深度学习(十八)——YOLOv2(2), 语义分割
YOLOv2
Stronger(续)
Hierarchical classification(层次式分类)
ImageNet的标签参考WordNet(一种结构化概念及概念之间关系的语言数据库)。例如:
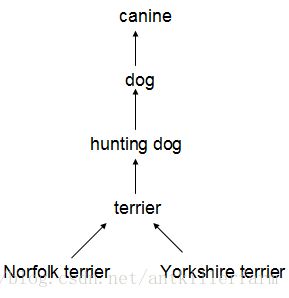
很多分类数据集采用扁平化的标签。而整合数据集则需要结构化标签。
WordNet是一个有向图结构(而非树结构),因为语言是复杂的(例如“dog”既是“canine”又是“domestic animal”),为了简化问题,作者从ImageNet的概念中构建了一个层次树结构(hierarchical tree)来代替图结构方案。这也就是作者论文中提到的WordTree。
WordTree的细节,更偏NLP一些,这里不再赘述。
参考
https://zhuanlan.zhihu.com/p/25167153
YOLO2
http://blog.csdn.net/jesse_mx/article/details/53925356
YOLOv2论文笔记
http://lanbing510.info/2017/09/04/YOLOV2.html
目标检测之YOLOv2
其它目标检测网络
A-Fast-RCNN
A-Fast-RCNN首次将对抗学习引入到了目标检测领域,idea是非常创新的。
http://blog.csdn.net/jesse_mx/article/details/72955981
A-Fast-RCNN论文笔记
R-FCN
FCN在目标检测领域的应用。
http://blog.csdn.net/zijin0802034/article/details/53411041
R-FCN: Object Detection via Region-based Fully Convolutional Networks
G-CNN
G-CNN是MaryLand大学的工作,论文主要的思路也是消除region proposal,和YOLO,SSD不同,G-CNN的工作借鉴了迭代的想法,把边框检测等价于找到初始边框到最终目标的一个路径。但是使用one-step regression不能处理这个非线性的过程,所以作者采用迭代的方法逐步接近最终的目标。
http://blog.csdn.net/zijin0802034/article/details/53535647
G-CNN: an Iterative Grid Based Object Detector
语义分割
Semantic segmentation是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。
我们都知道,图像是由许多像素(Pixel)组成,而“语义分割”顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。

上图是语义分割网络ENet的实际效果图。其中,左图为原始图像,右图为分割任务的真实标记(Ground truth)。
显然,在图像语义分割任务中,其输入为一张HxWx3的三通道彩色图像,输出则是对应的一个HxW矩阵,矩阵的每一个元素表明了原图中对应位置像素所表示的语义类别(Semantic label)。
因此,图像语义分割也称为“图像语义标注”(Image semantic labeling)、“像素语义标注”(Semantic pixel labeling)或“像素语义分组”(Semantic pixel grouping)。
由于图像语义分割不仅要识别出对象,还要标出每个对象的边界。因此,与分类目的不同,相关模型要具有像素级的密集预测能力。
目前用于语义分割研究的两个最重要数据集是PASCAL VOC和MSCOCO。
参考:
https://zhuanlan.zhihu.com/p/21824299
从特斯拉到计算机视觉之“图像语义分割”
https://zhuanlan.zhihu.com/SemanticSegmentation
一个语义分割的专栏
https://zhuanlan.zhihu.com/p/22308032
图像语义分割之FCN和CRF
https://zhuanlan.zhihu.com/p/25515361
