python scrapy 获取NBA东部赛区排名情况
目标数据:
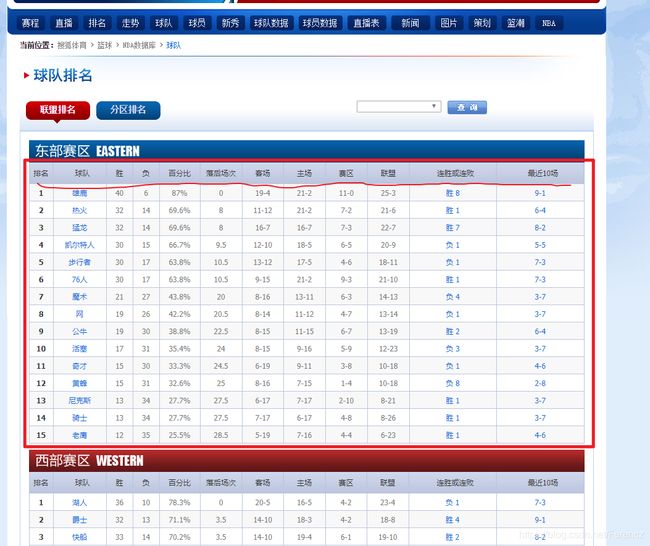
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NbaItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
foot = scrapy.Field()
win = scrapy.Field()
defeat = scrapy.Field()
percent = scrapy.Field()
#落后场次
lhcx = scrapy.Field()
kechang = scrapy.Field()
zhuchang = scrapy.Field()
saiqu = scrapy.Field()
lianmeng = scrapy.Field()
lian = scrapy.Field()
zuijin10 = scrapy.Field()
spider
# -*- coding: utf-8 -*-
import scrapy
from nba.items import NbaItem
class NnSpider(scrapy.Spider):
name = 'nn'
allowed_domains = ['data.sports.sohu.com']
start_urls = ['http://data.sports.sohu.com/nba/nba_teams_rank.html?']
def parse(self, response):
item = NbaItem()
dates = response.xpath(
'//div[@class="east"]/div[@class="tab"]/table/tr')
i = 0
for date_s in dates:
i = i+1
if i == 1:
pass
else:
item['name'] = "\t" + \
date_s.xpath('td[@class="e1"]/text()').extract()[0]
item['foot'] = "\t" + \
date_s.xpath('td[@class="e2"]/a/text()').extract()[0]
item['win'] = "\t" + \
date_s.xpath('td[@class="e3"][1]/text()').extract()[0]
item['defeat'] = "\t" + \
date_s.xpath('td[@class="e3"][2]/text()').extract()[0]
item['percent'] = "\t" + \
date_s.xpath('td[@class="e4"]/text()').extract()[0]
item['lhcx'] = "\t" + \
date_s.xpath('td[@class="e5"][1]/text()').extract()[0]
item['kechang'] = "\t" + \
date_s.xpath('td[@class="e5"][2]/text()').extract()[0]
item['zhuchang'] = "\t" + \
date_s.xpath('td[@class="e5"][3]/text()').extract()[0]
item['saiqu'] = "\t" + \
date_s.xpath('td[@class="e5"][4]/text()').extract()[0]
item['lianmeng'] = "\t" + \
date_s.xpath('td[@class="e5"][5]/text()').extract()[0]
item['zuijin10'] = "\t" + \
date_s.xpath('td[@class="e6"][2]/text()').extract()[0]
item['lian'] = "\t"+date_s.xpath('td[@class="e6"][1]/text()').extract()[0].replace(
"\r", "").replace("\n", "").replace("\t", "").replace("\xa0", "").replace(" ", "")
yield item
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import csv
import time
class NbaPipeline(object):
def open_spider(self,spider):
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.f = open('{}.csv'.format(time.strftime("%Y-%m-%d_%H_%M_%S")+'_NBA'),"w",newline="")
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
self.fieldnames = ['name','foot','win','defeat','percent','lhcx','kechang','zhuchang','saiqu','lianmeng','zuijin10','lian']
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close_spider(self,spider):
self.f.close()
settings
# -*- coding: utf-8 -*-
# Scrapy settings for nba project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'nba'
SPIDER_MODULES = ['nba.spiders']
NEWSPIDER_MODULE = 'nba.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'nba.middlewares.NbaSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'nba.middlewares.NbaDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'nba.pipelines.NbaPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
源码下载:https://download.csdn.net/download/Ferencz/12122448