微软熊辰炎:如何利用图神经网络解决半结构化数据问题?
对于许多信息检索和知识图谱研究者来说,究竟应该使用抽象的结构化信息进行表示学习还是使用海量的文本信息始终是一个富有争议的话题。在本届智源大会上,来自微软研究院的高级研究员熊辰炎博士带来了题为“利用半结构化知识的表示学习与信息检索”的主题报告,结合其近年来在 ICLR、ACL、WebConf 上发表的相关工作,介绍了如何从半结构化知识的视角同时利用符号知识与纯文本信息,从而提升表征性能与效率。

熊辰炎
熊辰炎,微软研究院高级研究员。主要研究方向:信息检索,自然语言处理和深度学习的结果。近期研究兴趣是长文本里面,对话信息检索和深度信息检索等。2018年卡耐基梅隆大学语言技术研究所博士。在信息检索,自然语言处理,深度学习等会议上发表论文30余篇。参与组织多次相关领域研讨会,宣讲会,以及美国国家标准局TREC竞赛等。
尽管本次演讲的标题中没有「图神经网络」等字眼,但其内容都围绕图神经网络展开。本次演讲将侧重于实际的问题、知识以及工业界常用任务中的半结构化数据,探讨如何利用图神经网络对半结构化数据进行表示学习,以及如何使用较为统一的框架解决实际中的问题。
本次演讲的内容主要分为两部分,首先,我们将从统一的「半结构化」的视角讨论知识图谱以及各种信息检索任务(例如,问答系统、事实验证、假新闻检测、信息搜索);接着,我将介绍我们近期提出的一种 Transformer 模型,它能够整合各种不同任务的信息,并学习其表征,从而完成这些任务。

