完全小白篇-使用Python爬取B站视频(普通视频)
完全小白篇-使用Python爬取网络小说
- 找一个B站视频
- 分析网页信息
- 获得网页信息
- 根据url下载资源
- 1. 摸索规律
- 2. 验证规律
哔哩哔哩相信大家都再熟悉不过了,这一次我想要尝试直接爬取b站的视频,然而搜了好多文章博客好像做法都还处于b站还在使用av号的年代,所以这一次想看看能不能爬取bv号的视频。
找一个B站视频
BV号是B站自2020年3月23日升级后的视频编码。BV号全面取代以前的AV号功能不变。既然现在网站都采用的是BV号,那么随便找一个视频先看看情况:
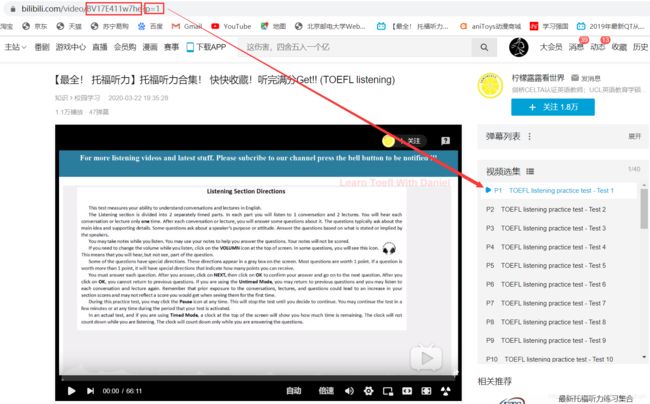
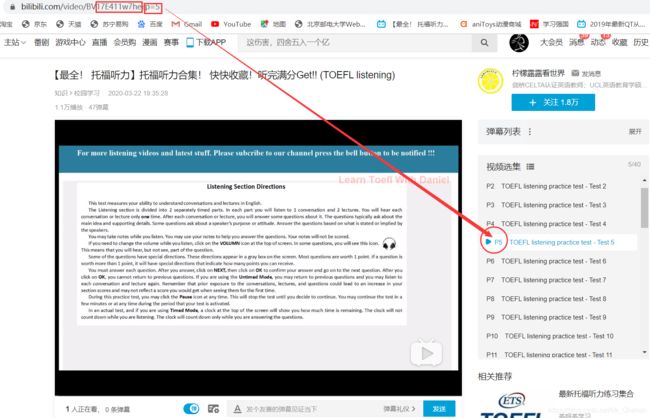
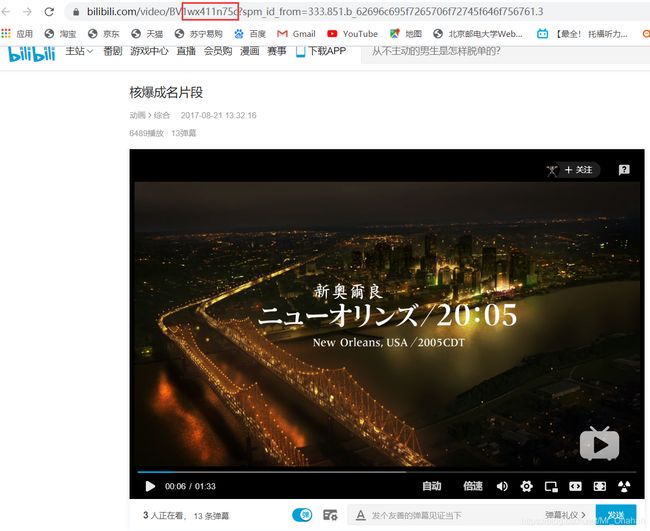
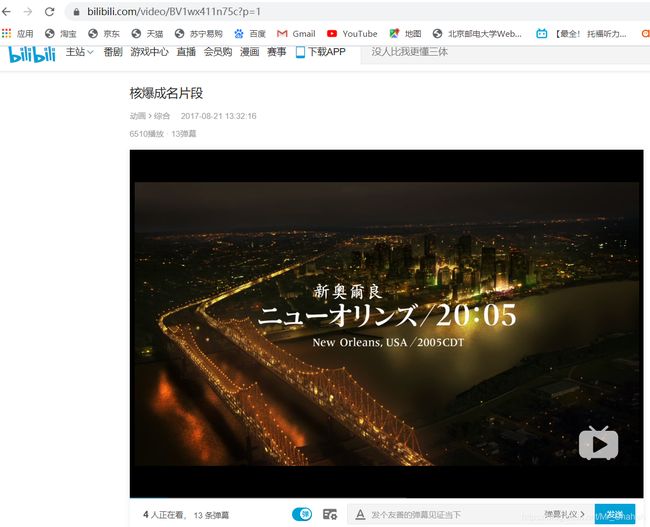
对单一的视频来说,不用看它BV号后面跟着一大串是什么,单一视频就是p序列号为1而已。而对系列视频来说,BV号是固定的,不同的集数就对应不同的p序列号,所以只要确定BV号和p号,就可以定位一个视频的网页啦
分析网页信息
相信大家来之前都应该清楚网络视频是怎么被播放的吧,这里不多赘述“url”是什么了,想爬视频,最重要的就是能获取到视频、音频文件的url信息。过去AV号的时候好像说视频音频文件是合在一起的,BV号推出后我们看到的视频实际上是音频视频分开来的。所以针对BV号视频要把视频(.flv)音频(.mp3)一同获取。
我们先查看网页源代码:

嘿嘿我吐了,不过呢,用ctrl+F搜索就行,搜“url”,


我们会找到一处video类以及一处audio类内的 “baseUrl”、“base_url”、“backupUrl”、“backup_url”,其中,baseUrl的内容就是对应的音视频url。所以只要获取到网页源代码后把这两处析取出来就可以了。
获得网页信息
1. 获取网页源代码
这点不多赘述,模仿自己是浏览器身份用request库函数访问网页就行:
# 用到的库
import requests
from requests import RequestException
from lxml import etree
from contextlib import closing
from pyquery import PyQuery as pq
import re
import os
import json
import subprocess
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": 这个地方填写你的浏览器身份信息,这一点只需随便找个请求把对应的user-agent内容复制过来就行
}
try:
response = requests.get(url = baseurl, headers = head)
# 200表示服务器接受请求,会传回网页源代码,所以把文本内容传回来就行了
if response.status_code==200:
return response.text
except:
print("请求失败")
getHtml()函数的作用就是返回这个网页的源代码,传入该网页地址即可。比如上面图片中的:《核爆成名片段》
2. 接下来要处理网页源代码
# 传入网址、p序列号。这里说明一下,我下载的视频在下载系列时直接用p号命名,方便起见所以这个函数要用p号
def getVideo(baseurl,p):
html = getHtml(baseurl)
doc = pq(html) # pyquery库语法简洁些,所以先采用pyquery库
title = doc('#viewbox_report > h1 > span').text() # 设置视频标题获取规则
pattern = r'\window\.__playinfo__=(.*?)\ ' # 设置类的获取规则
result = re.findall(pattern, html)[0]
temp = json.loads(result)
print(("开始下载--->")+title)
title = str(p)
try:
video_url = temp['data']['dash']['video'][0]['baseUrl']
audio_url = temp['data']['dash']['audio'][0]['baseUrl']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
fileDownload(homeurl=baseurl, url=audio_url, title=title, typ=1)
except Exception:
vedio_url = temp['data']['durl'][0]['url']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
重点在video_url = temp[‘data’][‘dash’][‘video’][0][‘baseUrl’]。想要获得vedio:baseUrl的内容并不适合一步到位,毕竟源代码内容实在太过庞大。所以多走一步,也就是先获取整个网页代码的一个小整体,再在小整体里细分出各个成员。实际上,源代码中这一部分从语法上就是Python的字典只是这个字典里的对应关系包含着小字典、列表、元组等内容。所以层层递进,找到video、audio的baseUrl在第几层相信大家也都可以轻松实现。
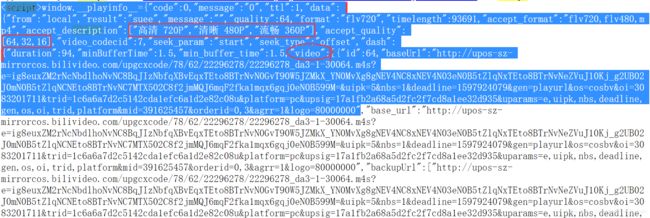
(关于vedio_url = temp[‘data’][‘durl’][0][‘url’],据说AV号的时候音视频是一体的(.mp4吧)而那时的源代码就是这种关系能找到url。)
根据url下载资源
所以最令人兴奋的一个环节来了:下载
下载必然要针对音视频分别下载,问题是现在只有url,我们到底该做什么
当然还是回归到分析网页啦!
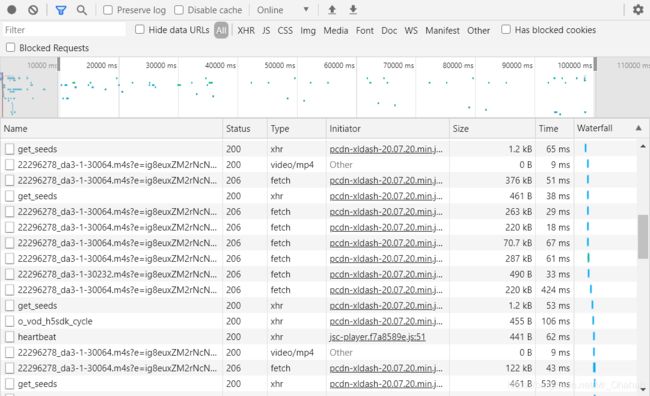
1. 摸索规律
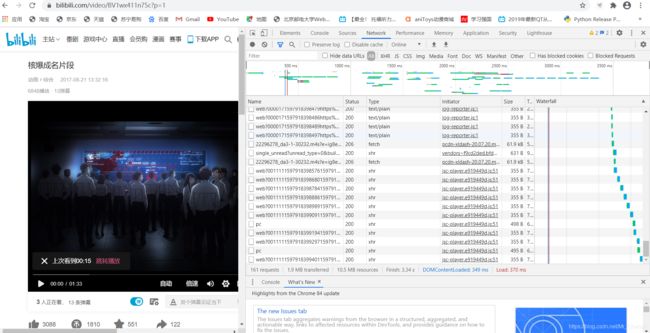
上图的操作是用Google浏览器检查网页–>刷新网页后得到的数据流,现在是暂停状态,我们发现后半段几个均匀的流之后就再也没其他数据传回来了。与此同时,缓冲条也停留在图中的位置,可见这些均匀的流中一定包含音视频流部分,点击播放后肯定也会传回来视频音频流的数据,我们分析的就是它们。
2. 验证规律
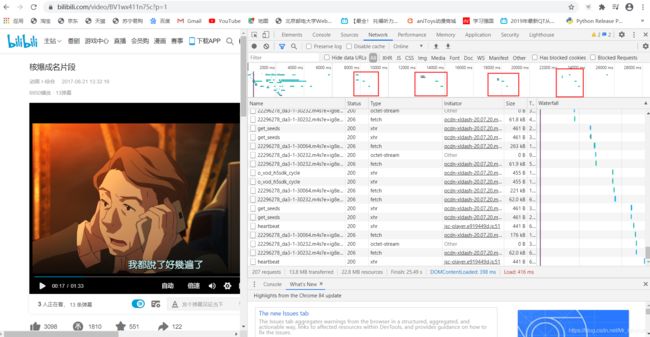
播放后,浏览器周期性的接收到这样的数据流,十分规律,所以我们先只拿第一部分来看。
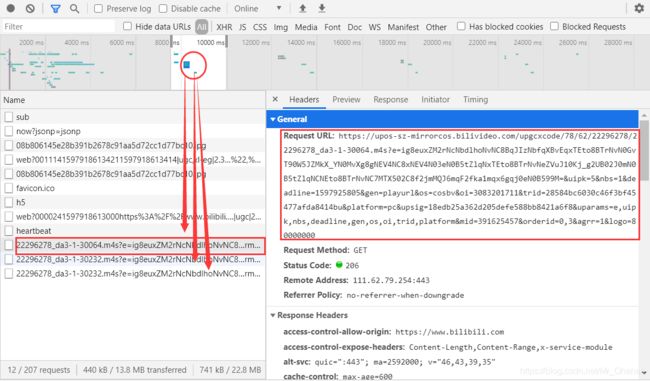
是不是似曾相识???