图像语义分割之特征整合和结构预测
https://zhuanlan.zhihu.com/p/27794982
语义分割中的深度学习方法全解:从FCN、SegNet到各代DeepLab
https://mp.weixin.qq.com/s/cANlqQAI-A2mC9vnd3imQA
Instance-Aware图像语义分割
https://mp.weixin.qq.com/s/v_TLYYq6cFWuwR9tXM8m-A
如何通过CRF-RNN模型实现图像语义分割任务
https://mp.weixin.qq.com/s/ceCC7Q6yr0QKESeZXi6lWQ
堆叠解卷积网络实现图像语义分割顶尖效果
https://mp.weixin.qq.com/s/4BvvwV11f9MrrYyLwUrX9w
还在用ps抠图抠瞎眼?机器学习通用背景去除产品诞生记
https://zhuanlan.zhihu.com/p/24738319
“见微知著”——细粒度图像分析进展综述
https://mp.weixin.qq.com/s/V4_euZRcyyxeimXAA_waAg
贾佳亚:最有效的COCO物体分割算法
https://mp.weixin.qq.com/s/Amr34SdrPZho1GQpFS7WBA
见微知著:语义分割中的弱监督学习
https://mp.weixin.qq.com/s/mQqEe4LC0VHBH2ZAtFanWQ
基于深度学习的图像语义分割方法回顾
https://mp.weixin.qq.com/s/zOWA1oKbopZJuYIAYYlKTA
港中文-商汤联合论文:自监督语义分割的混合与匹配调节
前DL时代的语义分割
从最简单的像素级别“阈值法”(Thresholding methods)、基于像素聚类的分割方法(Clustering-based segmentation methods)到“图划分”的分割方法(Graph partitioning segmentation methods),在DL“一统江湖”之前,图像语义分割方面的工作可谓“百花齐放”。在此,我们仅以“Normalized cut”和“Grab cut”这两个基于图划分的经典分割方法为例,介绍一下前DL时代语义分割方面的研究。
Normalized cut
Normalized cut (N-cut)方法是基于图划分(Graph partitioning)的语义分割方法中最著名的方法之一,于2000年Jianbo Shi和Jitendra Malik发表于相关领域顶级期刊TPAMI。
通常,传统基于图划分的语义分割方法都是将图像抽象为图(Graph)的形式 G=(V,E) G = ( V , E ) ( V V 为图节点, E E 为图的边),然后借助图理论(Graph theory)中的理论和算法进行图像的语义分割。
常用的方法为经典的最小割算法(Min-cut algorithm)。不过,在边的权重计算时,经典min-cut算法只考虑了局部信息。如下图所示,以二分图为例(将 G G 分为不相交的 A,B A , B 两部分),若只考虑局部信息,那么分离出一个点显然是一个min-cut,因此图划分的结果便是类似 n1 n 1 或 n2 n 2 这样离群点,而从全局来看,实际想分成的组却是左右两大部分。
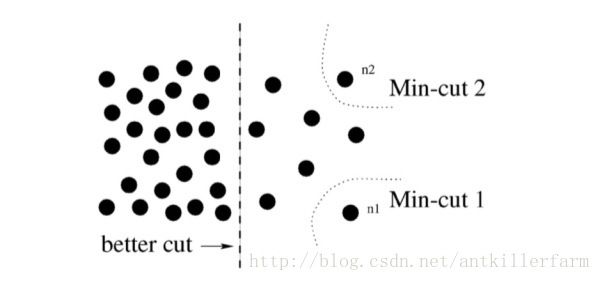
针对这一情形,N-cut则提出了一种考虑全局信息的方法来进行图划分(Graph partitioning),即,将两个分割部分 A,B A , B 与全图节点的连接权重( assoc(A,V) a s s o c ( A , V ) 和 assoc(B,V) a s s o c ( B , V ) )考虑进去:
如此一来,在离群点划分中, Ncut(A,B) N c u t ( A , B ) 中的某一项会接近1,而这样的图划分显然不能使得 Ncut(A,B) N c u t ( A , B ) 是一个较小的值,故达到考虑全局信息而摒弃划分离群点的目的。这样的操作类似于机器学习中特征的规范化(Normalization)操作,故称为Normalized cut。N-cut不仅可以处理二类语义分割,而且将二分图扩展为K路(K-way)图划分即可完成多语义的图像语义分割,如下图例。