整理:智源社区 熊宇轩
一、知识和信息检索任务的「半结构化」视角

图 1:符号知识 vs. 自由的纯文本信息
在知识工程与自然语言表征学习领域,往往有两种对信息建模的视角。首先,对于许多任务来说,我们拥有的是结构化的数据(即符号化的知识),知识图谱就是其中一种形式。例如,图中每个节点都是一个命名实体,实体之间的边代表关系。另一方面,在有的任务中,信息则存在于原始的纯文本之中。
这两种建模信息的方式各有千秋。一方面,结构化数据十分干净而精确,数据十分规整,我们可以在这种该结构化数据上进行各种推理,或者基于它们开发一些可执行的程序(如 SQL 查询,或图数据库的查找或搜索)。然而,构建结构化数据的成本是很高的,并且现实世界中的一些信息也很难被表示成这种规整的结构。
而对于纯文本信息来说,可以使用的语料的数据量往往非常大,我们可以利用各种自然语言处理(NLP)技术处理这些文本(例如,信息提取、文本表征)。然而,纯文本信息往往不够精准,存在各种噪声,其结构也不太明显,这不利于我们进行后续的操作。
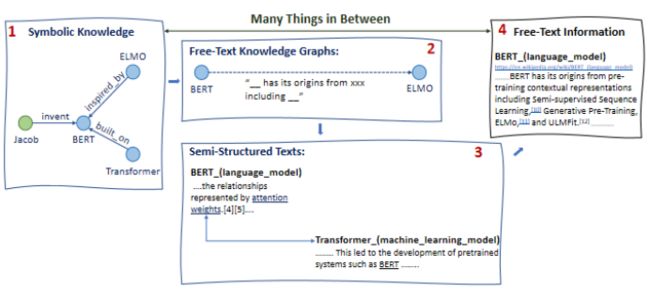
图 2:半结构化信息
我们认为,许多信息处于结构化数据与纯文本数据之间,我们将其称为「半结构化」数据。
举例而言,对于知识图谱来说,我们可以对知识图谱进行一定的松弛(例如,用某些纯文本作为边)。而对于文本信息来说,文档之间可能存在各种各样的关系,我们可以将这些文档作为图谱中的各个节点,用各种关系边将它们相连。如上图所示,1→4 展示了我们如何一步步将结构化符号信息松弛为纯文本信息的层次化过程。
二、Free-Text Knowledge Graph
如今,研究人员开发了各种各样包含大量优质信息的知识图谱(例如,Freebase、Wikipedia)。然而,真实场景下有很多并不完全针对这些知识图谱设计的实际问题,我们应该如何将这些知识图谱应用于这类问题呢(例如,将知识图谱引入网页搜索引擎,从而提升文档排序的性能)?
实际上,要实现这一目标仍然存在许多挑战,其中最主要的一个挑战是:由于进行信息提取和知识图谱扩容是相对困难的,因此其召回率往往较低。例如,某系统中仅仅 1% 的流量数据可以被知识图谱中的边覆盖,无论我们在 1% 的流量上执行某任务的效果有多好,其对整体系统的影响仍然十分有限。
尽管如此,我们发现知识图谱对于命名实体(通常为节点)的覆盖率仍然是很高的。2015 年,我在一个实际的网页语料库上使用各种实体链接,从而观察每个查询或文档中包含多少个实体。实验结果表明,在大约只有 2-3 个词的查询中,平均覆盖了高达 1.5 个实体;而在大约有 500 个单词的文档中,平均覆盖了约 252 个实体。几乎所有的查询、文档都包含至少一个实体。当我在 Allen 人工智能研究院实习时,我也对其 SemanticScholar 的查询上使用了实体链接,我惊讶地发现有高达 70% 的学术搜索查询在 Freebase 或 Wikipedia 这种非学术的通用知识图谱上有相对应的实体。
此外,从新的文本中抽取出实体也并非十分困难。例如,新冠疫情爆发后,学者们发表了大约 10 万篇相关的医学论文,我们直接将基于 BERT 的关键词标注器(并未在医学领域上进行预训练)应用于跨领域、零样本的关键词抽取。实验结果表明,该关键词标注器确实能够抽取出重要的关键词。
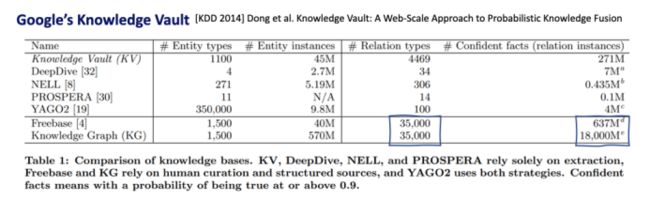
图 3:覆盖关系更为困难
然而,覆盖关系(知识图谱中的边)相较于覆盖实体来说要更为困难,对边的召回率往往要低一些。Google 研究院在 Knowledge Vault 上的实验表明,其使用的本体非常多,其关系边的数目也很多,但是其边的类型相较于 Freebase 并没有改变(仍然为 35,000 种边),这是因为定义边的关系类型是十分困难的。

图 4:关系符合长尾分布
在许多实际问题中,实体之间的关系实际上满足具有严重长尾效应的分布。如上图所示,在实际的视觉问答系统数据集中,左侧的实体「The little street」是一幅画,画的内容是右侧荷兰小城 Delft 的街景, 这两个实体在维基百科中都可以很容易找到。但是,此时我们希望识别这两个实体之间的关系(paints the view of),并用资源描述框架(RDF) 将其记录下来。

图 5:关系构建的处理流程
为了构建一个可以覆盖该关系的知识图谱,我们需要即熟悉 RDF 的模式,又了解艺术的本体学家(Ontologist)来定义该关系,而这种人才往往很稀缺。接着,我们需要通过信息提取技术从纯文本中抽取出相应的(实体、关系、实体)三元组,而能够顺利通过上面提到的整个处理流程的关系实际上并不多。

