还在为DST模型刷不动而感到苦恼吗?来试试无监督DST吧,DSI等你来战!

本文介绍一篇西湖大学联合哈尔滨工业大学 SCIR 实验室和北京理工大学发表于 IJCAI 2020 的论文 Dialogue State Induction Using Neural Latent Variable Models。

论文链接:
https://www.ijcai.org/Proceedings/2020/0532.pdf
代码链接:
https://github.com/taolusi/dialogue-state-induction
PPT链接:
https://taolusi.github.io/qingkai_min/assets/pdf/20-ijcai-dsi_slides.pdf
视频链接:
https://www.bilibili.com/video/BV1fV41127tq
对话状态跟踪模块是任务型对话系统中的核心部件,目前主流的对话状态跟踪的方法需要在大量人工标注的数据上进行训练。然而,对于现实世界中的各种客户服务对话系统来说,人工标注的过程存在代价高、标注慢、错误率高以及难以覆盖数量庞大的不同领域等问题。
基于这些问题,我们提出了一个新的任务:对话状态推理,目标是从大量无标注的客服对话记录中自动挖掘对话状态,并提出了两个基于神经隐变量的模型来实现无监督的对话状态推理,同时我们在下游的对话生成任务中进行了验证,实验结果表明,相比于缺少对话状态的对话系统,使用我们推理得到的对话状态可以获得更好的表现。

背景
1.1 任务型对话系统
任务型对话系统(task-oriented dialogue system)的目标是协助用户完成特定的任务,比如订机票、打车、日程管理等。
一个典型的任务型对话系统可以分为四个模块:自然语言理解(natural language understanding, NLU)、对话状态追踪(dialogue state tracking, DST)、策略学习(dialogue policy)以及自然语言生成(natural language generation, NLG),在这个过程中需要跟各种各样的数据库进行查询甚至更新等操作。

▲ 图1 任务型对话系统
(图片来源于:Gao J, Galley M, Li L. Neural approaches to conversational AI[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1371-1374.)
1.2 对话跟踪模块及其限制
对话状态跟踪模块是任务型对话系统的一个核心模块,对话状态表示了用户在每轮对话所寻求的内容的关键信息,它是从对话开始到当前轮的所有信息的累积,表示形式是一些 slot-value pairs 的集合,inform 表示用户对所寻求的内容的限制,request 表示用户想要寻求哪些内容。

▲ 图2 对话状态表示
传统的 DST 的做法是先通过 NLU 模块对用户对话进行意图识别和槽位解析,然后将结果输入到 DST 模块中,由 DST 模块处理 NLU 模块带来的一些不确定性,得到最终的对话状态。目前越来越多的工作直接通过一个端到端的 DST 模型来直接处理用户对话(以及历史对话记录)得到当前的对话状态,如图 3 所示。

▲ 图3 端到端的DST
端到端的 DST 模型虽然已经在标准的数据集(如 EMNLP 最佳资源论文 MultiWOZ 数据集)取得了绝大的成功,但是这种方法依赖于人工标注的大量语料,由于对话状态本身的复杂性非常高,需要对语义以及上下文有一个整体的理解,所以导致人工标注的过程存在两个非常大的问题:
昂贵的标注代价:在 MultiWOZ2.0 数据集中一共标注了 8438 组对话,一共竟然用了 1249 个标注人员。
过高的标注错误率:根据相关论文统计,MultiWOZ2.0 数据集中有大约 40% 的标注错误;而在此基础上更新的 MultiWOZ2.1 数据集也有超过 30% 的错误;目前最新版已经更新到了 MultiWOZ2.2。
从这两点可以看出想要构建大规模高质量的数据集存在非常大的困难,这也导致虽然对于任务型对话系统的研究在一些领域上已经取得了一定的成功,但是也非常受限于这些已经标注好大量语料的领域,在实际应用中,会有大量新的领域存在,面对每一个新的领域都要人工标注新的数据集是不太实际的。

