这么设计,Redis 10亿数据量只需要100MB内存

来源:www.toutiao.com/i6767642839267410445
本文主要和大家分享一下redis的高级特性:bit位操作。
本文redis试验代码基于如下环境:
操作系统:Mac OS 64位 版本:Redis 5.0.7 64 bit 运行模式:standalone mode
redis位操作
reids位操作也叫位数组操作、bitmap,它提供了SETBIT、GETBIT、BITCOUNT、BITTOP四个命令用于操作二进制位数组。
先来看一波基本操作示例:
SETBIT
语法:SETBIT key offset value
即:命令 key 偏移量 0/1
setbit命令用于写入位数组指定偏移量的二进制位设置值,偏移量从0开始计数,且只允许写入1或者0,如果写入非0和1的值则写入失败:

GETBIT
语法:GETBIT key offset
即:命令 key 偏移量
gitbit命令用于获取位数组指定偏移量上的二进制值:

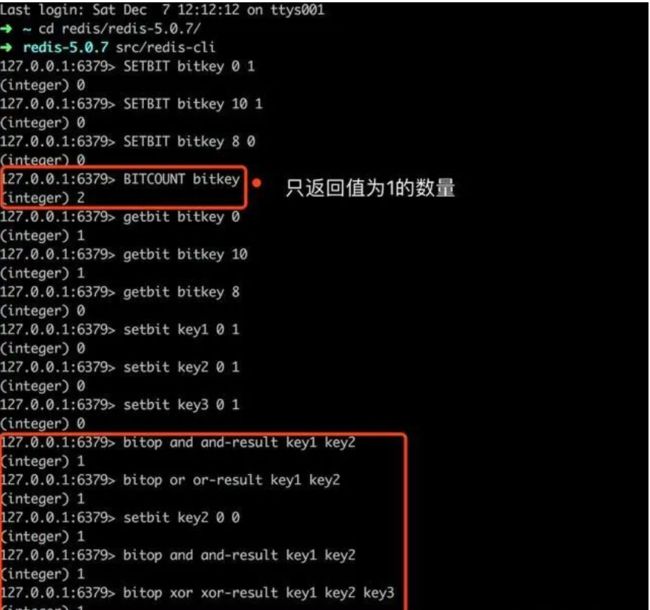
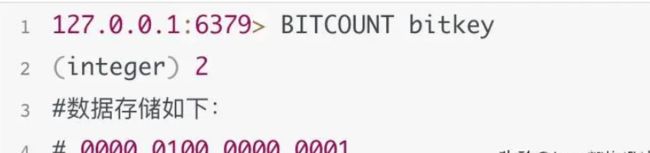
BITCOUNT
语法:BITCOUNT key
即:命令 key
bitcount命令用于获取指定key的位数组中值为1的二进制位的数量,之前我们写入了偏移量0的值为1,偏移量10 的值为1,偏移量8的值为0:
BITOP
语法:BITOP operation destkey key [key…]
即:命令 操作 结果目标key key1 key2 …
bitop命令可以对多个位数组的key进行and(按位与)、or(按位或)、xor(按位异或)运算,并将运算结果设置到destkey中:

