GlobalTrack 笔记
GlobalTrack : A Simple and Strong Baseline for Long-term Tracking
https://arxiv.org/abs/1912.08531 link
长期跟踪的一个关键在于更大的区域(通常是整个图像)中搜索目标,以应对目标丢失。作者提出GlobalTrack进行全局实例搜索的跟踪器;GlobalTrack基于two-stage的目标检测器,根据单个查询图像作为指导,对任意实例进行全图像和多尺度搜索。最重要的是不需要在线学习,也不需要对位置或尺度变化进行惩罚,无需尺度平滑。
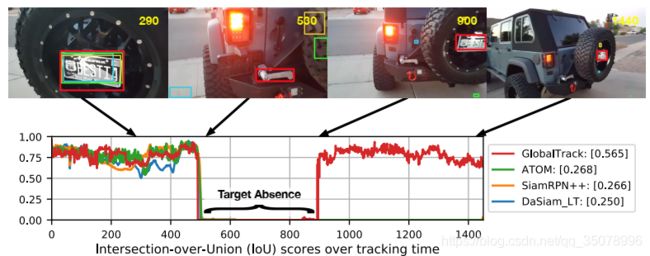
基于Faster-RCNN的思路,GlobalTrack包含两个子模块:用于生成query-specific候选对象的query-guided区域生成网络(QG-RPN),以及对候选对象进行分类的query-guided区域卷积神经网络(QG-RCNN)并产生最终的预测。
GlobalTrack的总体架构: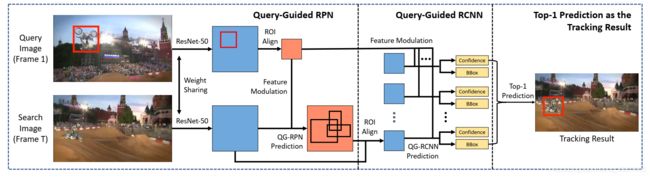
在QG-RPN和QG-RCNN的特征调制部分中,对backbone和ROI输出的查询和搜索图像特征之间的相关性进行编码,指导检测器定位到query-specific的实例。
在跟踪过程中,将QG-RCNN的top-1预测作为结果。在训练阶段,使用与Faster-RCNN中相同的分类和定位损失,作者进一步提出了一种交叉查询损失,以提高GlobalTrack针对干扰物/相似物的鲁棒性,把同一图像上不同查询的损失平均化,迫使模型学习查询与预测结果之间的依赖性。
Query-guided RPN:
QG-RPN是为了得到与目标相关的候选区域,关键是利用相关性在backbone特征中对查询信息进行编码。 z ∈ R k × k × c z\in R^{k \times k \times c} z∈Rk×k×c表示查询实例的ROI特征, x ∈ R h × w × c x\in R^{h\times w \times c} x∈Rh×w×c表示搜索图像特征,其中h,w和k代表特征尺寸;目的是获得一个 x ^ ∈ R h × w × c \hat{x} \in R^{h\times w\times c} x^∈Rh×w×c,用于编码z和x之间的相关性:
x ^ = g q g − r p n ( z , x ) = f o u t ( f x ( x ) ⊗ f z ( z ) ) \hat{x}=g_{qg-rpn}\left(z,x\right)=f_{out}\left(f_x\left(x\right)\otimes f_z\left(z\right)\right) x^=gqg−rpn(z,x)=fout(fx(x)⊗fz(z))
⊗表示卷积, f z ( z ) f_z\left(z\right) fz(z)是把z转换为卷积核,该卷积核在特征 f x ( x ) f_x\left(x\right) fx(x)上生成z与x之间的相关性。 f o u t f_{out} fout用于确保输出 x ^ \hat{x} x^具有与x相同的大小。 f z f_z fz是零填充的k×k卷积层,将z转换为1×1的卷积核, f x f_x fx是具有填充的3×3卷积层,而 f o u t f_{out} fout是 1×1卷积层,把特征通道数变回c。这部分不使用归一化和激活函数。
由于 x ^ \hat{x} x^和 x x x是相同的大小,因此可以直接重用RPN的模块并执行后续过程(分类,定位,滤波等)。使用相同的RPN损失来训练QG-RPN,其中分类 L c l s L_{cls} Lcls和定位 L l o c L_{loc} Lloc损失分别是交叉熵和smooth L1; QG-RPN的总损失为:
L q g − r p n ( z , x ) = L r p n ( x ^ ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N l o c ∑ i p i ∗ L l o c ( s i , s i ∗ ) L_{qg_{-rpn}}\left(z,x\right)=L_{rpn}\left(\hat{x}\right)=\frac{1}{N_{cls}}\sum_{i}{L_{cls}\left(p_i,p_i^\ast\right)}+\lambda\frac{1}{N_{loc}}\sum_{i}{p_i^\ast L_{loc}\left(s_i,s_i^\ast\right)} Lqg−rpn(z,x)=Lrpn(x^)=Ncls1i∑Lcls(pi,pi∗)+λNloc1i∑pi∗Lloc(si,si∗)
