大数据学习整理篇(七)Linux下使用Docker搭建Spark多节点,Phoenix单机版,然后使用Spark访问Phoenix(java示例成功版)
我们的大数据平台之前定义的步骤就是,使用ETL工具从关系型数据库抽取到HBase,然后通过Phoenix的二级索引,SQL关联查询,将大数据需要学习的训练集以及验证集提供给spark,调用spark ml的机器学习类库,做相应的算法分析,比如线性回归算法和决策树算法等等,最后生成临时表到phnenix的,使用zeppelin将数据展示出来,整个大数据平台的思路就是这样。
下面我们按照步骤逐一展开:
1.搭建Docker的单机版phoenix和hbase(生产环境建议使用集群版,可以参考https://www.cnblogs.com/chinas/p/5910854.html)
https://gitee.com/astra_zhao/hbase-phoenix-docker,进行下载,下载完后,按照README.md,最后启动,请使用如下语句启动容器
docker run -it -p 8765:8765 -跑2181:2181 iteblog/hbase-phoenix-docker2.搭建Docker的Spark多节点环境(生产环境可以采用docker,但docker-compose要设置的比较好,因为存储文件要实时备份)
https://gitee.com/astra_zhao/docker-spark,下载后,使用docker-compose up -d即可安装成功,安装成功后,暴露端口如下:
![]()
注意,docker-compose.yml文件要加入如下说明:
master:
image: gettyimages/spark
command: bin/spark-class org.apache.spark.deploy.master.Master -h master
hostname: master
environment:
MASTER: spark://master:7077
SPARK_CONF_DIR: /conf
SPARK_PUBLIC_DNS: localhost
extra_hosts:
- "主机名:192.168.63.9"
-"phoenix容器ID:172.17.0.2"
通过添加extra_hosts,来指定容器机器跟主机进行通讯,以及容器之间互相通讯。否则启动会报错。
3.使用Phoenix的Join操作和优化
参考这篇文章:https://www.cnblogs.com/sh425/p/7274283.html
4.搭建Java示例
4.1搭建maven工程(spring boot工程自行完成)
下面的maven支持两种打包方式,mvn clean package -Dmaven.skip.test=true是将第三方jar包打入到target目录的lib下。
mvn clean package assembly:single单独打成独立的包,建议使用第一种方式
UTF-8
1.8
1.8
2.4.0
2.11
junit
junit
4.11
test
org.apache.phoenix
phoenix-core
5.0.0-HBase-2.0
org.slf4j
slf4j-log4j12
log4j
log4j
org.apache.phoenix
phoenix-spark
5.0.0-HBase-2.0
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql_${scala.binary.version}
${spark.version}
org.apache.hbase
hbase-client
2.0.6
org.apache.hbase
hbase-common
2.0.6
org.apache.hbase
hbase-server
2.0.6
org.apache.zookeeper
zookeeper
3.4.10
org.apache.hbase
hbase-protocol
2.0.6
org.apache.htrace
htrace-core
3.2.0-incubating
io.dropwizard.metrics
metrics-core
3.2.6
src/main/resources
**/*.properties
true
org.apache.maven.plugins
maven-compiler-plugin
3.7.0
1.8
1.8
UTF-8
org.apache.maven.plugins
maven-jar-plugin
true
lib/
tech.zhaoxin.App
org.apache.maven.plugins
maven-dependency-plugin
copy-dependencies
package
copy-dependencies
${project.build.directory}/lib
false
false
true
org.apache.maven.plugins
maven-assembly-plugin
2.5.5
tech.zhaoxin.App
jar-with-dependencies
生成Java类
public class PhoenixSparkRead {
public static void main(String[] args){
SparkConf sparkConf = new SparkConf().setMaster("spark://192.168.61.102:7077").setAppName("phoenix-test");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new SQLContext(jsc);
System.out.println("开始执行第一步");
// Load data from TABLE1
Dataset df = sqlContext
.read()
.format("org.apache.phoenix.spark")
.option("table", "iteblog")
.option("zkUrl", "192.168.61.102:2181")
.load();
df.createOrReplaceTempView("iteblog");
System.out.println("开始执行第二步");
SQLContext sqlCtx = new SQLContext(jsc);
df = sqlCtx.sql("SELECT * FROM iteblog");
System.out.println("开始执行第三步");
List rows = df.collectAsList();
System.out.println(rows);
jsc.stop();
System.out.println("完成");
}
}
5.配置操作
5.1进入linux服务器,将spark-2.4.1-bin-hadoop2.7.tgz放入到opt目录,进行解压操作
tar -xvzf spark-2.4.1-bin-hadoop2.7.tgz
5.2将上面mvn打包的lib目录下jar包,拷贝到opt/jars/lib目录下
5.3将下面的jar包全部拷贝到spark-2.4.1-bin-hadoop2.7/jars目录
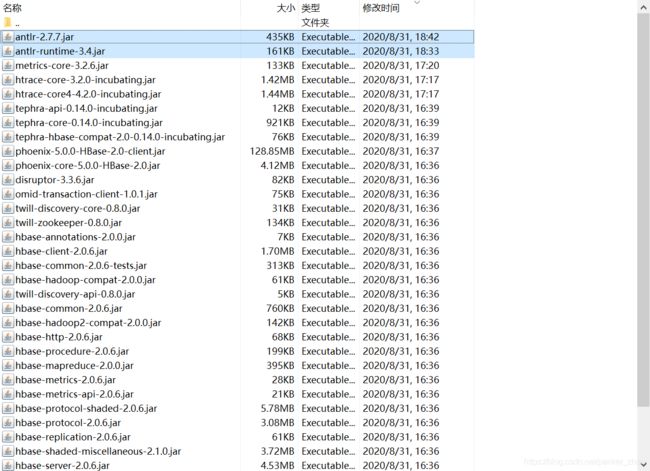

5.4将上面文件拷入到spark的docker容器里面,参考命令如下:
docker cp /opt/phoenix/ 8ead:/usr/spark-2.4.1/jars/ (/opt/phoenix目录只包含上面图片的jar包)
然后进入容器将/usr/spark-2.4.1/jars/phoenix的jar包拷贝到上层目录
两个容器都执行如下操作
5.5最后到主机的/opt/spark-2.4.1-bin-hadoop2.7/bin目录执行如下命令:
./spark-submit --class com.astra.PhoenixSparkRead /opt/jars/spark-zeppelin-learn-1.0-SNAPSHOT.jar --jars /opt/jars/lib/*.jar --master spark://192.168.61.102:7077 --driver-memory 4g
5.6最后就能看到相关数据