腾讯2012.9.23校园招聘笔试题
一、选择题
1、数据库表设计最合理的是(A)
A、学生{id,name,age} 学科{id,name} 分数{学生id,学科id,分数}
1NF
2NF
3NF
分析:数据库里面 一般是 学生,学科,分数 分开放。
2、在数据库系统中,产生不一致的根本原因是(D)
A.数据存储量太大 B.没有严格保护数据 C.未对数据进行完整性控制 D.数据冗余
3、15L和27L两个杯子可以精确地装(C)L水?
A. 53 B. 25 C. 33 D. 52
分析:15和27 升水 可以装出 3升水,故:27 + 3 +3 因此33合理。。
4、考虑左递归文法 S->Aa|b、 A ->Ac | Sd |e,消除左递归后应该为(A)
e为空集
消除左递归,即消除 有A->A*的情况
消除做递归的一般形式为
U = Ux1 | U x2 |y1|y2
U = y1U' |y2 U'
U' = x1U'|x2U'|e
A = Ac|Aad|bd|e
A =bdA'|A'
A'= cA'|adA'|e
5、下列排序算法中,初始数据集合对排序性能无影响的是()
A.插入排序 B.堆排序 C.冒泡排序 D.快速排序
6、二分查找在一个有序序列中的时间复杂度为(O(logn))
7、路由器工作在网络模型中的哪一层(网络层)?
分析:主要作用就是选路和转发,当然网络层
8、select foo,count(foo) from pokes where foo>10 group by foo having count(*)>5 order by foo
SQL Select语句完整的执行顺序:
1、from子句组装来自不同数据源的数据;(来自不同的表)
2、where子句基于指定的条件对记录行进行筛选;(条件)
3、group by子句将数据划分为多个分组;(分组)
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、使用order by对结果集进行排序。
因此 合理的答案应该为 from --where-- group by-- having --select-- order by
只有select选出了相应的表 才能对其排序,删除之类的操作
9、深搜如下图,遍历顺序为() (相当于先序遍历)
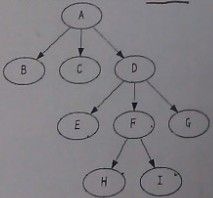
这道题目 我咋看不出来 那个解呢。
如果深度的话 A B C D E F H I G
广度的话 A B C D E F G H I
10、UNIX系统中,目录结构采用(二级目录结构)
11、请问下面的程序一共输出多少个“-”?

#include#include #include int main(void) { int i; for(i=0; i<2; i++) { fork(); //复制父进程,调用一次,返回两次 printf("-"); //缓冲区数据 } return 0; }
答案:8
分析:
如果你对fork()的机制比较熟悉的话,这个题并不难,输出应该是6个“-”,但是,实际上这个程序会很tricky地输出8个“-”。
要讲清这个题,我们首先需要知道fork()系统调用的特性,
- fork()系统调用是Unix下以自身进程创建子进程的系统调用,一次调用,两次返回,如果返回是0,则是子进程,如果返回值>0,则是父进程(返回值是子进程的pid),这是众为周知的。
- 还有一个很重要的东西是,在fork()的调用处,整个父进程空间会原模原样地复制到子进程中,包括指令,变量值,程序调用栈,环境变量,缓冲区,等等。
所以,上面的那个程序为什么会输入8个“-”,这是因为printf(“-”);语句有buffer,所以,对于上述程序,printf(“-”);把“-”放到了缓存中,并没有真正的输出,在fork的时候,缓存被复制到了子进程空间,所以,就多了两个,就成了8个,而不是6个。
另外,多说一下,我们知道,Unix下的设备有“块设备”和“字符设备”的概念,所谓块设备,就是以一块一块的数据存取的设备,字符设备是一次存取一个字符的设备。磁盘、内存都是块设备,字符设备如键盘和串口。块设备一般都有缓存,而字符设备一般都没有缓存。
对于上面的问题,我们如果修改一下上面的printf的那条语句为:
printf("-\n");
或是
printf("-"); fflush(stdout);
就没有问题了(就是6个“-”了),因为程序遇到“\n”,或是EOF,或是缓中区满,或是文件描述符关闭,或是主动flush,或是程序退出,就会把数据刷出缓冲区。需要注意的是,标准输出是行缓冲,所以遇到“n”的时候会刷出缓冲区,但对于磁盘这个块设备来说,“n”并不会引起缓冲区刷出的动作,那是全缓冲,你可以使用setvbuf来设置缓冲区大小,或是用fflush刷缓存。
12、接上
#include#include #include int main(void) { int i; for(i=0; i<2; i++) { fork(); //复制父进程,调用一次,返回两次 printf("-\n"); //缓冲区数据 } return 0; }
答案:6
13、避免死锁的一个著名算法是(银行家算法)
14、你怎么理解分配延迟(dispatch lantency)的?