▲ 图4 端到端的DST所面临的新领域问题

动机
2.1 新任务:对话状态推理 (dialogue state induction, DSI)
在这种情况下,如何能够从对话记录中自动发现对话状态显得十分重要。我们假设可以获得大量来自不同领域的对话记录,而这些对话记录是没有对话状态标注的,通常这样的语料是相对容易获得的,比如可以来源于不同商业服务中已经积累的人工客服与用户的对话记录。
基于这种假设,我们提出了一个新的任务:对话状态推理(dialogue state induction, DSI),任务的目标是从大量的生对话语料中自动推理得到对话状态,并能更好的用于下游任务比如策略学习和对话生成。
DSI 与 DST 的区别如图 5 所示,和 DST 相似的是,DSI 的输出也是 slot-value pairs 形式的对话状态,不同的是,在训练过程中 DST 依赖于对话语料以及人工标注的对话状态,而 DSI 不依赖于人工标注,可以在生对话中自动生成 slot-value pairs。
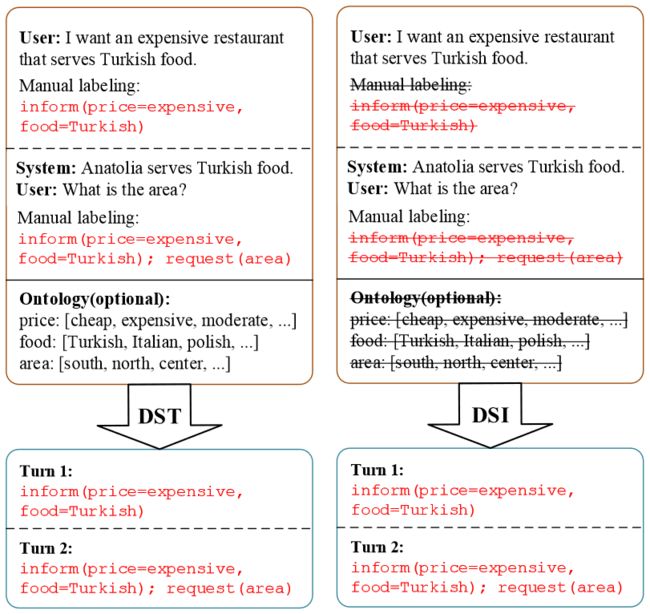
▲ 图5 DST与DSI对比
除了我们提出的 DSI 任务之外,谷歌的研究者也提出了通过 zero-shot DST 的方案来缓解标注数据缺失的问题,他们主要利用了一些相似的领域之间可能存在相似的槽位的这一特点,比如订火车票和订机票两个领域都存在像出发地、到达地和出发时间、到达时间等槽位,通过对领域和槽位进行自然语言的描述来建立不同领域之间的联系。
这种方法确实可以在一定程度上解决未知领域的问题,但是这种方法同样需要对不同领域的槽位进行高质量(一致性高)的标注,同时在面对新的与已知的领域关联性不大的领域时(比如金融领域),很难从已知的领域迁移到这些全新的领域。


▲ 图6 Zero-shot DST及其限制
而我们提出的 DSI 任务进一步减轻了对人工标注的依赖,我们希望通过数据驱动的方式,采用无监督的方法从生对话中自动挖掘出对话状态的信息。

方法
我们的方法分为两个步骤:1)候选词抽取(通过 POS tag、NER 和 coreference);2)为候选词分配合适的槽位。
其中第一步是一个预处理的过程,第二步我们建立了两个无监督的神经隐变量模型 DSI-base 和 DSI-GM 来为每个候选词分配一个槽位索引(slot-index),其中 DSI-GM 可以认为是 DSI-base 的一个变种。

