很简单
sudo apt install lightdm
安装过程中,会提示缺少gcc以及make工具,大家可以使用如下命令进行安装
键入以下命令安装build-essential软件包:
$ sudo apt install build-essential
该命令将安装一堆新包,包括gcc,g ++和make
当然也可以单独使用sudo apt install gcc==4.8安装某种特定版本的包。
安装完成重新启动即可。
(7)Ubuntu安装CUDA和CUDNN
显卡驱动装完了,我们要想在GPU上面跑程序的话,需要安装cuda和cudnn,笔者打算使用tensorflow1.14版本,我们可以在下面看到对应关系
tensorflow CUDA cudnn 版本对应关系
可以看到我需要下载cuda10.0,我们先到NVIDIA官网下载cuda10.0,这里建议选择runfile,点击下方的下载,下载完之后按照下面的步骤执行即可
安装CUDA-10.0
之后安装cudnn,到官网找到cuda10.0对应的版本下载即可,操作过程也可以看下面链接
ubuntu安装cudnn
安装完之后,我们可以输入如下命令查看cuda和cudnn版本
cuda一般安装在 /usr/local/cuda/ 路径下,该路径下有一个version.txt文档,里面记录了cuda的版本信息
cat /usr/local/cuda/version.txt
即可查询
同理,cudnn的信息在其头文件里
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
即可查询
(8)Ubuntu安装python环境——anaconda3以及pycharm
接下来我们安装anaconda3,也是很简单,按照下面链接操作
Ubuntu18.04 安装 Anaconda3
然后我们安装编译器pycharm,具体操作方式如下:
Ubuntu18安装pycharm
安装完之后需要讲pycharm配置上anaconda3的环境
Pycharm 2018.3 中导入Anaconda3创建的环境
搞定之后我们开始下载tensorflow,因为有gpu嘛,所以我们使用的是tensorflow-gpu,输入以下命令下载
pip install tensorflow-gpu==1.14
可能会报以下错误,我们可以一一解决
(1)Could not dlopen library 'libcublas.so.10.0'这一类的错误
解决办法:Could not dlopen library 'libcublas.so.10.0'这一类的错误,有很多人说重装cuda10,如果按照上面的步骤,不需要重装,只是链接文件找不到而已。
(2)tensorboard 1.14.0 has requirement setuptools>=41.0.0, but you'll have setuptools 40.6.3,
Cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall
解决方法:忽略掉重装就行,大家可以到这里查看具体步骤:【异常】tensorboard 1.14.0 has requirement setuptools>=41.0.0, but you'll have setuptools 40.6.3
(3)pip更新以及更换pip源
更新pip
python -m pip install --upgrade pip
更改pip源
创建目录:sudo mkdir ~/.pip
创建文件:sudo gedit ~/.pip/pip.conf
将以下内容保存到文件中,建议使用清华的源
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
安装设置超时间(安装pillow的时候需要)
pip --default-timeout=100 install -U Pillow
搞定了之后,我们到tensorflow官网跑个例子试一下gpu是否完美工作
Basic classification: Classify images of clothing
照着复制下来,然后开始运行,可能会报这个错误(点击查看解决方法)
Tensorflow: CUDA_ERROR_OUT_OF_MEMORY
如下运行成功!
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties:
name: GeForce RTX 2060 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815
pciBusID: 0000:01:00.0
2019-12-26 10:19:38.346425: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.0
2019-12-26 10:19:38.548043: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10.0
2019-12-26 10:19:38.683216: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcufft.so.10.0
2019-12-26 10:19:38.737698: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcurand.so.10.0
2019-12-26 10:19:38.959835: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusolver.so.10.0
2019-12-26 10:19:39.082605: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcusparse.so.10.0
2019-12-26 10:19:39.476582: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7
2019-12-26 10:19:39.476708: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-12-26 10:19:39.477060: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-12-26 10:19:39.477326: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0
2019-12-26 10:19:39.488916: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudart.so.10.0
2019-12-26 10:19:39.500532: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-12-26 10:19:39.500556: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0
2019-12-26 10:19:39.500562: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N
2019-12-26 10:19:39.500715: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-12-26 10:19:39.501093: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1005] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-12-26 10:19:39.501384: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7219 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2060 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
Epoch 1/10
2019-12-26 10:19:46.567665: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10.0