其中 p i p_i pi和 s i s_i si是第i个proposal的预测得分和位置, p i ∗ p_i^\ast pi∗和 s i ∗ s_i^\ast si∗是groundtruth。λ是平衡权重。
Query-Guided R-CNN
在第二阶段,利用QG-RPN生成的proposal,根据ROI特征refine其标签和边框的预测。使用Query-Guided R-CNN(QG-RCNN)对这些proposal进行分类和边框优化。给定查询 z ∈ R k × k × c z\in\mathbf{R}^{\mathbf{k}\times\mathbf{k}\times\mathbf{c}} z∈Rk×k×c的ROI特征和第i个proposal x i ∈ R k × k × c x_i\in\mathbf{R}^{\mathbf{k}\times\mathbf{k}\times\mathbf{c}} xi∈Rk×k×c的ROI特征,通过特征调制对它们的相关性进行编码:
x ^ i = g q g − r c n n ( z , x i ) = h o u t ( h x ( x i ) ⊙ h z ( z ) ) \widehat{x}_i=g_{qg_{-rcnn}}\left(z,x_i\right)=h_{out}\left(h_x\left(x_i\right)\odot h_z\left(z\right)\right) x i=gqg−rcnn(z,xi)=hout(hx(xi)⊙hz(z))
其中 ⊙ \odot ⊙表示哈达玛积, h x h_x hx和 h z h_z hz分别是 x i x_i xi和 z z z的特征投影, h o u t h_{out} hout输出特征 x ^ \hat{x} x^。 h x h_x hx和 h z h_z hz是带填充的3×3卷积层, h o u t h_{out} hout为1×1卷积层,输出c个通道。
获得调制特征 x ^ i \widehat{x}_i x i之后,对proposal进行分类和定位以获得最终的预测。 在训练过程中,类似于QG-RPN使用交叉熵和smooth L1作为损失函数:
L q g − r c n n ( z , x ) = 1 N p r o p ∑ i L r c n n ( x ^ i ) L_{qg_-rcnn}\left(z,x\right)=\frac{1}{N_{prop}}\sum_{i}{L_{rcnn}\left(\widehat{x}_i\right)} Lqg−rcnn(z,x)=Nprop1i∑Lrcnn(x i)
其中 N p r o p N_{prop} Nprop是proposal个数,
L r c n n ( x ^ i ) = L c l s ( p i , p i ∗ ) + λ p i ∗ L l o c ( s i , s i ∗ ) L_{r c n n}\left(\hat{x}_{i}\right)=L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda p_{i}^{*} L_{l o c}\left(s_{i}, s_{i}^{*}\right) Lrcnn(x^i)=Lcls(pi,pi∗)+λpi∗Lloc(si,si∗)
p i p_i pi和 s i s_i si是估计的置信度和位置(中心和比例偏移), p i ∗ p_i^\ast pi∗和 s i ∗ s_i^\ast si∗是groundtruth;λ是平衡权重。
Cross-query Loss:
交叉查询损失,给定一对具有M个实例{1,2,…,M}的图像,可以构造M个query-search图像对,从而计算出M个QG-RPN和QG-RCNN损失;对这些查询损失进行平均,获得一对图像的最终损失:
L c q l = 1 M ∑ k = 1 M L ( z k , x ) L_{cql}=\frac{1}{M}\sum_{k=1}^{M}L\left(z_k,x\right) Lcql=M1k=1∑ML(zk,x)
其中
L ( z k , x ) = L q g − r p n ( z k , x ) + L q g − r c n n ( z k , x ) L\left(z_k,x\right)=L_{qg_{-rpn}}\left(z_k,x\right)+L_{qg_{-rcnn}}\left(z_k,x\right) L(zk,x)=Lqg−rpn(zk,x)+Lqg−rcnn(zk,x)
采用随机梯度下降训练模型,跟踪时将QG-RCNN的top-1预测作为结果,作者提到进行尺度平滑或者惩罚会有性能提升,但对无后处理的方式有强迫症,所以没有使用。
实验测试
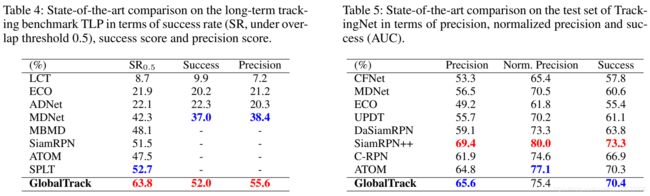
LaSOT:
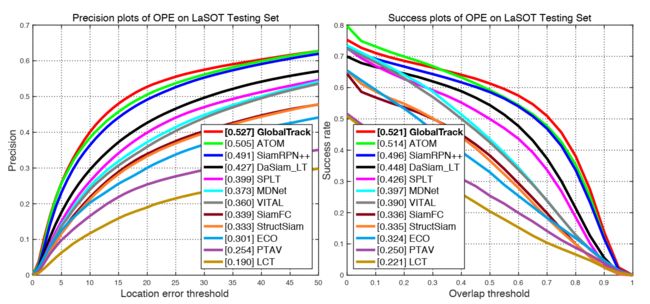
TLP & TrackingNet: