Elasticsearch第二谈(ES核心概念、ES简单操作、构建查询、查询结果过滤排序分页、term和match查询区别、自定义查询结果高亮)
写博客即是为了记录自己的学习历程,也希望能够结交志同道合的朋友一起学习。文章在撰写过程中难免有疏漏和错误,欢迎指出文章的不足之处;更多内容请点进爱敲代码的小游子查看。
临渊羡鱼,不如退而结网。一起加油!
Elasticsearch相关概念
1、Elasticsearch面向文档、关系行数据库、和Elasticsearch对比
Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 文档(Docments) ⇒ 字段(Fields) ⇒类型(相当于一个类,把同一类的索引保存)
2、文档
Elasticsearch是面向文档的,索引和搜索数据最小单位是文档,Elasticsearch中文档重要的属性:
- 自我包含、一篇文档同时包含字段和对应的值,key:value
- 可以是层次的,一个文档中包含自文档(就是一个json对象,fastjson进行自动转换)
- 灵活的结构,文档不依赖于预先定义的模式
3、类型
类型是文档的逻辑容器,就像关系型数据库,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。文档是无模式的,它不需要有映射中定义的所有字段;
4、索引
可理解为数据库
索引是映射类型的容器,Elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型中的字段和其他设置。然后他们被保存到了各个分片上
物理设计:节点和分片 如何工作?
- 一个集群至少有一个节点,而一个节点就是一个Elasticsearch进程,节点可以有多个索引默认的,如果你创建一个索引,那么索引将会有5个分片(主分片),每一个分片会有一个副本(赋值分片)
5、分片
到了一定数量级,索引文件就会占满整个服务器的磁盘,磁盘容量只是其中一个问题,索引文件变的大,会严重降低搜索的效率。怎么解决这个问题呢?
- 分片就是用来解决这些问题的,简单来讲,分片就是把单索引文件分成多份存储,且这些索引的分片可以分部在不同的机器上。假设单台机器磁盘容量1TB,现在需要存放5TB的索引数据,那就可以把5TB索引分成10份,分别存放到10台机器上每份500G,这就是所谓的倒排索引
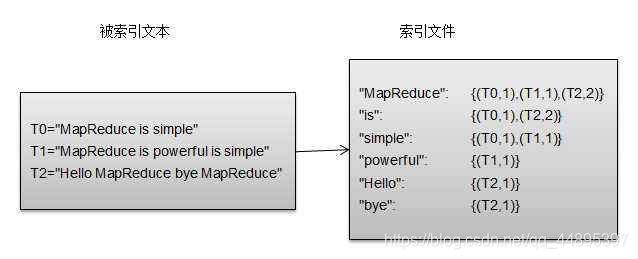
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,首先要将每个文档拆分成独立的词,然后创建一个包所有不重复的词条排序列表,然后列出每个词条出现在哪个文档:

现在查询to forever,只需要查看包含每个词条的文档

IK分词器
1、什么是ik分词器:
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作
默认的中文分词是将每个字看成一个词,比如"中国的花"会被分为"中",“国”,“的”,“花”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
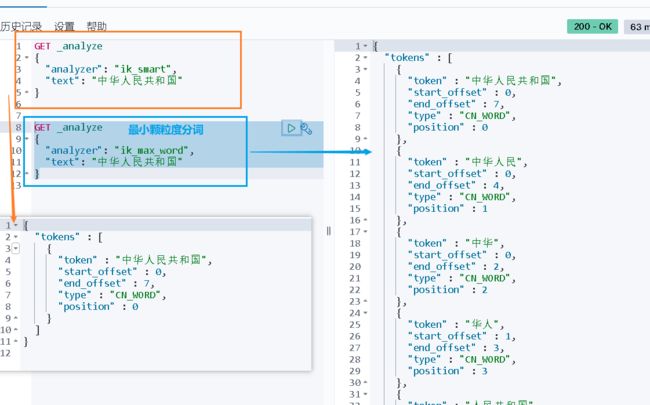
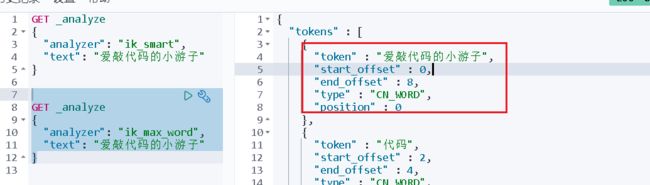
IK提供了两个分词算法ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
2、安装
地址:https://github.com/medcl/elasticsearch-analysis-ik