▲ 图7 两个步骤来解决DSI
3.1 VAE简介
在说 VAE 之前,先来看一下它的前身 AutoEncoder (AE)。AE 是非常知名的自编码器,它通过自监督的训练方式,能够从原始特征获得一个潜在的特征编码,实现了自动化的特征工程,并且达到了降维和泛化的目的。它的网络结构很简单,有编码和解码两个部分组成:
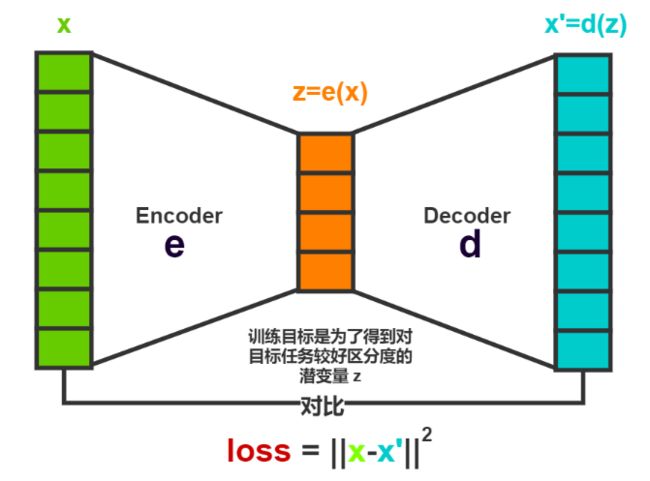
▲ 图8 AutoEncoder
从图中可以看出,AutoEncoder 被认为自监督是因为它的目标就是输入本身,不需要额外的标签。AutoEncoder 虽然是由编码器和解码器两部分构成的,但是它的重点是通过编码得到隐藏层的向量,用来表示输入的潜在的特征。
解码的作用是重建输入数据,通过优化使得重建的输入和真实的输入尽可能的类似,从而达到压缩数据的目的。尽管通过这种方式得到的隐变量的维度要远小于输入的原始数据,但是这种隐藏空间的分布并不是连续的,导致在解码的过程中,解码器很难正常的重建输入数据。

▲ 图9 Variational AutoEncoder
VAE 假设经过神经网络编码后的隐变量符合标准的高斯分布,也就是从一个高斯分布中采样得到隐变量 z,具体的做法不再通过编码器直接得到一个隐变量 z,而是得到两个向量,这两个向量作为高斯分布的参数,从这个分布中采样得到隐变量 z,然后通过解码器重建得到输入数据。
VAE 的这种假设使得抽取出来的隐藏特征直接拟合了已知的潜在概率分布,从而得到了连续完整的潜在空间,拥有了更强大的表达能力。
VAE 训练过程的 loss 分为两个部分:一个是重建项(reconstruction term),还有一个是正则项(regularization term)。第一部分的目的是让隐变量能够尽可能表示输入数据的特征,第二个部分是使得编码得到的后验分布尽可能接近先验的标准高斯分布。
3.2 模型1:DSI-base
在 DSI 的任务设置里,对话状态对我们来说是未知的,而对话状态又表示了当前对话中最关键的信息,因此我们将对话状态表示为隐变量 z。
和 VAE 类似,我们的模型也分为三个部分:Encoder、Sampling 和 Decoder。
Encoder 的目的是通过神经网络将对话输入编码得到一个多元高斯分布的参数 和 ,这个高斯分布应该能够尽量好的表示当前的对话状态并尽可能地贴近标准的多元高斯分布;Sampling 利用当前的高斯分布采样得到表示当前对话状态的隐变量 z;Decoder 的目的是通过神经网络将隐变量 z 解码为当前的对话输入。
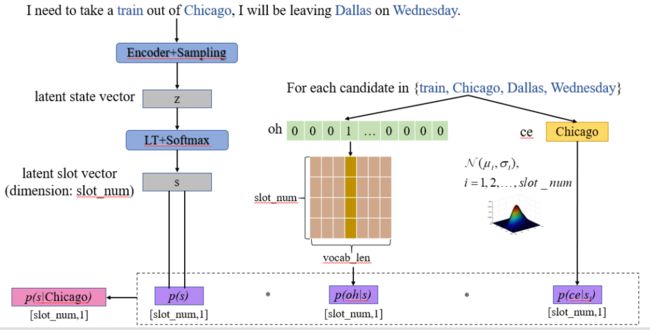
我们以下边这句对话为例来解释一下我们的模型(蓝色字表示在预处理过程得到的 candidates):
I need to take a train out of Chicago, I will be leaving Dallas on Wednesday.
首先介绍 encoder 部分:在 encoder 中,我们首先将对话表示为两种形式:one-hot(oh)表示和 contextualized embedding(ce)表示。
oh 是对句子的一种离散化的向量表示,oh 的长度是语料中所有候选词的数量,当前对话中出现了哪些候选词,就将其对应的位置置为 1,其余的位置置为 0,然后通过 linear transformation + SoftPlus + Dropout 将 oh 编码为 encoded_oh。
ce 是对子的一种连续性的向量表示,将当前对话经过了一个预训练好的语言模型(如 ELMo、BERT),可以得到每个单词在当前对话中的上下文表示,我们将每个候选词的上下文表示取出,先对所有的候选词做 AvgPooling 得到当前句子的整体表示,然后然后通过 linear transformation + SoftPlus + Dropout 将 ce 编码为 encoded_ce。
然后将 encoded_oh 和 encoded_ce 拼接起来,分别经过 linear transformation + BatchNorm 得到后验高斯分布的参数 posterior 和posterior 。
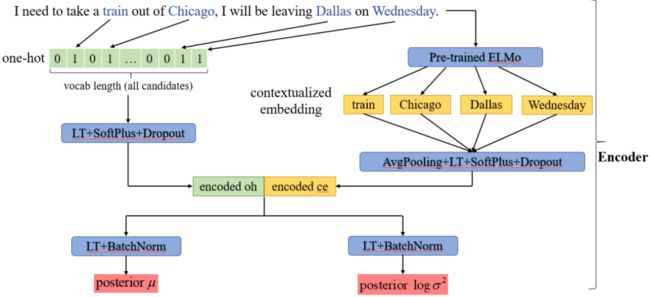
▲ 图10 Encoder
接下来是 sampling 过程:在得到高斯分布的参数之后我们要通过随机采样得到隐变量 z,但是随机采样的过程是没办法求导的,所以没办法进行梯度的回传,这时候需要采用一个重参数化技巧(reparameterization trick),将 z 的采样过程转变为 ,这样使得采样过程变得可导。

