Python描述数据结构之数组实战篇
文章目录
- 前言
- 1. LeetCode1:两数之和
- 2. LeetCode26:删除排序数组中的重复项
- 3. LeetCode27:移除元素
- 4. LeetCode35:搜索插入位置
- 5. LeetCode88:合并两个有序数组
- 6. LeetCode169:多数元素
- 7. LeetCode217:存在重复元素
- 结束语
前言
在Python描述的数据结构中,字典的时间复杂度相对来说比列表的时间复杂度更小,所以与数组有关的一些题目,用字典进行操作会更快,这里给出一些有关字典的基本操作,与列表有关的操作请参阅我的这篇博客。
| 方法 | 功能 |
|---|---|
| clear() | 删除字典中所有元素 |
| copy() | 返回字典的副本 |
| fromkeys(seq[, val]) | 创建一个新字典,以序列 s e q seq seq中的元素做字典的键, v a l val val为字典所有键对应的初始值 |
| get(key, default=None) | 返回指定键的值,如果键不存在返回 d e f a u l t default default值 |
| has_key(key) | 如果键在字典里返回 T r u e True True,否则返回 F a l s e False False |
| items() | 返回一个列表,元素是一个二元组 ( k e y , v a l u e ) (key,value) (key,value),即字典里所有的键值对 |
| keys() | 返回一个列表,元素是字典里所有的键 |
| values() | 返回一个列表,元素是字典里所有的值 |
| setdefault(key, default=None) | 如果键不存在,将添加键并将值设为 d e f a u l t default default |
| update(dict1) | 把字典dict1的键值对更新到字典里 |
| pop(key[,default]) | 删除字典中给定键 k e y key key所对应的值,返回值为被删除的值。如果 k e y key key不存在,则返回 d e f a u l t default default值 |
| popitem() | 返回并删除字典中的最后一个键值对 |
LeetCode中有关数组的题目。
1. LeetCode1:两数之和
LeetCode第1题:两数之和。
数组转字典,因为字典的运算比数组快些。题目中要求是要返回数组的下标,既然这样,那就先将数组转成字典,即 { ′ i n d e x ′ : \{'index': {′index′: ′ v a l u e ′ } 'value'\} ′value′},然后将字典的关键字与值对换,即 { ′ v a l u e ′ : \{'value': {′value′: ′ i n d e x ′ } 'index'\} ′index′},这里可以通过zip()函数来实现,然后就可以去字典里找这两个相加之和等于 t a r g e t target target的 i n d e x index index就行。我这里的做法就是定一个值,然后去字典里找另一个值,如果存在,且这两个值的 i n d e x index index不同,即满足条件,返回这两个数组下标。
代码实现如下:
def twoSum(nums, target):
nums_dict = {}
for index in range(len(nums)):
nums_dict[index] = nums[index]
# {'value': 'index'}
nums_dict = dict(zip(nums_dict.values(), nums_dict.keys()))
for i, value in enumerate(nums):
j = nums_dict.get(target-value, 0)
if j != 0 and j != i:
return [i, j]
运行结果如下:
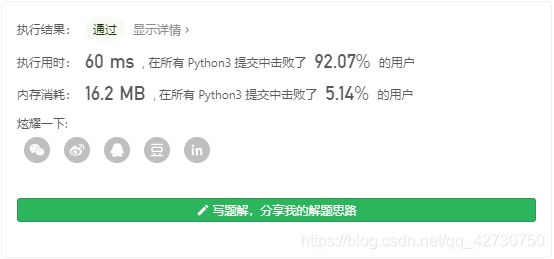
2. LeetCode26:删除排序数组中的重复项
LeetCode第26题:删除排序数组中的重复项。
这个题有两个点需要注意:
(1) 必须原地修改数组,包含的信息就是数组必须修改,而且只能原地修改,所以是不能直接用set()函数去重的;