图 6:Free-Text 知识图谱
实际上,这里的纯文本本身就存在于维基百科或其它语料库中,上述复杂的处理流程费时费力,不一定能够满足一些具有时效性的任务的需求。因此,我们考虑跳过上述流程中的一些步骤,不再要求边是规整的关系,转为使用各种半结构化的边(句子)。近年来,许多知识图谱领域的研究者们认为「整个互联网就是我们的知识库」,这种半结构化的思想在近期发表的一些论文中也有体现。因此,要构建这种 Free-Text 知识图谱,我们首先找出已有的实体,然后在网页语料库中使用实体链接,将所有包含该实体的句子抽取出来,基于这些句子和实体连成一张图,从而提升关系的召回率。由此得到的图是覆盖率非常高的密集图。

图7:在问答系统数据集上的 Free-text 知识图谱的覆盖率
针对 qbLink 数据集,我们在 DBpedia 知识图谱上从核心实体开始,沿着其边游走,我们发现在 2 步之内有 38% 的概率找出对应的答案,我们可以将 38% 看做仅仅使用 DBpedia 这种基于纯结构化数据的知识图谱时所能达到的覆盖率上限。而如果我们将句子作为图谱中的边,那么有 80%-90% 的答案可以被找到,此时召回率明显提升。
然而,此时图的规模可能会非常大,噪声非常多,与每个实体、答案相连的边数会显著增长,而其中可能存在大量无效的路径。此外,每条边可能对应于很多的句子,而这些句子可能良莠不齐。因此,我们虽然突破率覆盖率的瓶颈,但是引入了更多的噪声。幸运的是,我们可以使用图神经网络很好地处理这些信息,具体处理方式将在后半段演讲中介绍。如何设计模型从这种噪声较大的图中提取信息是一个有待研究的方向。
如图2 中第 2 步与第 3 步所示,这种半结构化的形式化定义的适用范围非常广泛。例如,在事实验证和假新闻检测任务中,我们需要根据语料库(如维基百科)中的文档和段落(证据)验证声明(claim)的真实性,给出「真」(support)、「假」(Refute)、「信息不足无法验证」(Not Enough INFO)其中的一种结果。该任务可能需要综合考虑多篇文档的信息,因此对于该任务而言,我们可以将声明与纯文本证据作为 Free-Text,将语料库中的证据之间的推理链条、共现、超链接、指代关系等作为结构关系,从而构建半结构化数据。

图 8:文档排序问题
在搜索引擎的文档排序问题中,当我们输入一条查询时,搜索引擎会检索出若干文档,我们需要在语料库中找到这些文档并对它们进行排序,输出一个排序得分。此时,在构建半结构化数据的过程中,我们可以将查询与文档作为 Free-Text,而将文档内部的层次化语法结构、 文档之间的关系(相似、全局相关性等)作为结构关系。
在多跳问答系统中,我们需要利用多种树状结构、链式结构的信息作为证据。在构建半结构化数据时,我们使用不同文本之间隐含的推理关系、超链接、相关性作为结构关系。
三、Transformer-XH
为了统一地解决面向半结构化数据的任务(QA、文档排序、事实验证等),我们可以使用 Transformer 类模型(如图注意力网络 GAT、BERT 等)对这种半结构化数据进行建模。
在多头注意力机制中,对于节点、单词等表征,我们通过注意力机制来更新它们,得到更复杂、能够表达全局语义的信息表征形式。对于每一个注意力层而言,面对从下一层输入的表征,用查询权值矩阵、键权值矩阵、值权值矩阵与该输入相乘,再将这种投影作为查询向量、键向量、值向量。当网络对某个单词进行表征时,会使用该单词的查询向量 q_i 与每个单词的键向量 k_j 相乘得,再对其乘积进行softmax 操作得到加权和为 1 的注意力得分,用该得分将所有单词的值 v_j 结合在一起,用最后计算的结果更新该单词的表征。
这种自注意力机制是非常普适的。例如在 GAT 中,我们会沿着已有的图中的边,构建注意力路径,对节点之间的关系进行建模;对于 BERT 而言,我们可以将其视作一个全连接的词袋图。
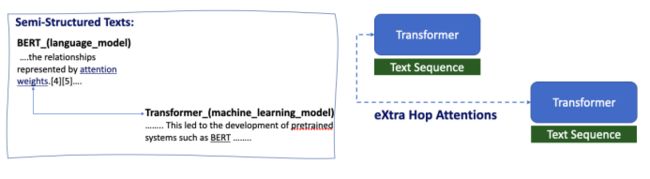
图 9:Transformer-XH:eXtra-Hop Attention
在我们于 ICLR 2020 上发表的论文「Transformer-XH: Modeling Semi-structured Information with eXtra-Hop Attentions」中,我们用 Transformer 类的模型(如 BERT)生成文本块的表征嵌入,再用 eXtra-Hop 注意力将这些文本的嵌入联系起来。这相当于一个双层结构,在每一个文本内部,我们使用全连接的 GAT 对每个词之间的关系建模,而在不同的文本序列之间,我们也会利用 eXtra-Hop 注意力建立与 GAT 相类似的注意力路径,这是一种 Transformer(BERT)+GNN 的模式。

图 10:Transformer-XH 的形式化定义
对于文本序列节点 {d_1,...,d_τ,...,d_ξ},我们会用一些邻接矩阵记录将这些文本序列连接起来的边,该模型旨在综合考虑各节点、各文本序列之间的信息,输出每个节点上的表征。该模型与普通 Transformer 的区别在于,我们用 τ 表示某一个文本序列的编号,每个文本序列独立使用一套查询、键、值投影矩阵。此外,我们还将每一个文本序列第一个位置上的特殊标记 [CLS] 作为注意力中心(attention hub),将其与其它文本的注意力中心通过 eXtra hop 注意力相连。通过以上机制,我们可以同时考虑本文序列内部各词例(token)之间的关系表征,以及其它文本序列的 [CLS] 的信息表征,对这两部分表征进行连接(concatenate)后再对进行线性投影。
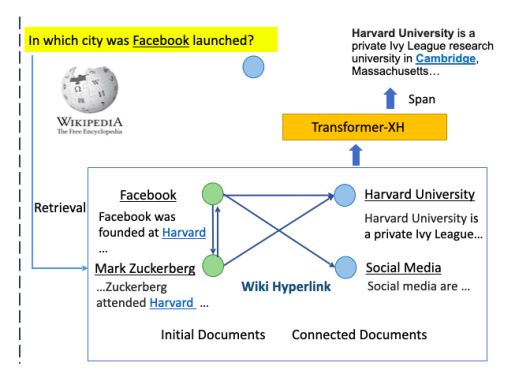
图 11:使用多文档信息提取答案区间(answer span)
在具体的多跳 QA 任务中,针对上图黄色方框中的查询,我们检索出了若干文档,沿着维基百科的超链接扩展出相应的文档节点。接着,我们整合所有文档的信息,通过 Transformer-XH 得到表征,将其表征用于提取答案区间。具体而言,我们会在Transformer-XH 的最后一层后面接上一个阅读理解(MRC)任务常用的预测层,用于预测答案区间的开始于结束位置。
在进行事实验证时,针对一个声明(claim),我们检索出与其相关的若干文档,通过与提取答案区间任务中相似的方式生成文档表征。针对这一任务,我们预测每个文档起始位置节点 [CLS] 的标签,作为节点级别的分类概率。接着,我们学习出各 [CLS] 节点的权重,对它们进行加权平均,从而完成事实验证任务。
因此,对于面向半结构数据的任务而言,底层的表征模型都是类似的,都需要将词、关系输入到基于注意力的表征模型中,而我们重点关注的是上层针对特定任务的层如何设计。
Hotpot QA 是由 CMU、MILA 等单位发布的针对多跳问答系统开发的数据集,旨在向亚马逊的众包「土耳其机器人」提供两个段落的文本,要求他们写出一些需要利用这两个才能回答的问题,而最后确实有大约一半的问题需要用到多个段落的信息。