▲ 图11 Sampling
最后是 decoder 部分:在得到隐变量 z 之后我们需要通过一个 decoder 来重新得到当前对话的表示 oh 和 ce。这时我们首先通过 transformation+Softmax 得到另一个隐变量 s,隐变量 s 表示了当前对话中 slot 的概率分布,s 的维度是预设的 slot 的数量,是一个调整的超参数。
接下来我们首先通过一个 linear transormation+BatchNorm 得到重建的 oh 表示,reconstructed_oh 的维度也是所有 candidate 的数量。
除此之外,我们还想要得到重建得到上下文表示 ce,这是我们将上下文 ce 的重建转换为重建一个能够表示上下文分布规律的多元高斯分布,也就是说对这个多元高斯分布采样能够以比较更好地得到当前的 ce。
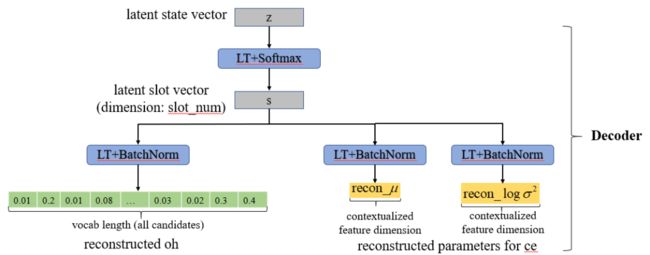
▲ 图12 Decoder
我们的模型的优化过程和 VAE 类似,模型的 loss 分为两个部分:重建项和正则项,我们的重建项又分为两个部分,一部分是对 oh 表示的重建,另一部分是对 ce 表示的重建。
对 oh 的重建我们通过对 reconstructed_oh 和真实的 oh 求 cross entropy loss:

对 ce 的重建我们转化为提高我们重建得到的多元高斯分布采样得到 ce 的概率,也就是说我们将高斯分布取得候选词的概率取反作为 loss,然后将所有的候选词对应的 loss 相加,这样我们优化 loss 就是不断提高重建的高斯分布能够得到候选词上下文表示的概率。
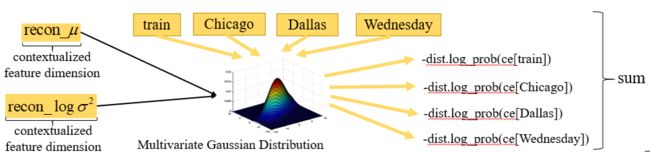
对于正则项来说,我们计算后验的高斯分布和标准的高斯分布的 KL 散度作为 loss,通过优化 loss 来不断拉近后验的高斯分布与标准高斯分布之间的距离。