解压到Elasticsearch安装目录中的plugins中即可
3、重启观察es

4、使用elasticsearch-plugin查看插件

5、使用Kibana测试
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["爱敲代码的小游子"]
}
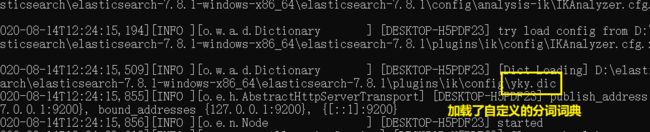
6、ik分词器增加自己的配置
问题:自定义的词,“小游子”被拆开了
需要自己加入分词器的字典中

新建分词词典(注意dic文件存储要使用UTF-8才能生效),引入

重启es
执行查询操作
Rest风格
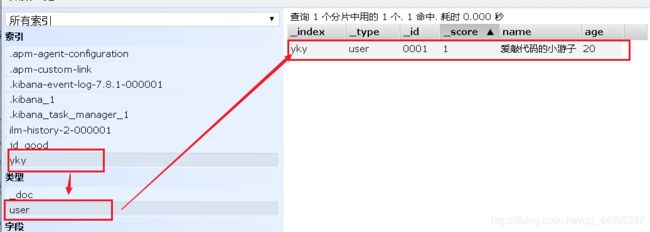
一、操作索引
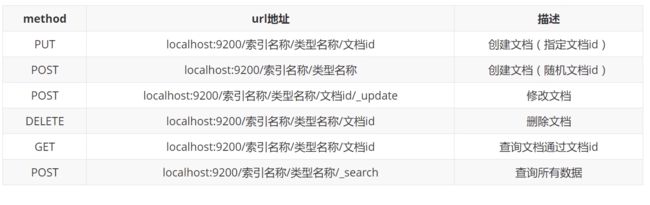
1、创建一个索引
PUT /索引名/~文档类型~/文档id
{
请求体
}
2、数据类型

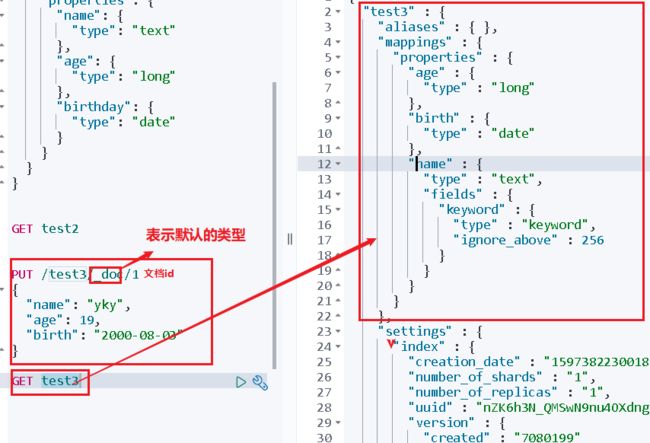
3、指定字段的类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}

4、获得规则信息
GET 索引名

5、查看默认的信息
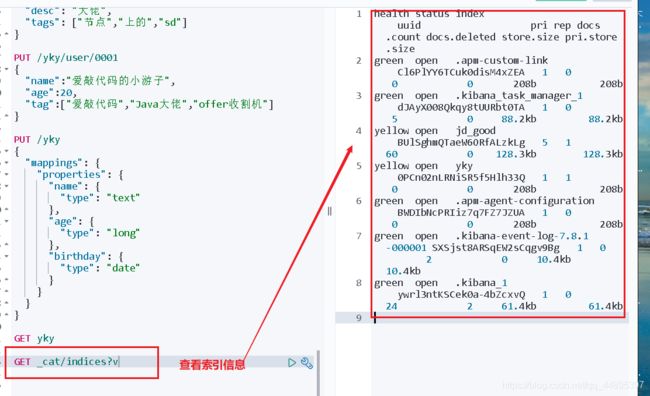
6、扩展命令
- 查看es信息
GET _cat/…
- 查看索引信息
GET _cat/indices?v
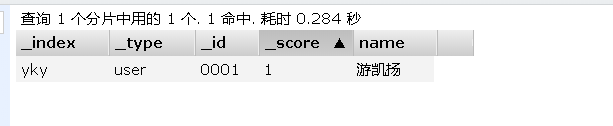
7、修改索引
- 可以使用PUT提交,覆盖之前的设置
改掉需要修改的参数值即可(不管是否修改,所有的参数值都必须有,如果没有,修改后就为空)
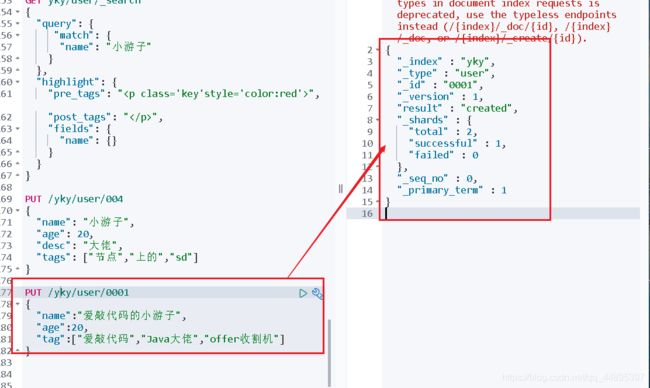
PUT /yky/user/0001
{
"name":"爱敲代码的小游子",
"age":20,
"tag":["爱敲代码","Java大佬","offer收割机"]
}

- post方式修改
只需要写出需要修改的参数值即可
POST /库名/类型/文档id/_update
{
"doc": {
参数
}
}
8、删除索引
二、文档的基本操作
1、添加数据
PUT /索引名/类型/id
{
参数体
}
2、获取数据
GET 索引名/类型/id
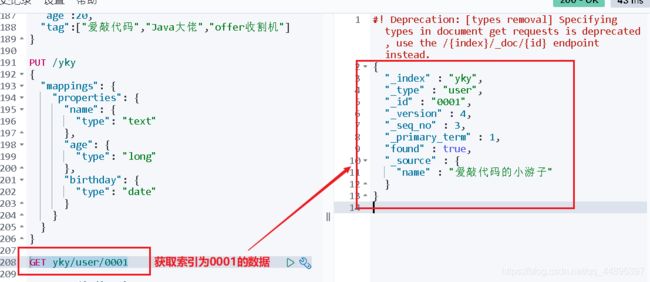
3、更新数据
- PUT
- POST _update
#新增
PUT /yky/user/003
{
"name": "李四",
"age": 22,
"desc": "很强",
"tags": ["初中生","c大佬","暖男"]
}
#查询
GET /yky/user/001
#更新数据
POST /yky/user/001/_update
{
"doc":{
"name": "爱敲代码的小游子"
}
}
4、条件查询
GET 索引名/类型/_search?q=key:value
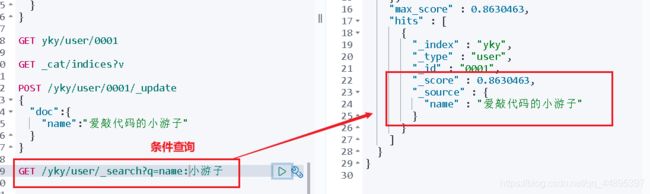
三、花式查询
1、使用Query DSL
其输出和上面使用/_search?q=john的输出一样。上面的multi_match关键字通常在查询多个fields的时候作为match关键字的简写方式。fields属性指定需要查询的字段,如果我们想查询所有的字段,这时候可以使用_all关键字,正如上面的一样。以上两种方式都允许我们指定查询哪些字段
GET /yky/user/_search
{
"query":{
"match": {
"FIELD": "TEXT"
}
}
}

2、构建的查询

3、结果的过滤
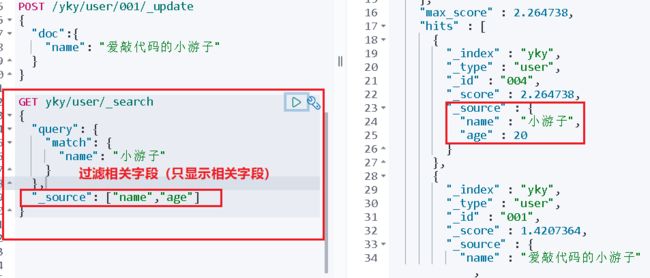
GET yky/user/_search
{
"query": {
"match": {
"name": "小游子"
}
},
"_source": ["name","age"]
}
4、排序
GET yky/user/_search
{
"query": {
"match": {
"name": "小游子"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
4、分页查询
"from": 从第几条诗句开始显示(从0开始),
"size": 每页显示数据条数,
"sort": 排序,
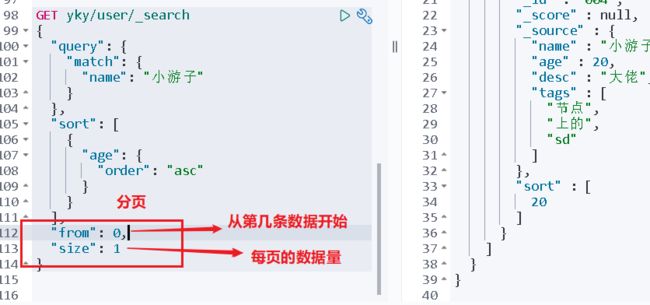
数据下标从0开始
可以进行多条件查询
must == > and ==> 所有条件都要符合
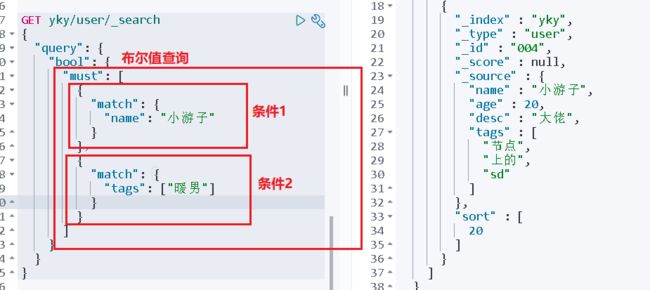
GET yky/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "小游子"
}
},
{
"match": {
"age": 20
}
}
]
}
}
}
should ==> or