(2) 你不需要考虑数组中超出新长度后面的元素,这个信息是在示例中给出的,意思就是我们直接把不重复的元素挪到数组最前面即可,所以不用使用len()、remove()或del。
综上,使用双指针是个不错的选择(貌似目前除此之外,我还没有其他想法( ・´ω`・ )),双指针,一前一后嘛。如果前面指针的数与后面指针的数相等,后面指针加1,前面指针不变;若前面指针的数与后面指针的数不相等,前面指针加1,后面指针不变,最后返回 i + 1 i+1 i+1,即不重复的数组长度。
代码实现如下:
def removeDuplicates(nums):
i = 0
j = 1
while j < len(nums):
if nums[i] == nums[j]:
j += 1
else:
i += 1
nums[i] = nums[j]
return i + 1
运行结果如下:

3. LeetCode27:移除元素
LeetCode第27题:移除元素。
这个题与上面那个题基本一致,这里我仍然采用双指针,不过刚开始指针并不是一前一后,而是在一个起点上。如果后面指针的数与 v a l val val相等,后面指针加1;如果后面指针的数与 v a l val val不相等,将后面指针的数赋值给前面指针指的位置,然后前面指针和后面指针都加1,最后返回 i i i,即不等于 v a l val val的数组长度。
代码实现如下:
def removeElement(nums, val):
i = 0
j = 0
while j < len(nums):
if nums[j] == val:
j += 1
else:
nums[i] = nums[j]
i += 1
j += 1
return i
运行结果如下:
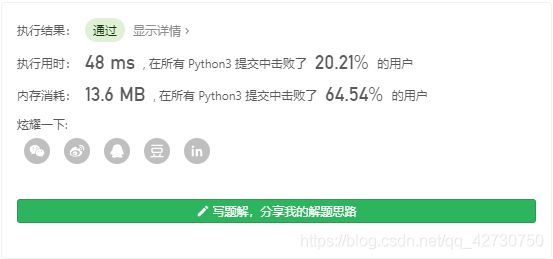
在Python中用了 48 m s 48ms 48ms只击败了 20 % 20\% 20%的用户⊙(・◇・)?,看来这个题还有更好的方法来解决丫(ノ゚∀゚)ノ
4. LeetCode35:搜索插入位置
LeetCode第35题:搜索插入位置。
这个题官方有说排序数组中无重复元素,还说如果目标不存在,要返回按顺序插入的位置,所以用find()或index()函数查找索引就不大方便了,目标值存在还行,不存在就要遍历两次,不如干脆一遍过。
代码实现如下:
def searchInsert(nums, target):
for index in range(len(nums)):
if nums[index] >= target:
return index
return len(nums)
没错,就是酱紫,如果目标值 t a r g e t target target在数组之中,就直接返回当前索引,如果目标值 t a r g e t target target不在数组之中,就返回可以插入位置的索引,在数组最前面或中间插入返回的是当前索引,在数组尾部插入返回的是数组的长度。
运行结果如下:
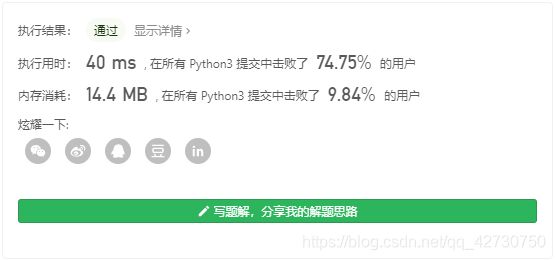
5. LeetCode88:合并两个有序数组
LeetCode第88题:合并两个有序数组。
这个题官方给的也是有序数组,所以可以直接先将数组合并,然后利用sort()或sorted()函数排序。
代码实现如下:
def merge(nums1, m, nums2, n):
# nums1[:] = nums1[:m] + nums2
# nums1.sort()
nums1[:] = sorted(nums1[:m] + nums2)
运行结果如下:
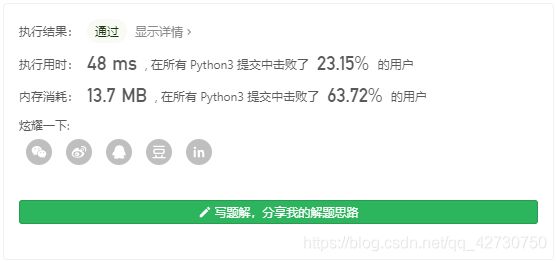
在Python描述数据结构之链表实战篇这篇文章中介绍过一道与之非常相似的题目,它合并的是两个有序链表,用的是双指针,本题也可以如此。
代码实现如下:
def merge(nums1, m, nums2, n):
new_nums1 = nums1[:m]
# 将nums1清空, 然后就可以用append()方法添加数组
# 否则需要再多引入一个变量来指示当前nums1数组中已排好序的位置
nums1[:] = []
pre1 = 0
pre2 = 0
while pre1 < m and pre2 < n:
if new_nums1[pre1] <= nums2[pre2]:
nums1.append(new_nums1[pre1])
pre1 += 1
else:
nums1.append(nums2[pre2])
pre2 += 1
# 将剩余的元素直接加入nums1中
nums1[pre1+pre2:] = new_nums1[pre1:] if pre1 < m else nums2[pre2:]
运行结果如下:

6. LeetCode169:多数元素
LeetCode第169题:多数元素。
这里就直接使用了collections库里的Counter类,简单介绍一下:
| 方法 | 功能 |
|---|---|
| collections.Counter(iterable) | 初始化 C o u n t e r Counter Counter对象 |
| elements() | 返回一个迭代器(无序),每个元素重复的次数就是它的个数,如果元素的个数或值小于1,该元素不被返回 |
| most_common([n]) | 返回一个列表(降序),其中包含最常见的前 n n n个元素及出现的次数,默认返回 C o u n t e r Counter Counter中左右的元素 |
| subtract(iterable) | 两个可迭代对象中或者映射(或 C o u n t e r Counter Counter),元素的次数相减 |
| update(iterable) | 两个可迭代对象中或者映射(或 C o u n t e r Counter Counter),元素的次数相加 |
def majorityElement(nums):
from collections import Counter
result = Counter(nums).most_common(1)
return result[0][0]
运行结果如下:
enmmmm,结果不大好啊,那我们直接构造一个吧。构造一个字典,数组中的元素作为字典的 k e y key key,元素的个数作为字典的 v a l u e value value,然后按 v a l u e value value进行排序;或者使用zip()先反转字典再排序,前者效果应该会更好一些,代码如下:
def majorityElement(nums):
dict1 = {}
for num in nums:
dict1[num] = dict1.get(num, 0) + 1
result = sorted(dict1.items(), key=lambda item: item[1], reverse=True)
return result[0][0]
运行结果如下:
7. LeetCode217:存在重复元素
LeetCode第217题:存在重复元素。
这个题和上面那个题有很大的相似性,这里也是构造一个字典,数组中的元素作为字典的 k e y key key,元素的个数作为字典的 v a l u e value value,然后判断 v a l u e value value有没有大于等于2的,有的话就返回 T r u e True True,否则就返回 F a l s e False False。这里还发现了一个小技巧,就是如果字典里的 v a l u e value value之和大于字典的长度,就说明数组存在重复元素。
代码实现如下:
def containsDuplicate(nums):
dict1 = {}
for num in nums:
dict1[num] = dict1.get(num, 0) + 1
if sum(list(dict1.values())) > len(dict1):
return True
else:
return False
运行结果如下:

上面的算法其实还可以做一下优化,我们不需要遍历整个数组来构造字典,只需要遍历到第二次出现同样的 k e y key key即可,即最坏的情况下才是遍历整个数组。
代码实现如下:
def containsDuplicate(nums):
dict1 = {}
for num in nums:
if not dict1.get(num, 0):
dict1[num] = dict1.get(num, 0) + 1
else:
return True
return False
运行结果如下:

当然,最简单的就是集合啦!将数组转换成集合,只需要判断集合的长度与数组的长度是否相等即可。
代码实现如下:
def containsDuplicate(nums):
return True if len(set(nums)) < len(nums) else False
运行结果如下:
结束语
数组其实还是挺难的,它可能会涉及到好多种数据结构和算法,有好多些题所涉及的算法目前还没有接触到,所以本篇也只是挑了些简单题练练手(~ ̄▽ ̄)~继续加油(ง •̀_•́)ง