所以嘞,这些流就是要分析的对象。
我们先对比一下这三个的区别:一样的Request URL等等信息,显著而有关联的区别在于,
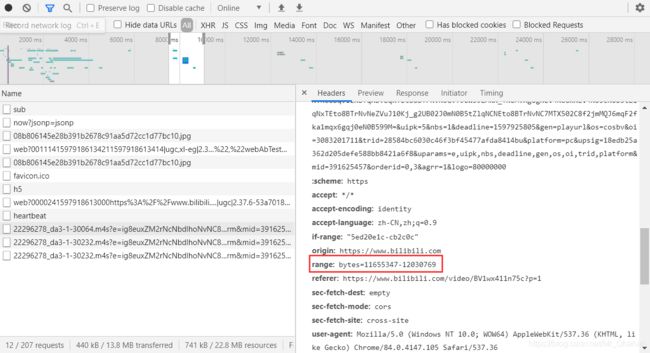

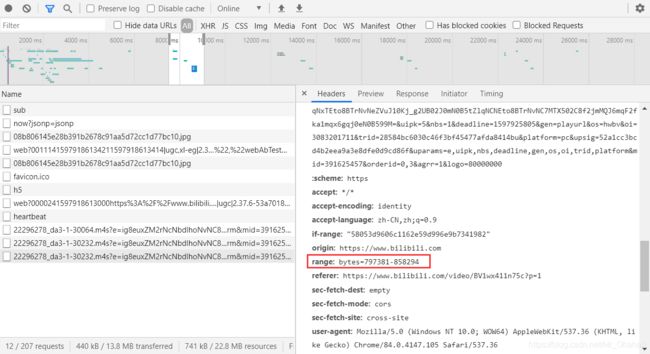
猜想一下,这个range的意义也相当容易看出来,所谓x-y大概就是这个数据包包含了从x到y这一部分。那么接下来回到网页刚刚加载的那段时间,果然发现这类流真的有range: bytes=0-…这一项!
另外,当所有的数据传输完成时,播放要结束,此时,网站给出的http状态码基本都到了206:
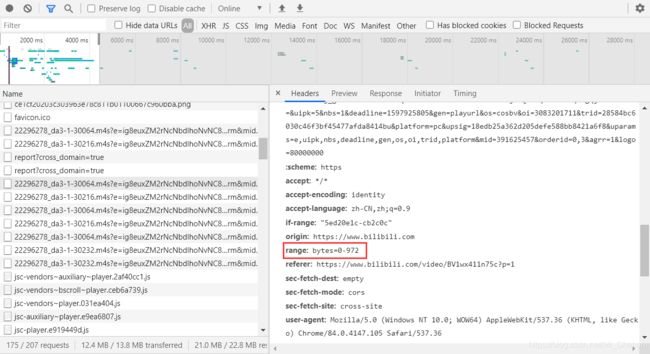
现在我们的下载操作就显而易见了:
1. 模仿浏览器的身份
2. 发出固定range范围的请求
3. 将得到的信息写文件
def fileDownload(homeurl, url, title, typ):
# 添加请求头键值对,写上 refered:请求来源
headers = {
"user-agent": 这个地方还是照旧填写你的浏览器身份信息
}
headers.update({'Referer': homeurl})
if typ==0:
filename = "./"+title+".flv"
else:
filename = "./"+title+".mp3"
res = requests.Session()
# 指定每次下载1M的数据
begin = 0
end = 1024*1024 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = requests.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为416时有数据,由于我们不是b站服务器,最终那个数据包的请求range肯定会超出限度,所以传回来的http状态码是416而不是206
begin = end + 1
end = end + 1024*1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers,verify=False)
flag=1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag==1:
fp.close()
break

最后是main函数:
def main():
print("欢迎来到bilibili爬资源小程序,接下来让我们开始吧\n(番剧爬取程序正在持续开发中...)")
bv=input("输入视频bv号: ")
judge = input("你想获得一系列(y)视频还是一个单一(N)视频?\n[y/N]\n")
if judge == "y":
max = input("输入该系列视频的总数: ")
for p in range(max):
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
else:
p=input("如果是系列视频,请任选一集输入视频p号<------>如果不是系列视频,请输入'1'\n")
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
os.system("pause")
希望对大家有所帮助。
相关资料:HTTP状态码206和416