来点干货 | Android 常见内存泄漏与优化(二)


作者 | 无名之辈FTER
责编 | 夕颜
出品 | CSDN(ID:CSDNnews)
在昨天的Android 内存泄漏问题多多,怎么优化?一文中,我们详细阐述了Java虚拟机工作原理和Android开发中常见的内存泄漏及其优化方法,本文将在此基础上继续学习Android虚拟机发展历程、Dalvik/ART的运行时堆、Dalvik/ART启动流程以及常见的内存分析工具的特点和使用方法,包括Android Profiler、MAT、LeakCanary等。

Android虚拟机:Dalvik和ART
Dalvik是Google特别设计专门用于Android平台的虚拟机,它位于Android系统架构的Android的运行环境(Android Runtime)中,是Android移动设备平台的核心组成部分之一。类似于传统的JVM,Dalvik虚拟机是在Android操作系统上虚拟出来的一个“设备”,用来运行Android应用程序(APP),主要负责堆栈管理、线程管理、安全及异常管理、垃圾回收、对象的生命周期管理等。在Android系统中,每一个APP对应着一个Dalvik虚拟机实例。
Dalvik虚拟机支持.dex(即"Dalvik Executable")格式的Java应用程序的运行,.dex是专为Dalvik设计的一种压缩格式,它是在.class字节码文件的基础上经过DEX工具压缩、优化后得到的,适用于内存和处理器速度有限的系统。在Android 4.4以前的系统中,Android系统均采用Dalvik作为运行Android应用的虚拟机,但随着Dalvik的不足逐渐暴露,到Android 5.0以后的系统使用ART虚拟机完全取代了Dalvik虚拟机。ART虚拟机在性能上做了很多优化,比如采用预编译(AOT,Ahead Of Time compilation)取代JIT编译器、支持64位CPU、改进垃圾回收机制等等,从而使得Android系统运行更为流畅。
下图展示了Android系统架构和DVM架构:

Android虚拟机的使用,使得Android应用和Linux内核分离,从而使得Android系统更加稳定可靠,也就是说,即便是某个Android程序被嵌入了恶意代码,也不会直接影响系统的正常运行。接下来,我们就从分析JVM、Dalvik、ART三者之间的关系,来进一步了解它们。
1.1 JVM与Dalvik区别
在Android 4.4以前,Android中的所有Java程序都是运行在Dalvik虚拟机上的,每个Android应用进程对应着一个独立的Dalvik虚拟机实例并在其解释下执行。虽然Dalvik虚拟机也是用来运行Java程序,但是它并没有遵守Java虚拟机规范来实现,是Google为Android平台特殊设计且运行在Android 运行时库的虚拟机,因此Dalvik虚拟机并不是一个Java虚拟机。它们的主要区别如下:
(1) 基于的架构不同
JVM基于栈架构,Dalvik虚拟机基于寄存器架构。JVM基于栈则意味着需要去栈中读写数据,所需更多的指令会更多(主要是load/store指令),这样会导致速度变慢,对于性能有限的移动设备,显然是不合适的;Dalvik虚拟机基于寄存器实现,则意味着它的指令会更加紧凑、简洁,因为虚拟机在复制数据时不需要使用大量的出入栈指令,但由于需要指定源地址和目标地址,所以基于寄存器的指令会比基于栈的指令要大,当然,由于指令数量的减少,总的代码数不会增加多少。下图的一段Java程序代码,展示了在JVM和Dalvik虚拟机中字节码的表现形式:
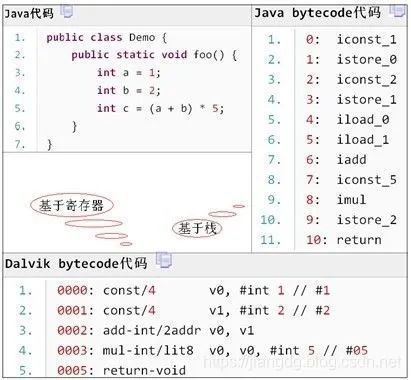
Java字节码以单字节(1 byte)为单元,JVM使用的指令只占1个单元;Dalvik字节码以双字节(2 byte)为单元,Dalvik虚拟机使用的指令占1个单元或2个单元。因此,在上面的代码中JVM字节码占11个单元=11字节,Dalvik字节码占6个单元=12字节(其中,mul-int/lit8指令占2单元)。
(2) 执行的字节码文件不同
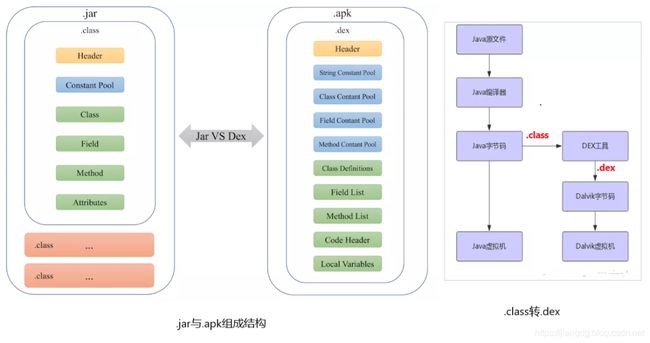
JVM运行的.class文件,Dalvik运行的是.dex(即Dalvik Executable)文件。在Java程序中,Java类会编译成一个或多个.class文件,然后打包到.jar文件中,.jar文件中的每个.class文件里面包含了该类的常量池、类信息、属性等。当JVM加载该.jar文件时,会加载里面的所有的.class文件,JVM的这种加载方式很慢,对于内存有限的移动设备并不合适;.dex文件是在.class文件的基础上,经过DEX工具压缩和优化后形成的,通常每一个.apk文件中只包含了一个.dex,这个.dex文件将所有的.class里面所包含的信息全部整合在一起了,这样做的好处就是减少了整体的文件尺寸(去除了.class文件中相同的冗余信息),同时减少了I/O操作,加快了类的查找速度。下图展示了.jar和.dex的对比差异:
(3) 在内存中的表现形式差异