模型训练完之后,我们看一下模型是如何进行预测的?通过和训练过程完全相同的 encoder 和 sampling 模块,得到隐变量 z,然后通过 linear transformation+softmax 得到隐变量 s,此时的 s 代表当前对话中不同 slot 的分布概率,但是这个概率针对每一轮的对话来说的,我们并不知道概率较高得几个 slot 分别对应哪些 candidate,那么怎么对不同的 candidate 进行区分呢?

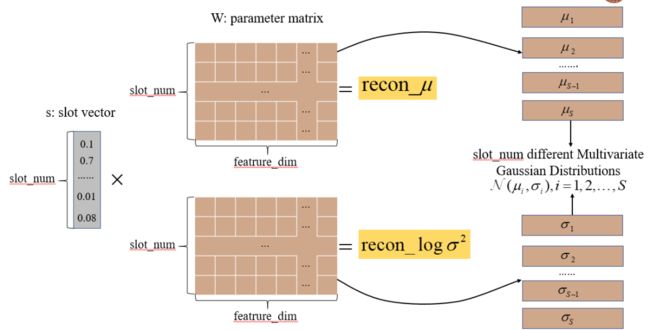
我们先来看一下除了 encoder,模型在 decoder 模块中学到了什么。首先从第一部分 oh 的重建过程,由 slot 的表示 s 到 oh 的 linear transformation 中可以得到一个 [slot_num, vocab_len] 的参数矩阵 W,如下图所示。
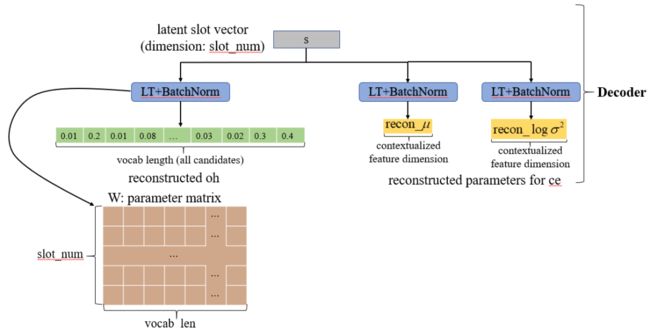
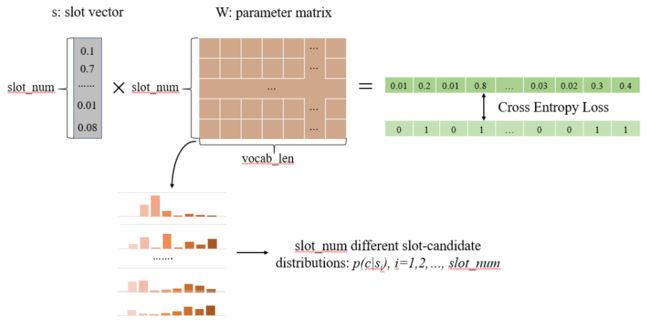
那么这个参数矩阵 W 的含义是什么呢?做完 softmax 后的隐变量 s 可以代表不同的 slot 的概率,和参数矩阵相乘可以看作将是对 W 每行的参数进行加权求和,得到 reconstructed_oh,然后和实际的 oh 求交叉熵。
因为在 oh 中当前对话出现的 candidate 被置为 1,其余的 candidate 被置为 0,这些被置为 1 得 candidate 可能属于当前对话不同的 slot,而同一个 slot 中出现的 candidate 有很高的重复性(比如火车的起点是一个固定的集合)。
那么经过多次数据优化之后的结果就是隐变量 s 中当前对话中出现的 slot 对应的那些维接近 1,不出现的 slot 的那些维接近 0,s 中接近 1 的那些维映射到参数矩阵 W 的对应行中,这些 slot 中经常得 candidate 对应的那些维接近 1,其余的接近 0。
这样经过对 W 每一行的加权平均相当于取出 slot 对应的 candidate 相加得到 oh,那么 W 的每一行就可以看作某个 slot 中所有 candidate 出现的概率。
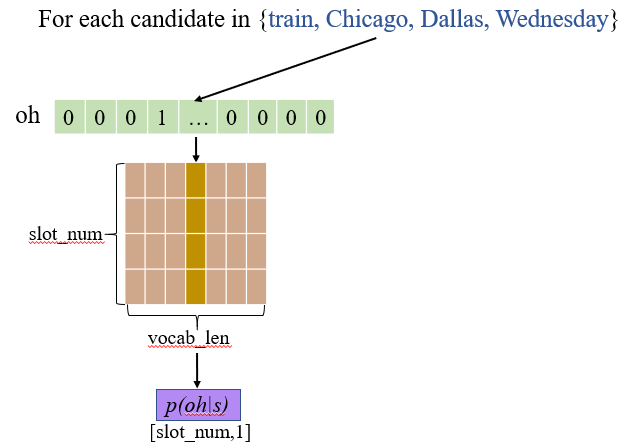
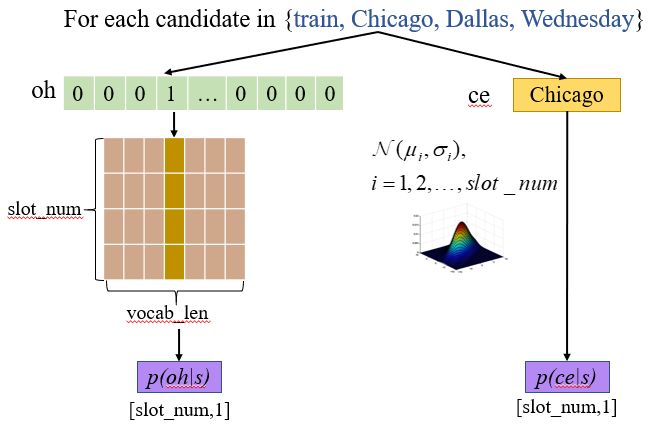
这样我们可以利用参数矩阵 W 来判断每个 candidate 属于各个 slot 的概率,和我们训练过程中求交叉熵 loss 的优化方式一样,我们将 candidate 的 one-hot 表示与 W 的每一行点对点相乘,可以看作在每一个 slot 下能够得到当前 candidate 的概率。
和当前对话的 oh 表示可能存在多个 1 不同的是,每个 candidate 的 one-hot 表示只有一维是 1,和 W 的每一行点积的过程可以看作是将 W 中的对应列取出的过程,这样就得到了 candidate 得到属于每个 slot 的概率。
同样我们看一下模型在对 ce 的 decode 过程中学到了什么?我们可以在重建得到高斯分布的两个参数 和 的过程中得到两个参数矩阵,接下来我们也来分析一下这两个参数矩阵的含义。