分析:分配延迟 一般指进程切换时间 在进程调度哪里,只有A进程切换
15、不是进程的基本状态的是(D)
A. 阻塞态 B.执行态 C.就绪态 D.完成态
16、任务 1 : cpu 3.5分钟 io 14分钟
任务 2 : 10分钟后 cpu 2 分钟 io 8分钟
任务3 : 15分钟后 cpu 1.5分钟 io 6分钟
查了资料 io 花费p 则多道程序 cpu占用率 为 1-p^n只有 多个都处于等待才不是cpu时间
因此 分析过程如下
0-10分钟 cpu时间 10*0.2 = 2
10-15分钟 cpu利用率为 1-0.8^2 = 0.36 所以这 5分钟里面 cpu时间 为 0.36*5 =1.8
15 -之后 cpu利用率 1-0.8^3 = 0.488
0-10提供2分钟cpu时间
10-15 提供1.8分钟cpu时间
15 -18.7 提供1.8分钟cpu
18.7-21.5提供 1分钟cpu
21.5-23.5提供0.4分钟cpu时间
故,总共花费23.5分钟
17、在所有非抢占CPU调度算法中,系统平均响应时间最优的是(C)
A.实时调度 B.段任务优先 C.时间片轮转 D.先来先服务
18、什么是内存抖动(Thrashing)(A)?
A.非常频繁的换页活动
19、Belady's Anomaly出现在哪里()?
Belady异常(Belady‘s anomaly):对有的页置换算法,
页错误率可能会随着所分配的帧数的增加而增加,
而原期望为进程增加内存会改善其性能。
A内存管理算法 B内存换页算法 C预防死锁算法 D磁盘调度算法
分析:Belady异常(Belady Anomaly):有些情况下,页故障率(缺页率)可能会随着所分配的帧数的增加而增加。
20、生产者消费者中不产生死锁的程序是(A)
#define N 100 //定义缓冲区大小
typedef int semaphore; //定义信号量类型
semaphore mutex = 1; //互斥信号量
semaphore empty = N; //缓冲区计数信号量,用来计数缓冲区的空位数量
semaphore full = 0; //缓冲区计数信号量,用来计数缓冲区里的商品数量
void producer(void)
{
int item;
while(true) {
item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer(void)
{
int item;
while(true) {
down(&full);
down(&mutex);
item = remove_item();
up(&mutex);
up(&empty);
consume_item(item);
}
}。。。。。。
二、填空题
21、将下图进行拓扑排序得:ABCFD
分析:非常简单,把握一个原则。。目的节点一定不排在源节点前边
22、补充完整二分查找:
tail=mid-1;、head = mid;
23、补充完整求连续子数组最大和
nStart = max(nStart+A[i],0); nAll = max(nAll,nStart);
24、给一二叉树,写出先序遍历顺序。。abdefghc
25、最长递增子序列,得到其长度的最优化时间复杂度为(O(nlogn)),空间复杂度为(O(n))
26、入栈出栈顺序问题,卡特兰数:n=5,那么。。。。C(2n,n)/(n+1)
27、a+b*(c-d)/e-f的逆波兰式是:abcd-*e/+f- (后序遍历)
三、附加题
1、海量数据处理。。获取T级别条字符串中的出现次数最多的前10个关键字
(TB级别的关键字,分析出其中出现最多的是个关键字)
2、设计一个IP统计系统(后台统计系统)