Dalvik经过优化,允许在有限的内存中同时运行多个进程,或说同时运行多个Dalvik虚拟机的实例。在Android中每一个应用都运行在一个Dalvik虚拟机实例中,每一个Dalvik虚拟机实例都运行在一个独立的进程空间中,因此都对应着一个独立的进程,独立的进程可以防止在虚拟机崩溃时所有程序都被关闭。而对于JVM来说,在其宿主OS的内存中只运行着一个JVM的实例,这个JVM实例中可以运行多个Java应用程序(进程),但是一旦JVM异常崩溃,就会导致运行在其中的所有程序被关闭。
(4) Dalvik拥有Zygote进程与共享机制
在Android系统中有个一特殊的虚拟机进程--Zygote,它是虚拟机实例的孵化器。它在Android系统启动的时候就会产生,完成虚拟机的初始化、库的加载、预制类库和初始化操作。如果系统需要一个新的虚拟机实例,他会迅速复制自身,以最快的速度提供给系统。对于一些只读的系统库,所有的虚拟机实例都和Zygote共享一块区域。Dalvik虚拟机拥有预加载-共享的机制,使得不同的应用之间在运行时可以共享相同的类,因此拥有更高的效率。而JVM则不存在这个共享机制,不同的程序被打包后都是彼此独立的,即便它们在包里使用了相同的类,运行时的都是单独加载和运行,无法进行共享。
1.2 Dalvik与ART区别
ART虚拟机被引入于Android 4.4,用来替换Dalvik虚拟机,以缓解Dalvik虚拟机的运行机制导致Android应用运行变慢的问题。在Android 4.4中,可以选择使用Dalvik还是ART,而从Android 5.0开始,Dalvik被完全删除,Android系统默认采用ART。Dalvik与ART的主要区别如下:
(1) ART运行机制优于Dalvik
对于运行在Dalvik虚拟机实例中的应用程序而言,在每一次重新运行的时候,都需要将字节码通过JIT(Just-In-Time)编译器编译成机器码,这会使用应用程序的运行效率降低,虽然Dalvik虚拟机已经被做过很多优化(.dex文件->.odex文件),但由于这种先翻译再执行的机制仍然无法有效解决Dalvik拖慢Android应用运行的事实。而在ART中,系统在安装应用程序时会进行一次AOT(Ahead Of Time compilication,预编译),即将字节码预先编译成机器码并存储在本地,这样应用程序每次运行时就不需要执行编译了,运行效率会大大提高。

(2) 支持的CPU架构不同
Dalvik是为32位CPU设计的,而ART支持64位并兼容32位的CPU。
(3) 运行时堆划分不同
Dalvik虚拟机的运行时堆使用标记--清除(Mark--Sweep)算法进行GC,它由两个Space以及多个辅助数据结构组成,两个Space分别是Zygote Space(Zygote Heap)和Allocation Space(Active Heap)。Zygote Space用来管理Zygote进程在启动过程中预加载和创建的各种对象,Zygote Space中不会触发GC,应用进程和Zygote进程之间会共享Zygote Space。Zygote进程在fork第一个子进程之前,会把Zygote Space分为两个部分,原来被Zygote进程使用的部分仍然叫Zygote Space,而剩余未被使用的部分被称为Allocation Space,以后fork的子进程相关的所有的对象都会在Allocation Space上进行分配和释放。需要注意的是,Allocation Space不是进程共享的,在每个进程中都独立拥有一份。下图展示了Dalvik虚拟机的运行时堆结构:
与Dalvik的GC不同,ART采用了多种垃圾收集方案,每个方案会运行不同的垃圾收集器,默认是采用了CMS(Concurrent Mark-Sweep)方案,该方案主要使用了sticky-CMS和patial-CMS。根据不同的CMS方案,ART的运行时堆的空间划分也会不同,默认是由4个Space和多个辅助数据结构组成,4个Space分别是Zygote Space、Allocation Space、Image Space以及Large Object Space,其中,Zygote Space和Allocation Space和Dalvik的一样,Image Space用来存放一些预加载类,Large Object Space用来分配一些大对象(默认大小为12Kb)。需要注意的是,Zygote Space和Image Space是进程间共享的。下图展示了ART采用标记–清除算法的堆划分:

ART虚拟机的不足:
安装时间变长。应用在安装的时候需要预编译,从而增大了安装时间。
存储空间变大。ART引入AOT技术后,需要更多的空间存储预编译后的机器码。
因此,从某些程度上来说,ART虚拟机是利用了“空间换时间”,来提高Android应用的运行速度。为了缓解上述的不足,Android7.0(N)版本中的ART加入了即时编译器JIT,作为AOT的一个补充,在应用程序安装时并不会将字节码全部编译成机器码,而是在运行中将热点代码编译成机器码,具体来说,就是当我们第一次运行应用相关程序后,JIT提供了一套追踪机制来决定哪一部分代码需要在手机处于idle状态和充电的时候来编译,并将编译得到的机器码存储到本地,这个追踪技术被称为Profile Guided Compilcation。
1.3 Dalvik/ART的启动流程