类似于 oh 重建过程,得到参数 和 的过程也可以看做是对两个参数矩阵的加权求和过程: 和 是对当前对话整体的上下文的一个表示,而 s 表示了当前对话中每个 slot 出现概率,那么这两个参数矩阵中每一行就是每个 slot 对应的上下文的表示,多个不同的 slot 进行加权求和,得到了整体的上下文表示。
我们将两个参数矩阵中对应的每一行 和 取出来,可以作为每个 slot 对应的能够表示相应上下文的高斯分布的参数,由此得到了 slot_num 个不同的多元高斯分布。
我们利用 slot_num 个不同的高斯分布,可以计算每个高斯分布采样得到 candidate 的 ce 的概率,作为 candidate 属于不同 slot 的概率。
我们将得到的三个概率相乘,最终得到 candidate 属于每个 slot 的概率,取其中最大的作为当前 candidate 对应的 slot。
因为我们采取的是无监督的方式来为每一个 candidate 预测 slot,对应于每个 candidate 我们得到的是 slot 的索引,和所有无监督的方式一样,我们需要有一个后处理的为每一个 slot 的索引分配一个合适的标记。
如图所示,我们将分配到同一个 slot 下的 candidate 聚集起来,通过多数投票的方式,观察其中大多数的 candidate 实际应该属于哪个合适的label,将这个 label 分配给当前的 slot,这样得到了每个 slot 对应 label 的一个字典,通过这个字典将预测的 slot 索引替换为实际的 label。


