CS231N-8&9-Deep Learning Hard/Software & CNN Case Study
- Hardware
- Framework
- Tensorflow
- PyTorch
- Static vs Dynamic Graphs
- Conclusion
- CNN Case Study
- AlexNet 2012 Montreal
- VGGNet 2014 Oxford
- GoogleNet 2015 Google
- ResNet 2016 MSRA
- Others
今日议程:deep learning的软硬件。
关于Framework的细节,就不展开了,只要掌握个概念,等到具体实践时选用某一框架如Tensorflow or PyTorch时,再深入研究。
机器之心有本讲的介绍,见官网.

Hardware
硬件主要指CPU vs GPU.
对GPU有个感性认识,超级大。

这张表格特别好,囊括了CPU和GPU的比较特点。GPU胜在超级多的core,弥补主频低,独立的分层内存,适用大规模并行项目:如矩阵乘法。
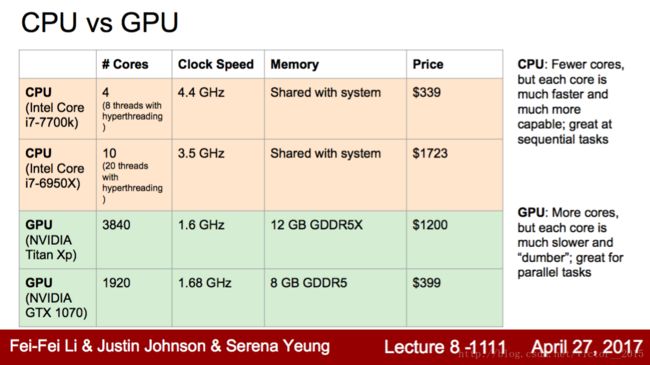
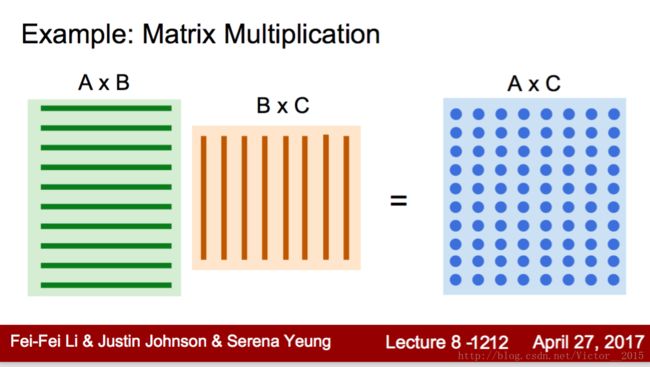
每个核并行计算自己的向量乘法,完成矩阵乘法。
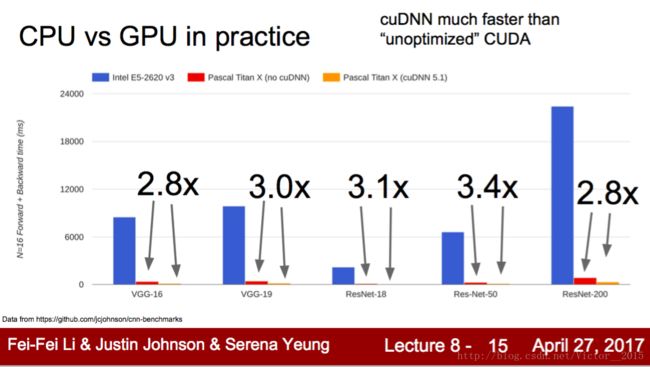
但光有GPU也不够,需要GPU programming,即如何硬件加速,以满足高效deep learning需求。一家独大的NVIDIA不仅胜在GPU性能好,更是有软件包CUDA,专门为dl加速的库CUDNN。

这是比较,GPU经过硬件加速,比CPU快70倍。

另外,将数据集从硬盘移到主存,也会加快速度,这个移动可以让空闲的CPU并行完成,同时GPU在计算。 现在framework已经将此实现。

Framework


过去一年,deep learning framework有了质的飞跃。第一代是学术界发明的,如caffe from UCB, Torch from NYU, Theano from Montreal,但在过去两年,caffe2, Pytorch from Facebook, Tensorflow from Google,取代了对应的第一代。可以说,academia作为首创,掀起波澜后,industry接过大旗,给予质的飞跃。这堂课就聚焦于prevailing PyTorch和TF。另外,这位优秀的博士,朋友圈,以及face++老师说Pytorch是基于dynamic computation graph,比其他static的优雅elegant,无需规定shape,调试方便,推荐使用(tensorflow如今四面楚歌)。
好了,PyTorch就是了。