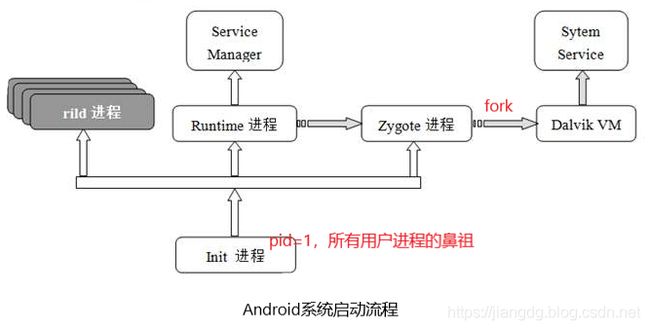
从剖析Android系统的启动过程一文可知,init进程(pid=1)是Linux系统的用户进程,是所有用户进程的父进程。当Android系统在启动init进程后,该进程会孵化出一堆用户守护进程、ServiceManager服务以及Zygote进程等等,其中,Zygote进程是Android系统启动的第一个Java进程,或者说是虚拟机进程,因为它持有Dalvik或ART的实例。Zygote进程是所有Java进程的父进程,每当系统需要创建一个应用程序时,Zygote进程就会fork自身,并快速地创建和初始化一个虚拟机实例,用于应用程序的运行。下面我们就从Android9.0源码的角度,来分析Zygote进程中的Dalvik或ART虚拟机实例是如何创建的。
首先,根据init.rc的启动服务的命令,将运行/system/bin/app_process可执行程序来启动zygote进程,该可执行程序对应的源文件为../base/cmds/app_process/app_main.cpp,也就是说,当从init进程发起启动Zygote进程后,会调用app_main.cpp的main函数进入Zygote进程的启动流程。app_main.cpp的main函数源码如下:
//app_main.cpp$main函数int main(int argc, char* const argv[]){ ... // (1) 创建AppRuntime对象 AppRuntime runtime(argv[0], computeArgBlockSize(argc, argv)); ... // (2) 解析执行init.rc的启动服务的命令传入的参数 // 解析后:zygote = true // startSystemServer = true // niceName = zygote (当前进程名称) bool zygote = false; bool startSystemServer = false; bool application = false; String8 niceName; String8 className; while (i < argc) { const char* arg = argv[i++]; if (strcmp(arg, "--zygote") == 0) { zygote = true; niceName = ZYGOTE_NICE_NAME; } else if (strcmp(arg, "--start-system-server") == 0) { startSystemServer = true; } else if (strcmp(arg, "--application") == 0) { application = true; } else if (strncmp(arg, "--nice-name=", 12) == 0) { niceName.setTo(arg + 12); } else if (strncmp(arg, "--", 2) != 0) { className.setTo(arg); break; } else { --i; break; } } ... // (3) 设置进程名为Zygote,执行ZygoteInit类 // Zygote = true if (!niceName.isEmpty()) { runtime.setArgv0(niceName.string()); set_process_name(niceName.string()); } if (zygote) { runtime.start("com.android.internal.os.ZygoteInit", args, zygote); } else if (className) { runtime.start("com.android.internal.os.RuntimeInit", args, zygote); } else { fprintf(stderr, "Error: no class name or --zygote supplied.\n"); app_usage(); LOG_ALWAYS_FATAL("app_process: no class name or --zygote supplied."); return 10; }}
从app_main.cpp$main函数源码可知,为了启动Zygote进程,该函数主要做个如下三个方面的工作,即:
创建AppRuntime实例。AppRuntime是在app_process.cpp中定义的类,继承于系统的AndroidRuntime,主要用于创建和初始化虚拟机。AppRuntime类继承关系如下:
class AppRuntime : public AndroidRuntime{};
解析执行init.rc的启动服务的命令传入的参数。/init.zygote64_32.rc文件中启动Zygote的内容如下,在