3.3 模型2:DSI-GM
目前任务型对话系统的构建都是建立在多领域的语料之上,其中一些领域可能有相似的 slot,比如 train 和 taxi 这两个领域可能有相似的 slot 包括 arrive by、leave at、destination 和 departure。
而相似的 slot 之间上下文可能是非常类似的,比如对于 arrive by 这个 slot 来说,不同的领域可能共享了“I need by arrive by xxx”,而对于 departure 这个 slot 来说,不同的领域可能共享了“I need departure from xxx”。
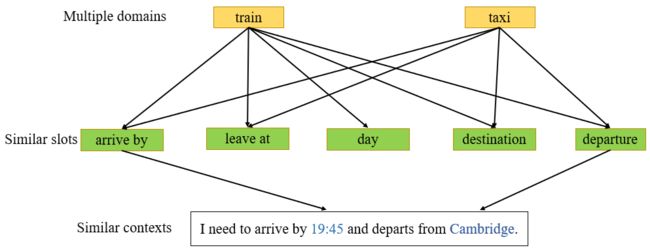
针对这种情况,我们提出了 DSI-GM 模型来解决这个问题。在 DSI-base 模型中,所有不同的领域和槽位都通过一个高斯分布来进行建模,这样不同领域的相似的 slot 因为其具有相似的上下文可能导致模型无法对这些 slot 进行区分。
在 DSI-GM 模型中,我们利用高斯混合模型(A Mixture-of-Gaussians)来对隐变量 z 进行建模,每一个单个的子模型来对一个领域进行建模,这样在避免了不同领域的相似 slot 被混合在一起的情况,可以在领域这个维度上对对话进行更加清晰地建模。
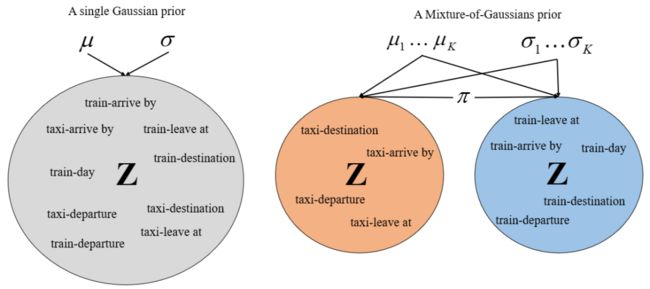
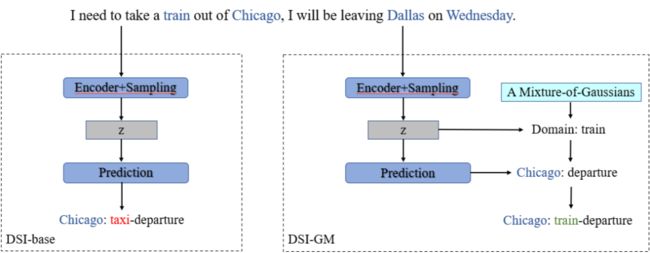
DSI-GM 模型实际是什么样的呢?相对于 DSI-base 模型在通过 encoder 和 sampling 得到隐变量之后直接预测得到 slot 来说,DSI-GM 在得到隐变量 z 之后,通过和先验的 K 个高斯分布子模型进行对比。
首先预测出当前对话的领域,在此基础上,在利用 z 和 decoder 模块预测得到 slot,当前的领域和 slot 共同组成了当前的 slot(实际 slot 是由领域和 slot 两部分组成),DSI-GM 模型具体的训练和预测过程请详见我们的论文。