GET /yky/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "小游子"
}
},
{
"match": {
"name": "yky"
}
}
]
}
}
}
must_not ==> not
查询不满足所有条件的数据

6、过滤器
- lt小于
- gt大于
- gte大于等于
- lte小于等于
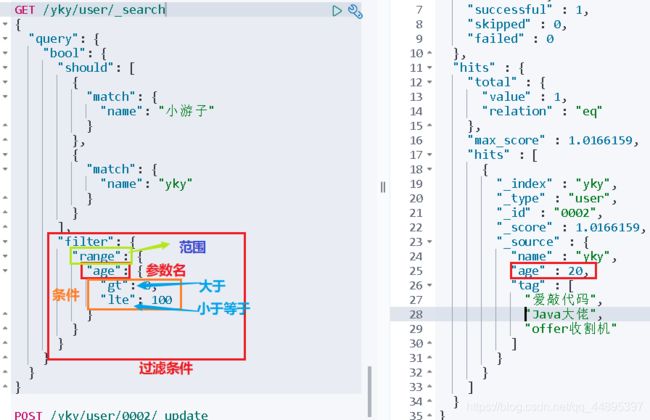
"filter": [{
"range": {
"age": {
"gt": 0,
"lte": 100
}
}
}]
7、匹配多个条件
多个条件只要满足一个就能查询
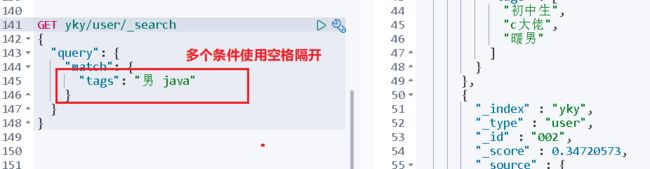
GET /yky/user/_search
{
"query":{
"match": {
"参数名": "条件一 条件二"
}
}
}
8、精确查询
term查询直接通过倒排索引指定的词条查询的
-
分词:term直接查询精确的
-
match:会使用分词器解析,先分析文档
两个类型:text keyword ==》 text类型可以被分词器解析,keyword类型不会被分词器解析
term和match查询区别
1、match查询
match的查询匹配就会进行分词,比如"爱敲代码的的小游子"会被分词为"爱 敲 代码 的 小 游子", 所有有关"爱 敲 代码 的 小 游子", 那么所有包含这三个词中的一个或多个的文档就会被搜索出来。
并且根据lucene的评分机制(TF/IDF)来进行评分。
2、term查询
term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇
9、多个值精确查询

10、高亮查询
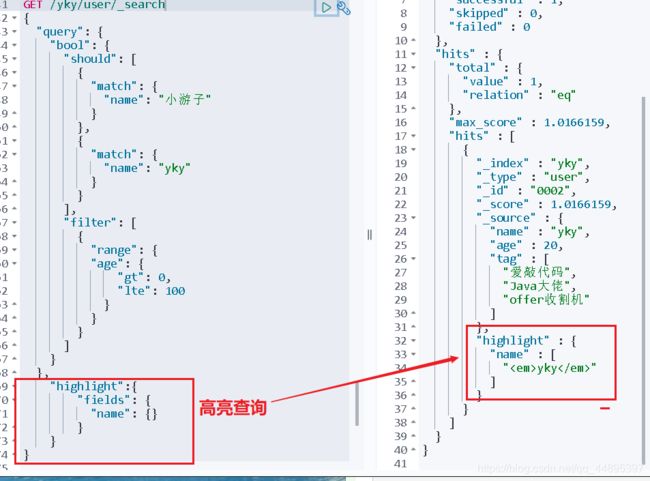
GET yky/user/_search
{
"query": {
"match": {
"name": "小游子"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
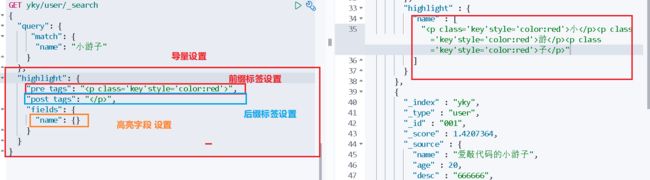
11、自定义搜索高亮查询
GET yky/user/_search
{
"query": {
"match": {
"name": "小游子"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name": {}
}
}
}