/system/core/rootdir/ 目录下可以看到init.zygote32.rc、init.zygote32_64.rc、init.zygote64.rc、init.zygote64_32.rc等文件,这是因为Android5.0开始支持64位的编译,所以Zygote进程本身也有32位和64位版本。启动Zygote进程命令如下: /tasksservice zygote /system/bin/app_process64 -Xzygote /system/bin --zygote --start-system-server --socket-name=zygote class main priority -20 socket zygote stream 660 root system onrestart write /sys/android_power/request_state wake onrestart write /sys/power/state on onrestart restart audioserver onrestart restart cameraserver onrestart restart media onrestart restart netd writepid /dev/cpuset/foreground/tasks /dev/stune/foreground
执行ZygoteInit类。由前面 解析命令传入的参数可知,zygote=true说明当前程序运行的进程是Zygote进程,将调用AppRuntime的start函数执行ZygoteInit类,从类名可以看出执行该类将进入Zygote的初始化流程。
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
接着,我们详细分析下AppRuntime的start函数执行流程。由于AppRuntime继承于AndroidRuntime,因此start函数具体在AndroidRuntime中实现。该函数主要完成三个方面的工作:(a) 初始化JNI环境,启动虚拟机;(b) 为虚拟机注册JNI方法;(c)从传入的com.android.internal.os.ZygoteInit 类中找到main函数,即调用ZygoteInit.java类中的main方法。AndroidRuntime$start源码如下:
void AndroidRuntime::start(const char* className, const Vector& options, bool zygote){ ... // (1) 初始化JNI环境、启动虚拟机 JniInvocation jni_invocation; jni_invocation.Init(NULL); JNIEnv* env; if (startVm(&mJavaVM, &env, zygote) != 0) { return; } onVmCreated(env);
// (2) 为虚拟机注册JNI方法 if (startReg(env) < 0) { ALOGE("Unable to register all android natives\n"); return; } ... // (3) 从传入的com.android.internal.os.ZygoteInit 类中找到main函数,即调用 // ZygoteInit.java类中的main方法。AndroidRuntime及之前的方法都是native的方法,而此刻 // 调用的ZygoteInit.main方法是java的方法,到这里我们就进入了java的世界 char* slashClassName = toSlashClassName(className); jclass startClass = env->FindClass(slashClassName); if (startClass == NULL) { ALOGE("JavaVM unable to locate class '%s'\n", slashClassName); /* keep going */ } else { jmethodID startMeth = env->GetStaticMethodID(startClass, "main", "([Ljava/lang/String;)V"); if (startMeth == NULL) { ALOGE("JavaVM unable to find main() in '%s'\n", className); /* keep going */ } else { env->CallStaticVoidMethod(startClass, startMeth, strArray); #if 0 if (env->ExceptionCheck()) threadExitUncaughtException(env); #endif } } ...}
至此,随着AndroidRuntime$startVm函数被调用,Init进程是如何启动Zygote进程和在Zygote进程中创建虚拟机的实例的这个过程我们就分析完毕了,也验证了Zygote进程在被创建启动后,确实已经持有了虚拟机的实例,以至于Zygote进程fork自身创建应用程序时,应用程序也得到了虚拟机的实例,这样就不需要每次启动应用程序进程都要创建虚拟机实例,从而加快了应用程序进程的启动速度。至于被创建的是Dalvik还是ART实例,我们可以看注释(1)处调用了jni_invocation的Init()函数,该函数源码如下,位于源码根目录下libnativehelper/Jnilnvocation.cpp源文件中。该函数源码如下:
#ifdef __ANDROID__#include #endif
// JniInvocation::Initbool JniInvocation::Init(const char* library) { // Android平台标志 #ifdef __ANDROID__ char buffer[PROP_VALUE_MAX]; #else char* buffer = NULL; #endif // 获取“libart.so”或“libdvm.so” library = GetLibrary(library, buffer); const int kDlopenFlags = RTLD_NOW | RTLD_NODELETE; // 加载“libart.so”或“libdvm.so” handle_ = dlopen(library, kDlopenFlags); if (handle_ == NULL) { if (strcmp(library, kLibraryFallback) == 0) { return false; } library = kLibraryFallback; handle_ = dlopen(library, kDlopenFlags); if (handle_ == NULL) { ALOGE("Failed to dlopen %s: %s", library, dlerror()); return false; } } ... return true;}
从JniInvocation::Init函数源码可知,它首先会调用JniInvocation::GetLibrary函数来获取要指定的虚拟机库名称–“libart.so”或“libdvm.so”,然后调用JniInvocation::dlopen函数加载这个虚拟机库。通过查阅JniInvocation::GetLibrary函数源码可知,如果当前不是Debug模式构建的,是不允许动态更改虚拟机动态库,即默认为"libart.so";如果当前是Debug模式构建且传入的buffer不为NULL时,就需要通过读取"persist.sys.dalvik.vm.lib.2"这个系统属性来设置返回的library。JniInvocation::GetLibrary函数源码如下:
static const char* kLibraryFallback = "libart.so";const char* JniInvocation::GetLibrary(const char* library, char* buffer) { return GetLibrary(library, buffer, &IsDebuggable, &GetLibrarySystemProperty);}
const char* JniInvocation::GetLibrary(const char* library, char* buffer, bool (*is_debuggable)(), int (*get_library_system_property)(char* buffer)) {#ifdef __ANDROID__ const char* default_library; // 如果不是debug构建,不允许更改虚拟机动态库 // library = default_library = kLibraryFallback = "libart.so" if (!is_debuggable()) { library = kLibraryFallback; default_library = kLibraryFallback; } else { // 如果是debug构建,需要判断传入的buffer参数是否为空 // 如果不为空,default_library赋值为buffer if (buffer != NULL) { if (get_library_system_property(buffer) > 0) { default_library = buffer; } else { default_library = kLibraryFallback; } } else { default_library = kLibraryFallback; } }#else UNUSED(buffer); UNUSED(is_debuggable); UNUSED(get_library_system_property); const char* default_library = kLibraryFallback;#endif if (library == NULL) { library = default_library; }
return library;}