我们知道python的numpy很优雅,可以方便地计算矩阵,但是numpy对于深度学习而言,两大致命缺陷:
- 无法自动计算梯度:auto differentiation. 需要手动计算,wow太复杂了,容易出错。
- 无法在GPU上加速运行:只支持CPU. 绝望,训练慢了70倍。
于是framework就解决了上述问题:
- 和numpy一样,构建computation graph,但更专业与自动
- 能自动计算梯度!解放程序员的脑力
tf.gradientsbackwards - 能在GPU上且支持CUDA运行!好快
下面介绍Tensorflow.

Tensorflow
代码都用python实现。首先是import
import numpy as np
import tensorflow as tf
将代码分成两大部分
- First define computational graph. 定义计算图,只运行一次,都是symbolic variable。
- Then run the graph many times. 然后运行计算图多次。
定义计算图:
- 使用
tf.placeholder函数,定义输入及权重的shape和类型,中间变量无需定义,通过矩阵乘法推断出来。 - 使用
tf.matmul等函数,构建计算图,并给出loss表达式 - 使用
tf.gradients函数给出梯度
注意定义部分没有任何计算!No computation!

运行计算图:
从
with tf.Session() as sess:开始,标志着进入运行态session通过
numpy的数据结构如array输入到tf.placeholder中定义的变量,作为初始值- 使用
sess.run([output array],feed_dict=values)来run the graph. output array是我们希望输出的 - to train the network, run the graph over and over, use gradient to update weights. 即for循环,迭代更新权值
但是在实际训练中,由于每次取和更新w,都需要从CPU memory 到GPU memory,故需要换种写法:

- w权值用
tf.Variable定义,一直live in the graph,而placeholder是每次call喂给feed 给graph. - 既然w是
Variablelive in the graph,那么它的更新方式也要在定义给出,即w1.assign(...) - 在运行计算图中,初始化Variable w,
sess.run(tf.global_variables_initializer()). - 在循环中sess.run loss和weights(虚拟结点?),注意
tf.group
optimizer 再议。
tf.layer函数

Tensorboard 可视化
Keras 是基于 Tensorflow/Theano 的又一次封装,比较容易上手。

PyTorch






- Tensors: 简单来说,就是Numpy+GPU,即普通的数组,但使用
cuda就能运行在GPU上。但和深度学习无直接关系,即需要手动计算梯度。 - Variable: 是计算图的节点,autograd,自动计算梯度
x.grad,而且tensor和variable可以转换,而且有一样的API。 - nn: 类似Keras,对tf的高层封装。
torch.nn.,虽然只有一个,但很方便。 - model: 自己写的模型… 略过
- torchvision还能调用著名的模型666
- Visdom: 类似tensorboard的可视化
Torch是PyTorch的前身,基于Lua语言,不能Autograd,不太用了…

Static vs Dynamic Graphs
face++老师在提到PyTorch优点是dynamic graph,现在就仔细比较下。

- Static: build graph once, then run many times: Tensorflow
- Dynamic: Each forward pass defines a new graph: PyTorch
Static Graph的优点:
- Optimisation: 由于预定义了图,故可以优化图的结构,加快速度。如fuse Conv+ReLU.
- Serialization: 不需要带着代码运行?用c++代替python?没看懂
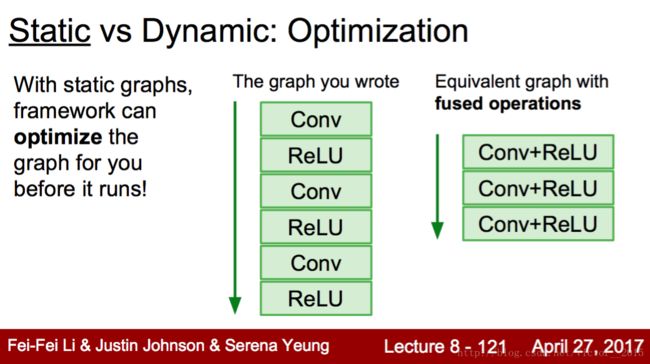

Dynamic Graph的优点:
- Conditional: 条件分支,pytorch直接用python control flow,很简单自然;但tf要预先定义好,故使用tf自带的cond函数,语法复杂
- Loops: 循环。同理,pytorch用Python control flow. 但tf有自己的语言
- 故适合RNN


Conclusion
之后博士简短地介绍了caffe,好像是CSS语法?反正被一周前发布的caffe2淹没了。Google希望tf大一统,而fb分成研究的pytorch和生产的caffe2,将研发分离。caffe2对移动端很支持。

最后的建议。
CNN Case Study
本讲介绍CNN架构。主要是ImageNet比赛获胜的按时序的四个著名架构。以及其他有趣的架构。建议快速看完,读论文时再细究。

AlexNet 2012 Montreal

推导一遍每层之后的size大小,有助于理解。注意各种超参数的设定。
VGGNet 2014 Oxford
AlexNet - > VGG: VGG可以看成是加深版本的AlexNet. 都是conv layer + FC layer.

VGG的改进除了deeper layers,主要是将卷积核设定为 3∗3 ,stride为1,这种最小的filter使得层数变深。虽然3个三乘三的reception field和1个七乘七是一样的(每卷积层使得视野增加2),但参数数量更少,而且Non-linearity增强。

细节架构略。
GoogleNet 2015 Google
Network in Network -> GoogLeNet: NIN本身大家可能不太熟悉,但是我个人觉得是蛮不错的工作,Lin Min挺厉害。GoogLeNet这篇论文里面也对NIN大为赞赏。NIN利用Global average pooling去掉了FC layer, 大大减少了模型大小,本身的网络套网络的结构,也激发了后来的GoogLeNet里面的各种sub-network和inception结构的设计.
作者:周博磊
链接:https://www.zhihu.com/question/43370067/answer/128881262
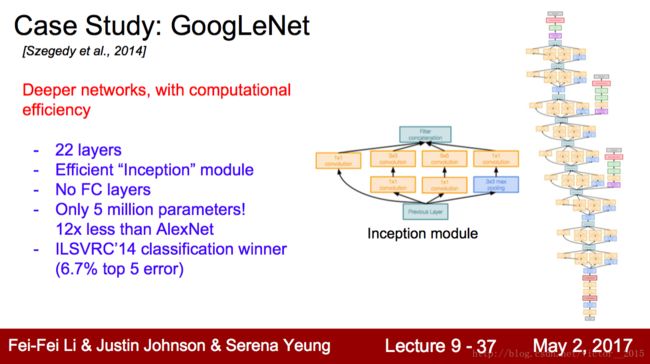
去除了参数繁多的FC layer,采用Inception module(本身是个神经网络),借鉴了Network in Network思想。参数减少。
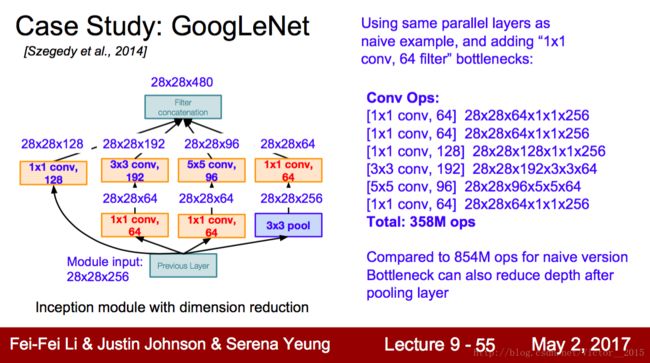
这是Inception module的解剖图。注意这里的 1∗1 卷积核的应用,使得参数大幅减少(如果去掉,卷积核的深度很大),计算量也随之减少。
ResNet 2016 MSRA
这个网络跟前面几个网络都不同。我清楚记得这篇论文是在去年年底我去开NIPS的时候release到arxiv上的。当时我开会间歇中看着论文里面在cifar上面的一千层的resnet都目瞪狗呆了。。。然后再看到ResNet刷出了imagenet和COCO各个比赛的冠军,当时就觉得如果这论文是投CVPR, 那是绝对没有争议的Best paper, 果不其然。好像resnet后来又有些争议,说resnet跟highway network很像啥的,或者跟RNN结构类似,但都不可动摇ResNet对Computer Vision的里程碑贡献。当然,训练这些网络,还有些非常重要的trick, 如dropout, batch normalization等也功不可没。等我有时间了可以再写写这些tricks。
作者:周博磊


上面的胶片展现了ResNet灵感的来源。
ResNet的第一个特点是152 layers. 于是我们就问:神经网络是否越深越好?在计算资源允许下。
答案竟是否定的。实践表明,56层在train&test error上都比20层的差。为什么?
何凯明的猜想:归根结底,图像识别是个优化问题,但太深的网络难以优化。
如果我们把深层的神经网络多出来的层都identity mapping(恒等映射),那应该结果至少和浅层网络一样好。这是解决深层网络无法优化最naive的办法。
但网络总是要学习的,你总不能让深层的网络不变吧。那我们学习什么,在保留identity mapping 思想情况下?学习residual,学习 H(X)−X=F(X) ,学习扣除X本身的差值。这样能大幅帮助深层网络的优化。
知乎上这个解释很好,残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器.
F是求和前网络映射,H是从输入到求和后的网络映射。
比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。
比如原来是从5.1到5.2,映射F’的输出增加了1/51=2%,而对于残差结构从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。
残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…
作者:theone
链接:https://www.zhihu.com/question/53224378/answer/159102095
另一位知乎答主:
resnet最初的想法是在训练集上,深层网络不应该比浅层网络差,因为只需要深层网络多的那些层做恒等映射就简化为了浅层网络。
所以从学习恒等映射这点出发,考虑到网络要学习一个F(x)=x的映射比学习F(x)=0的映射更难,所以可以把网络结构设计成H(x) = F(x) + x,这样就即完成了恒等映射的学习,又降低了学习难度。
作者:未雨绸缪
链接:https://www.zhihu.com/question/53224378/answer/163755266
这种体现思想的结构图:
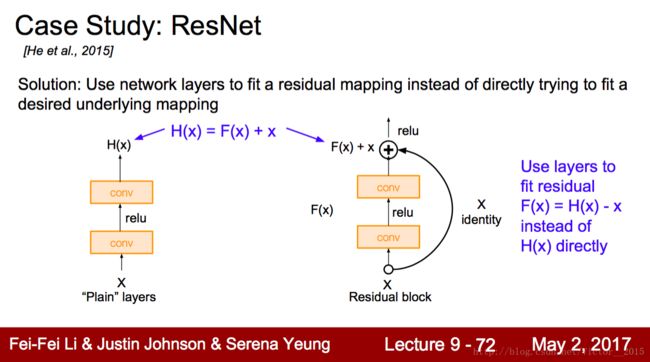
另外,值得一提的是,这种残差设计使得正则化变得可解释,即让权值趋于0时,相当于identity mapping.
残差的设计使得bp梯度计算也变得容易,直接就传递回来了。
以上是小哥哥博士的话,比小姐姐讲得好。
细节略(借鉴GoogleNet的 1∗1 卷积核)
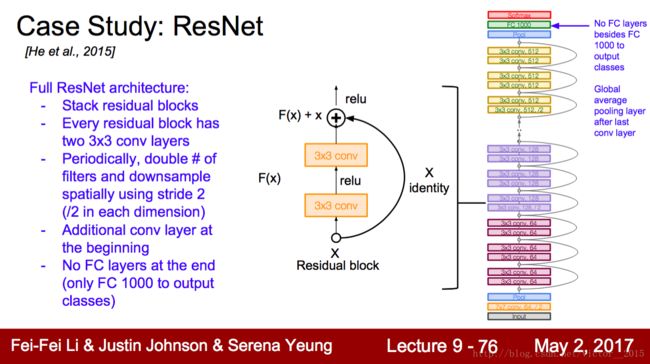

Others
Improving ResNet papers. Omitted.

It is no use stacking layers into deep NN. GoogleNet给我们的启示是增加width并行卷积,减少参数和计算量,但正确率却有提高,效率最高(正确率/计算量)。而ResNet给我们的启示是优化问题的本质,研究残差residual。故流行趋势是width和residual.