底层数据结构分析
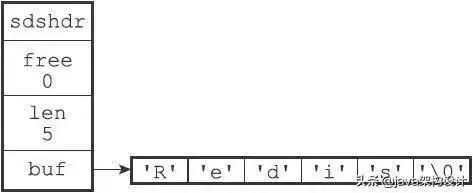
SDS是redis中的一种数据结构,叫做简单动态字符串(Simple Dynamic String),并且它是一种二进制安全的,在大多数的情况下redis中的字符串都用SDS来存储。
SDS的数据结构:
struct sdshdr {
#记录buff数组中已使用字节的数量
#也是SDS所保存字符串的长度
int len;
#记录buff数组中未使用字节的数量
int free;
#字节数组,字符串就存储在这个数组里
char buff\[\];
}
数据存储示例:
SDS的优点:
时间复杂度为O(1)
杜绝缓冲区溢出
减少修改字符串长度时候所需的内存重分配次数
二进制安全的API操作
兼容部分C字符串函数
redis中的位数组采用的是String字符串数据格式来存储,而字符串对象使用的正是上文说的SDS简单动态字符串数据结构。
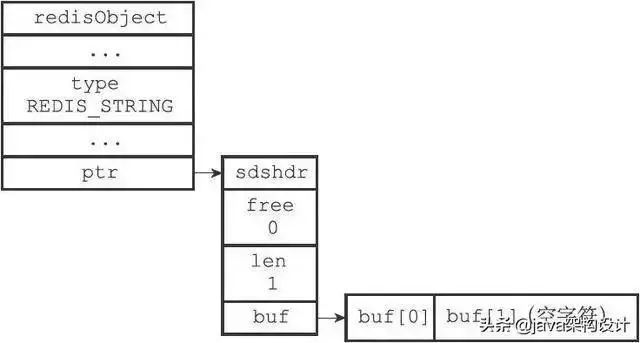
大家都知道的是一个字节用的是8个二进制位来存储的,也就是8个0或者1,即一个字节可以存储十进制0~127的数字,也即包含了所有的数字、英文大小写字母以及标点符号。
1Byte=8bit 1KB=1024Byte 1MB=1024KB 1GB=1024MB
位数组在redis存储世界里,每一个字节也是8位,初始都是:
0 0 0 0 0 0 0 0
而位操作就是在对应的offset偏移量上设置0或者1,比如将第3位设置为1,即:
0 0 0 0 1 0 0 0
#对应redis操作即:
setbit key 3 1
在此基础上,如果要在偏移量为13的位置设置1,即:
setbit key 13 1
#对应redis中的存储为:
0 0 1 0 | 0 0 0 0 | 0 0 0 0 | 1 0 0 0
时间复杂度
GETBIT命令时间复杂度O(1)
STEBIT命令时间复杂度O(1)
BITCOUNT命令时间复杂度O(n)
BITOP命令时间复杂度O(n)、O(n2)
我们来看GETBIT以及SETBIT命令的时间复杂度为什么是O(1),当我们执行一个SETBIT key 10086 1的值的时候,reids的计算方式如下:
获取到要写入位数组中的哪个字节:10086÷8=1260,需要写入到位数组的下标1260的字节
获取要写入到这个字节的第几位:10086 mod 8 = 6,需要写入到这个字节的下标为6即第7位上去。
通过这两种计算方式大家可以清晰的看到,位操作的GETBIT和SETBIT都是常量计算,因此它的时间复杂度为O(1)。
而BITCOUNT命令需要对整个位数组的所有元素进行遍历算出值为1的有多少个,当然redis对于大数据了的bit执行bitcount命令会有一整套复杂的优化的算法,但是核心思路还是这个意思,无非是减少部分遍历查询次数。比如以128位为一次遍历,那么他的遍历次数就是所有的位数除以128。
BITTOP命令则是根据不同的操作有不同的执行方式。比如AND操作,则需要查看位值为1的即可。
存储空间计算
根据上面的介绍,相信大家已经知道了基于redis的位数组数据结构存储的数据占用内存大小是怎么计算的了。比如有100亿的数据,那么它需要的字节数组:
1000000000÷8÷1024÷1024≈119.21MB
也就是存储10亿的数据只需要119MB左右的内存空间,这对于现在动辄16G、32G集群版的redis,完全没有问题。
需要注意的是,如果你的数据量不大,那就不要把起始偏移量搞的很大,这样也是占空间的,比如我们只需要存储几百条数据,但是其中的偏移量却很大,这就会造成了很大的内存空间浪费。
应用场景
实际项目开发中有很多业务都适合采用redis的bit来实现。
用户签到场景
每天的日期字符串作为一个key,用户Id作为offset,统计每天用户的签到情况,总的用户签到数
活跃用户数统计
用户日活、月活、留存率等均可以用redis位数组来存储,还是以每天的日期作为key,用户活跃了就写入offset为用户id的位值1。
同理月活也是如此。
用户是否在线以及总在线人数统计
同样是使用一个位数组,用户的id映射偏移量,在线标识为1,下线标识为0。即可实现用户上下线查询和总在线人数的统计
APP内用户的全局消息提示小红点
现在大多数的APP里都有站内信的功能,当有消息的时候,则提示一个小红点,代表用户有新的消息。
推荐阅读
阿里精选:Java 代码精简之道
Java8 中用法优雅的 Stream,性能也""优雅""吗?
ElasticSearch 索引 VS MySQL 索引
还在手动部署SpringBoot应用?试试这个自动化插件!
MySQL执行计划Explain详解