// "persist.sys.dalvik.vm.lib.2"是系统属性// 它的取值可以为libdvm.so或libart.soint GetLibrarySystemProperty(char* buffer) {#ifdef __ANDROID__ return __system_property_get("persist.sys.dalvik.vm.lib.2", buffer);#else UNUSED(buffer); return 0;#endif}

常见内存分析工具
2.1 Android Profiler
Android Profiler引入于Android Studio 3.0,是用来替换之前的Android Monitor,主要用来观察内存(Memory)、网络(Network)、CPU使用状态的实时变化。这里我们主要介绍Android Profiler中的Memory Profiler组件,它对应于Android Monitor的Memory Monitor,通过Memory Profiler可以实时查看/捕获存储内存的使用状态、强制GC以及跟踪内存分配情况,以便于快速地识别可能会导致应用卡顿、冻结甚至崩溃的内存泄漏和内存抖动。我们可以通过依次点击AS控制面板的View->Tool Windows->Profiler或者点击左下角的![]() 图标,进入Memory Profiler监控面板。
图标,进入Memory Profiler监控面板。
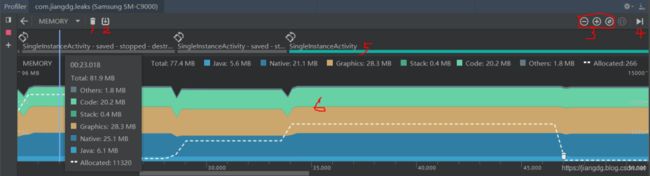
标注(1~6)说明:
1:用于强制执行垃圾回收事件的按钮;
2:用于捕获堆转储的按钮,即Dump the Java heap;
3:用于放大、缩小、复位时间轴的按钮;
4 :用于实时播放内存分配情况的按钮;
5:发生一些事件的记录(如Activity的跳转,事件的输入,屏幕的旋转);
6:内存使用量事件轴,它包括以下内容:一个堆叠图表。显示每个内存类别当前使用多少内存,如左侧的y轴和顶部的彩色健所示。
Java:从Java或Kotlin代码分配的对象的内存(重点关注);
Native:从C或C++代码分配的对象的内存(重点关注);
Graphics:图像缓存等,包括GL surfaces, GL textures等;
Stack:栈内存(包括java和c/c++);
Code:用于处理代码和资源(如 dex 字节码.so 库和字体)分配的内存;
Other:系统都不知道是什么类型的内存,放在这里;
Allocated:从Java或Kotlin代码分配的对象数。
一个堆叠图表。显示每个内存类别当前使用多少内存,如左侧的y轴和顶部的彩色健所示。
一条虚线。虚线表示分配的对象数量,如右侧的y轴所示(5000/15000)。
每个垃圾回收时间的图标。
2.1.1 Allocation Tracker
Allocation Tracker,即跟踪一段时间内存分配情况,Memory Profiler能够显示内存中的每个Java对象和JNI引用时如何分配的。我们需要关注如下信息:
分配了哪些类型的对象,分配了多大的空间;
对象分配的栈调用,是在哪个线程中调用的;
对象的释放时间(只针对8.0+);
如果是Android 8.0以上的设备,支持随时查看对象的分配情况,具体的步骤如下:在时间轴上拖动以选择要查看的哪个区域(时间段)的内存分配情况,如下图所示:
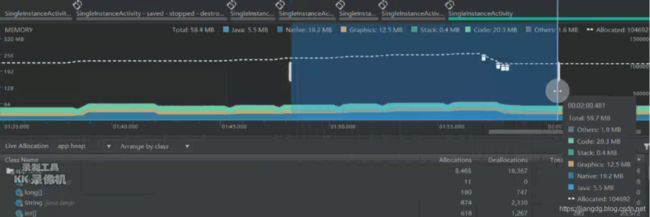 接下来,我们就以上一篇文章中所提及的单例模式引起的内存泄漏为例,来检查内存分配的记录,排查可能存在内存泄漏的对象。具体的步骤如下:
接下来,我们就以上一篇文章中所提及的单例模式引起的内存泄漏为例,来检查内存分配的记录,排查可能存在内存泄漏的对象。具体的步骤如下:
(1) 浏览列表以查找堆计数异常大且可能存在泄漏的对象,即大对象。为了帮助查找已知类,可以点击下图中黄色方框的选项选择使用Arrange by class或Arrange by Package按类名或者包名进行分组,然后再红色方框中的第一个选项就会列出Class Name或Package Name,我们可以直接去查找目标类,也可以点击下图中的Filter 图标 ![]() 快速查找某个类,比如SingleInstanceActivity,当然我们还可以使用正则表达式Regex和大小写匹配Match Case。红色方框中其他选项意义:
快速查找某个类,比如SingleInstanceActivity,当然我们还可以使用正则表达式Regex和大小写匹配Match Case。红色方框中其他选项意义:
Allocations:堆中动态分配对象个数;
Deallocations:解除分配的对象个数;
Total Counts:目前存在的对象总数;
Shallow Size:堆中所有对象的总大小(以字节为单位),不包含其引用的对象;
(2) 当点击SingleInstanceActivity类时,会出现一个Instance View窗口,该窗口完整得记录了该对象在这一段时间内的分配情况,如下图所示,Instance View窗口中显示了7个SingleInstanceActivity对象,并记录了每个对象被分配(Alloc Time)、释放(Dealloc Time)的时间。但是当我们强制GC后,仍然还存在两个SingleInstanceActivity对象,根据平时的开发经验,其中的一个对象可能被某个对象持有,导致无法被释放从而造成泄漏。
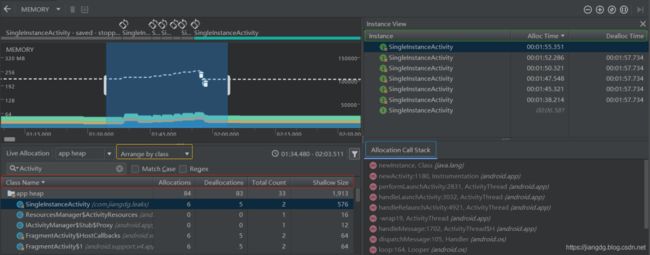 (3) 如果我们希望确定(2)中无法被GC的对象被谁持有,可以点击该对象,此时在Instance View窗口的下方就会出现Allocation Call Stack标签,如上图蓝色方框所示,该标签中显示了该对象被分配到何处以及哪里线程中,此外,我们还可以在标签中右键点击任意行并选择Jump to Source,以在编辑器中打开该代码。
(3) 如果我们希望确定(2)中无法被GC的对象被谁持有,可以点击该对象,此时在Instance View窗口的下方就会出现Allocation Call Stack标签,如上图蓝色方框所示,该标签中显示了该对象被分配到何处以及哪里线程中,此外,我们还可以在标签中右键点击任意行并选择Jump to Source,以在编辑器中打开该代码。
2.1.2 Heap Dump
Head Dump,即捕获堆转储,它的作用是捕获某一时刻应用中有哪些对象正在使用内存,并将这些信息存储到文件中。Head Dump可以帮助我们找到大对象和通过数据的变化发现内存泄漏,比如当我们的应用使用一段时候后,捕获了一个heap dump,这个heap dump里面发现了并不应该存在的对象分配情况,这说明是存在内存泄漏的。捕获堆转储后,可以查看以下信息:
该时刻应用分配了哪些类型的对象,每种对象有多少;
每个对象当前时刻使用了多少内存;
对象所分配到的调用堆栈(Android 7.1以下会有所区别);
要捕获堆转储,通过点击 Memory Profiler 工具栏中的 Dump Java heap图标 ![]() 实现,获得某一时刻的Heap Dump如下图:
实现,获得某一时刻的Heap Dump如下图:
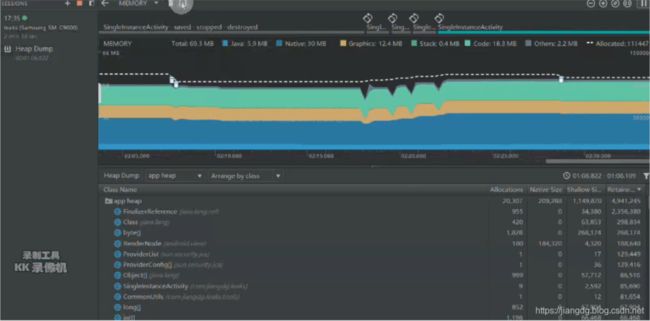
接下来,我们仍然以上一篇文章中所提及的单例模式引起的内存泄漏为例,来分析Heap Dump所表达的信息。从下图展示内容可看出,Heap Dump表达的窗体与Allocation Tracker差不多,只是展示的具体内容不同。具体如下图所示: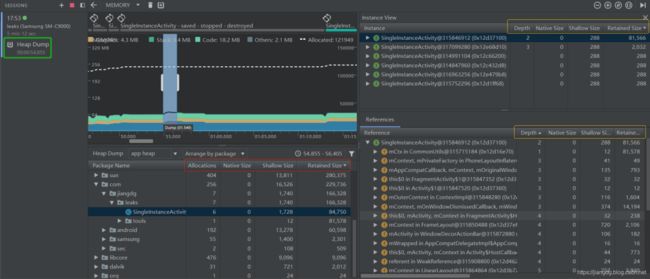
下面我们解释下上图颜色方框中相关标签名表示的意义。
(1) 红色方框
Allocations: 堆中分配对象的个数;
Native Size:此对象类型使用的native内存总量。此列仅适用于Android 7.0及更高版本。您将在这里看到一些用Java分配内存的对象,因为Android使用native内存来处理某些框架类,例如Bitmap。
Shallow Size: 此对象类型使用的Java内存总量;
Retained Size: 因此类的所有实例而保留的内存总大小;
(2) 黄色方框
Depth:从任意 GC root 到所选实例的最短 hop 数。
Native Size: native内存中此实例的大小。此列仅适用于Android 7.0及更高版本。
Shallow Size:此实例Java内存的大小。
Retained Size:此实例支配[dominator]的内存大小(根据 [支配树]
2.2 MAT
在进行内存分析时,我们可以使用Android Profiler的Memory Profiler组件来观察、追踪内存的分配使用情况(Allocation Tracker),也可以通过这个工具找到疑似发生内存泄漏的位置(Heap Dump)。但是如果想要深入地进行分析并确定内存泄漏,就要分析疑似发生内存泄漏时所生产的堆转储文件,该文件由点击 Memory Profiler工具栏中的 Dump Java heap图标 ![]() 生成,输出的文件格式为hprof,分析工具使用的是MAT。由于Memory Profiler生成的hprof文件不是标准的hprof文件,需要使用SDK自带的hprof-conv进行转换,它的路径在sdk/platform-tools中,执行命令:hprof-conv E:\1.hprof E:\standar.hprof。
生成,输出的文件格式为hprof,分析工具使用的是MAT。由于Memory Profiler生成的hprof文件不是标准的hprof文件,需要使用SDK自带的hprof-conv进行转换,它的路径在sdk/platform-tools中,执行命令:hprof-conv E:\1.hprof E:\standar.hprof。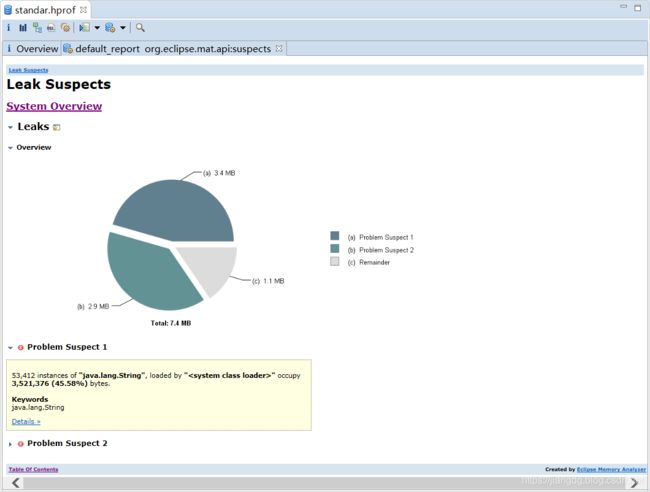
MAT,全称"Memory Analysis Tool",是对内存进行详细分析的工具,它是eclipse的一个插件,对于AS开发来说,需要单独下载MAT(当前最新版本为1.9.1)。使用MAT打开一个标准的hprof文件如上图所示,选择Leak Suspects Report选项,MAT为hprof文件生成的报告,该报告为中给出了MAT认为可能出现内存泄漏问题的地方,除非内存泄漏特别明显,通过Leak Suspects还是很难发现内存泄漏的位置。因此,我们还是老老实实自己来动手分析,这里打开Overview标签(一般打开文件时会自动打开),具体如下图: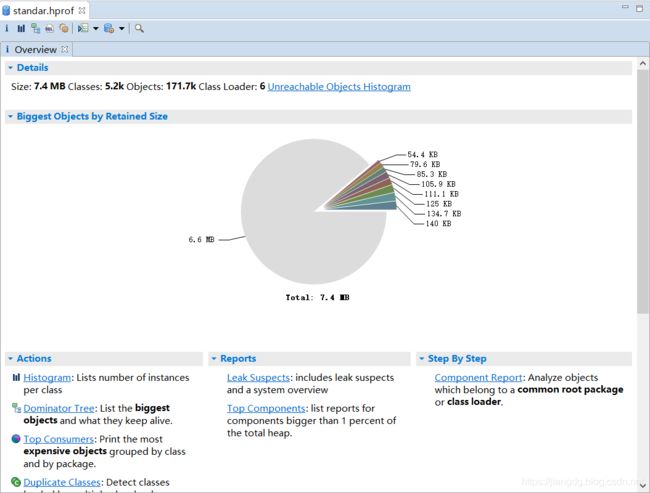
在上述图中,我们主要关注两个部分:饼状图和Actions,其中,饼状图主要用来显示内存的消耗,它的彩色部分表示被分配的内存,灰色部分则是空闲区域,单击每个彩色区域可以看到这块区域的详细信息;Actons一栏列出了4种Action,其作用与区别如下。
Historgram:列出每个类的所有对象。从类的角度进行分析,注重量的分析;
Dominator Tree:列出大对象和它们的引用关系。从对象的角度分析,注重引用关系分析;
Top Consumers:获取开销最大的对象,可通过类或包形式分组;
Duplicate Classes:检测出被多个类加载器加载的类;
其中,分析内存泄漏最常用的就是Histogram和Dominator Tree。这两种方式只是判断内存问题的方式不同,但是最终都会归结到通过查看GC引用链来确定内存泄漏的具体位置(原因)。接下来,我们就以Dominator Tree为例来讲解如何使用MAT来判定是否有内存泄漏以及泄漏的具体原因。Dominator Tree,即支配树,点击Dominator Tree选项如下图所示,然后使用条件过滤(黄色方框输入),找一个我们认为可能发生了内存泄漏的类:
从上图可以看到,在Dominator Tree列出了很多SingleInstanceActivity的实例,而一般SingleInstanceActivity是不该有这么多实例的,因此,基本可以断定发生了内存泄漏,至于内存泄漏的具体原因,就需要查看GC引用链。但在查看之前,我们需要理解下红色方框几个标签的意义。
Shallow Heap
对象自身占用的内存大小,不包括引用的对象。如果是数组类型的对象,它的大小由数组元素的类型和长度决定;如果是非数组类型的对象,它的大小由其成员变量的数量和类型决定。
Retained Heap
Retained Heap就是当前对象被GC后,从Heap上总共能释放掉多大的内存空间,这部分内存空间被称之为Retained Set。Retained Set指的是这个对象本身和它持有引用的对象以及这些引用对象的Retained Set所占内存大小的总和。下面我们从一颗引用树(GC引用链)来理解下Retained Set:

假设A、B为GC Root对象,根据Retained Set定义可知,对象E的Retained Set为对象E、G,对象C的Retained Set为对象C、D、E、F、G、H。另外,通过引用树我们还可以演化得到本小节最重要的部分–支配树(Dominator Tree),即在引用树中如果一条到对象Y的路径一定(必然)会经过对象X,那么称为X支配Y,并且在所有支配Y的对象中,X是Y最近的一个对象就称为X直接支配Y,支配树就是反应的这种直接支配关系。在支配树中,父节点直接支配子节点。上图就是引用树转换为支配树的例子,由此可以得到:
对象C直接支配对象D、E、H,故C是D、E、H的父节点;
对象D直接支配对象F,故D是F的父节点;
对象E直接支配对象G,故E是G的父节点;
通过支配树,我们可以知道假如对象E被回收了,则会释放E、G的内存,而不会释放H的内存,因为F可能还会引用着H,只有C被回收了,H的内存才会被释放。因此,我们可以得到一个结论:通过MAT的Dominator Tree,可以清晰地得到一个对象的直接支配的对象,如果直接支配对象中出现了不该有的对象,就说明发生了内存泄漏。示例如下: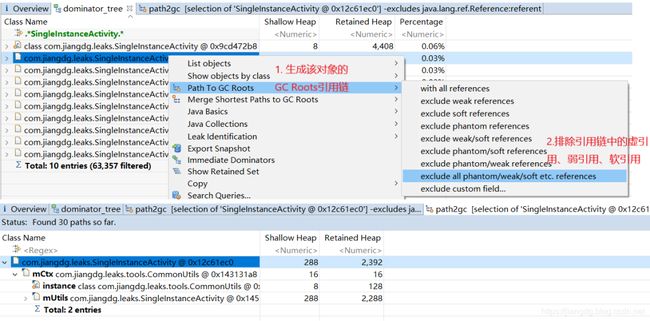
从上图可知,被选中的SingleInstanceActivity对象的直接支配对象出现了不该有的CommonUtils对象,因为SingleInstanceActivity是要被回收的。换句话说,CommonUtils持有SingleInstanceActivity对象的引用,导致SingleInstanceActivity对象无法被正常回收,从而导致了内存泄漏。
2.3 LeakCanary
文章最后,我们借助Dalvik 虚拟机和 Sun JVM 在架构和执行方面有什么本质区别?一文中的一段话作个总结,个人觉得这对理解JVM/Dalvik/ART的本质比较有启发意义,即JVM其核心目的,是为了构建一个真正跨OS平台,跨指令集的程序运行环境(VM)。DVM的目的是为了将android OS的本地资源和环境,以一种统一的界面提供给应用程序开发。严格来说,DVM不是真正的VM,它只是开发的时候提供了VM的环境,并不是在运行的时候提供真正的VM容器。这也是为什么JVM必须设计成stack-based的原因。
原文链接:https://blog.csdn.net/AndrExpert/article/details/102956524


更多精彩推荐
☞跑路后再删库?思科前员工离职后恶意删库,损失达 240 万美元
☞这样的 Python 游戏你想玩吗?| 每日趣闻
☞5年5亿美金,华为昇腾如何争夺AI开发者?
☞GitHub 标星 20000+,国产 AI 开源从算法开始突破 | 专访商汤联合创始人林达华
☞下一代 IDE:Eclipse Che 究竟有什么奥秘?
☞BM发声,孙宇晨入场,国产公链集体进军DeFi
点分享点点赞点在看