实验
我们在 MultiWOZ2.1 和 SGD 两个数据集上进行了实验,我们从两个层面对我们的结果进行了评价,一个是传统的 joint level,joint level 的 dialogue state 是从对话开始到当前对话所有的信息的累积,另一个是 turn level,turn level 的 dialogue state 是仅对当前轮对话的局部信息的表示。
在这两个层面上,我们分别通过两个指标对结果进行了评价,一个是 accuracy,当对话状态中所有的 slot-value pairs 被识别对才认为是正确;另一个是 state matching(precision, recall, F1),用来评价推理得到的 slot-value pairs 的覆盖率。

从结果中可以看出,相对于随机分配的 slot,通过我们的模型可以有效地推理出对话状态,我们采用的高斯混合模型在 DSI-base 的基础上有明显的提高。但是从 accuracy 来看,我们的结果还比较低,这也反映出了无监督的 DSI 任务的难度,仍然有很大的提升空间。
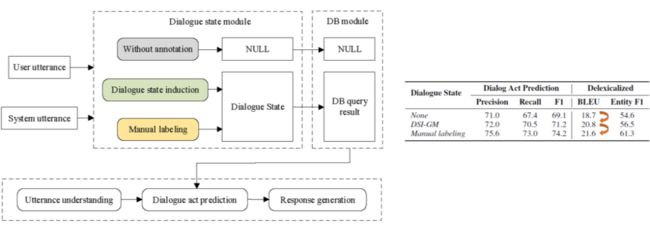
除此之外,我们还将推理得到的对话状态用于下游的 act prediction 和对话生成上,下游任务的模型我们采用的是 [Chen et al., 2019] Wenhu Chen, Jianshu Chen, Pengda Qin, Xifeng Yan, and William Yang Wang. Semantically conditioned dialog response generation via hierarchical disentangled self-attention. In ACL, 2019。
从实验结果可以看出,相对于没有对话状态,通过 DSI-GM 得到的对话状态对下游任务有明显的提升,而相比于人工标注的对话状态还有一定的差距,这也体现了我们的这个任务还有较大的提升空间。
我们分析了多个不同的领域的结果,通过将结果最好的领域 attraction 和结果最差的领域 hotel 对比,我们发现不同领域中 slot 的数量对结果有直接的影响,slot 的数量较少的领域更容易进行推理是比较显然的,但是如何对不同的领域进行建模是未来值得考虑的问题。

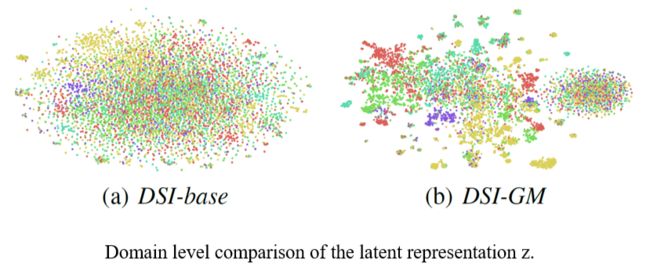
除此之外,我们还就 DSI-base 和 DSI-GM 在隐变量 z 上的表现进行了进一步的分析,我们通过 t-SNE 来对 z 进行了降维,图中每一种颜色代表一个领域,从图中可以看出,DSI-GM 在对不同领域的区分上确实取得了更好的效果,这也进一步证明了我们的高斯混合模型的作用。

结论
我们提出了一个新的任务:对话状态推理(dialogue state induction,DSI),目标是从无标注的对话记录中自动推理得到对话状态。
我们提出了两个基于神经隐变量的模型通过无监督的方式来对对话状态进行自动推理。
我们提出的任务针对了当前任务型对话研究中面临的非常实际的标注困难的问题,我们的提出的任务是一个比较有前景同时很有挑战性的任务。
一方面,我们在 IJCAI 的 review 也说到了:“This problem is important and interesting, this area should attract more attention. This work has great potential of motivating follow-up research.”,证明我们的这个工作的意义,是有利于促进后续的研究工作的。
另一方面,由对话状态本身的复杂性到无监督的任务设定使得这个任务还是有非常大的提升空间,我们提出的两个基于神经隐变量的模型也是抛砖引玉,提供了一种解决这个任务的思路,大家可以以我们的模型作为 baseline,提出更多的方法来解决这个任务。
更多阅读


#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