图 12:在 Hotpot QA 数据集上的实验结果
相较于使用纯粹的基于 GNN (将每个文档的嵌入输入到 GNN 中)或 Free-text(进行精准化的文本检索,将检索结果连接在一起,输入到 BERT、RoBerta等模型中进行阅读理解) 的模型,我们提出的 Transformer-XH 是一种更为简单的模型,它将原始的半结构化数据作为输入,从而得到目标表征,Transformer-XH 最终的性能效果往往更优。
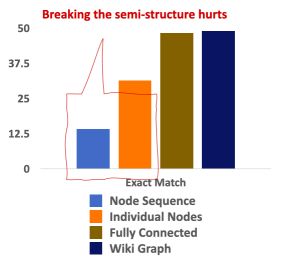
图 13:结构对模型性能的影响;使用不同文档图结构时的性能对比
如上图所示,相较于我们提出的模型(深蓝色),当我们使用独立的节点(橙色)时,模型性能几乎减半。当我们使用错误的结构(浅蓝色,如链式关系)时,性能相较于使用独立节点的情况甚至更差。这说明,正确的结构信息缺失对于提升模型性能很有帮助。
此外,对于 Hotpot QA 数据集而言,由于其保证在写问题时的两个真实段落之间必定存在维基百科中的链接,因此维基百科中的信息对其性能的影响十分巨大。但是,当使用我们的 Transformer-XH 时,我们甚至可以不使用维基百科的信息,即使使用一个全联通的图进行学习就可以得到与使用维基百科时相近的结果。因此,我们的方法可以自动推断出边的重要性。
在图神经网络中,每一层中的节点可以聚合其邻居节点的信息(一跳),而网络的层数决定了每个节点可以聚合信息的范围。实验结果表明,当我们使用三层 Transformer 的注意力机制时,模型性能最优。这是因为 Hotpot QA 大多数是 2 跳的,当网络层数继续上升时,往往难以进行学习。

图 14:全联通状态下不同节点之间的注意力权重
在这里,我们考虑三种节点之间的连边:(1)任意两个文档之间的边(2)所有节点与实际包含答案的节点相连的边(3)包含关键信息的节点到包含答案的节点之间的边。如上图所示,当使用一跳信息时,注意力权值的概率密度分布近似为均值为 1 的较为集中的「瘦高」高斯分布;当使用两跳信息时,概率密度分布变得较为「矮胖」,模型可以将边的重要性区分开来。由于我们希望 Transformer-XH 能够从文章中提取出有助于确定答案区间的信息,所以我们最关注红色的实线。而在使用三跳信息时,红色实线的值相较于另外两种边确实越来越大,说明 Transformer-XH 确实能够学习到推理的关系。
四、结语
综上所述,对于知识图谱、语义信息的处理,以及一些现实中的信息检索任务都可以看做是一种针对半结构化数据的问题。「如何结合结构化符号知识与纯文本信息」这一问题仍然有很大的研究空间。
我们可以用 Transformer、BERT 等模型对半结构化数据进行建模和表征(在文本节点内部运用 BERT 的思想,在文本节点之间运用 GAT 的思想),针对具体的任务设计后续的网络层。
点击阅读原文,进入智源社区观看本次演讲视频、参与互动讨论
关于我们
北京智源人工智能研究院(Beijing Academy of Artificial Intelligence,简称BAAI)成立于2018年11月,是在科技部和北京市委市政府的指导和支持下,由北京市科委和海淀区政府推动成立的新型研发机构。
//智源研究院简介
///
学术思想 | 基础理论 | 顶尖人才 | 企业创新 | 发展政策
